DB-GPT
DB-GPT 是一个使用本地大模型(或在线 API)与数据交互的开源项目,Demo 中使用 ChatGPT 3.5 的接口,效果很吸引人。
让我们以 通义千问 为例,试试使用国产大模型在 DB-GPT 中能否达到类似的效果。
通义千问 API
要通过 API 使用通义千问模型,需要在阿里云灵积模型服务中 开通DashScope并创建API-KEY,获得 sk-xxxxx 格式的 API-KEY。
开通后会获得通义千问 qwen-turbo 和 qwen-plus 两个模型 的调用权限和有效期为 180 天的 200w/100w token 数的 免费额度:


API-KEY 的调用量可在 调用统计 中查看。
DB-GPT 使用通义千问 API 环境搭建
使用 源码安装 方式搭建 DB-GPT v0.4.0 版本运行环境,先下载源码:
$ git clone https://github.com/eosphoros-ai/DB-GPT.git
$ cd DB-GPT
$ git checkout v0.4.0之后安装依赖:
# python>=3.10
$ conda create -n dbgpt_env python=3.10
$ conda activate dbgpt_env
# it will take some minutes
$ pip install -e ".[default]"使用模板创建环境变量文件:
cp .env.template .env修改 .env 配置文件中如下内容,以使用通义千问 API:
LLM_MODEL=tongyi_proxyllm
# qwen-turbo or qwen-plus
PROXYLLM_BACKEND=qwen-turbo
LANGUAGE=zh
TONGYI_PROXY_API_KEY=sk-xxxxxxxxx下载 Embedding 模型:
$ mkdir models && cd models
#### embedding model
$ git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese
# or
# git clone https://huggingface.co/moka-ai/m3e-large
# back to DB-GPT root folder
$ cd ..之后启动 DB-GPT 服务:
python pilot/server/dbgpt_server.py --port 5050使用在线 API,无需本地 GPU。启动成功后,浏览器访问 http://localhost:5050 即可使用 DB-GPT 与通义千问接口对话:
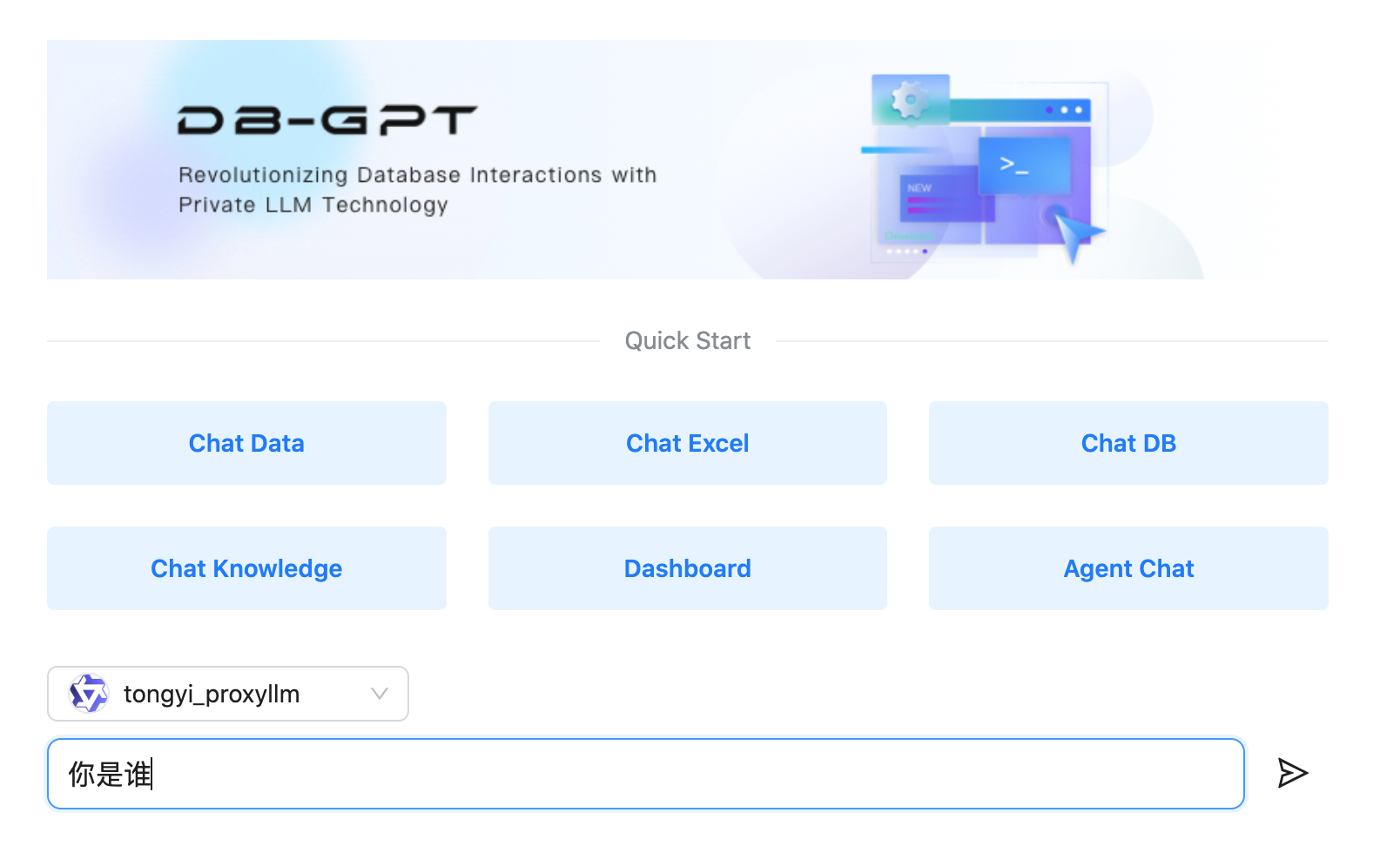
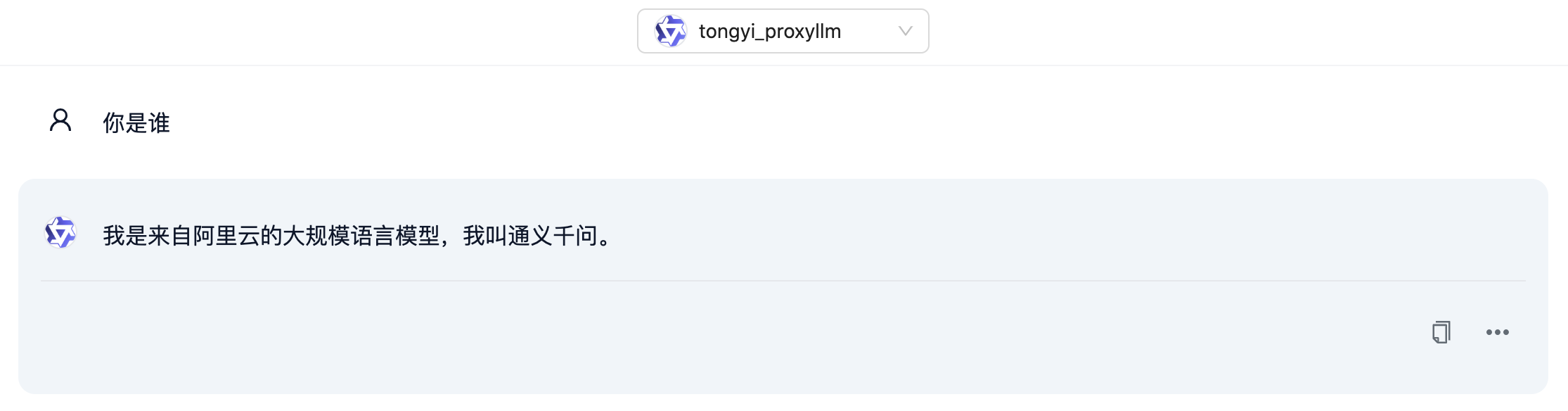
Chat Excel
接下来让我们试试 Chat Excel 功能。进入 Chat Excel 场景后,需要先上传一个 Excel 或 CSV 文件。使用演示中的 example.xlsx:

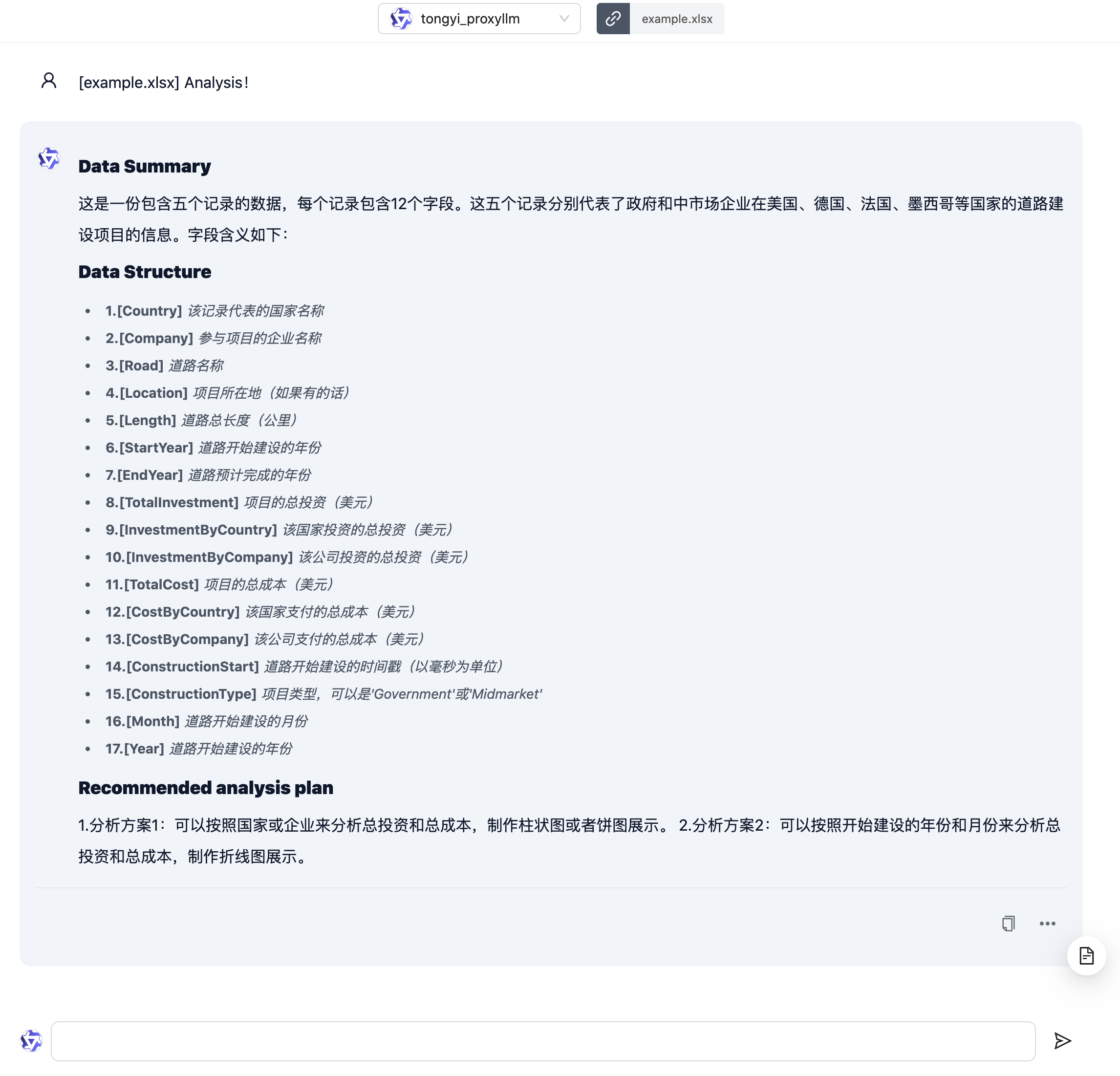
可以看到通义千问基本分析出了上传文件中的数据内容,但有一些小的瑕疵,如字段数量,数据结构中包含不存在的字段等。
问题
继续对话,你会发现无论问什么,得到的回复都是 InvalidParameter:User and assistant need to appear alternately in the message 报错信息。
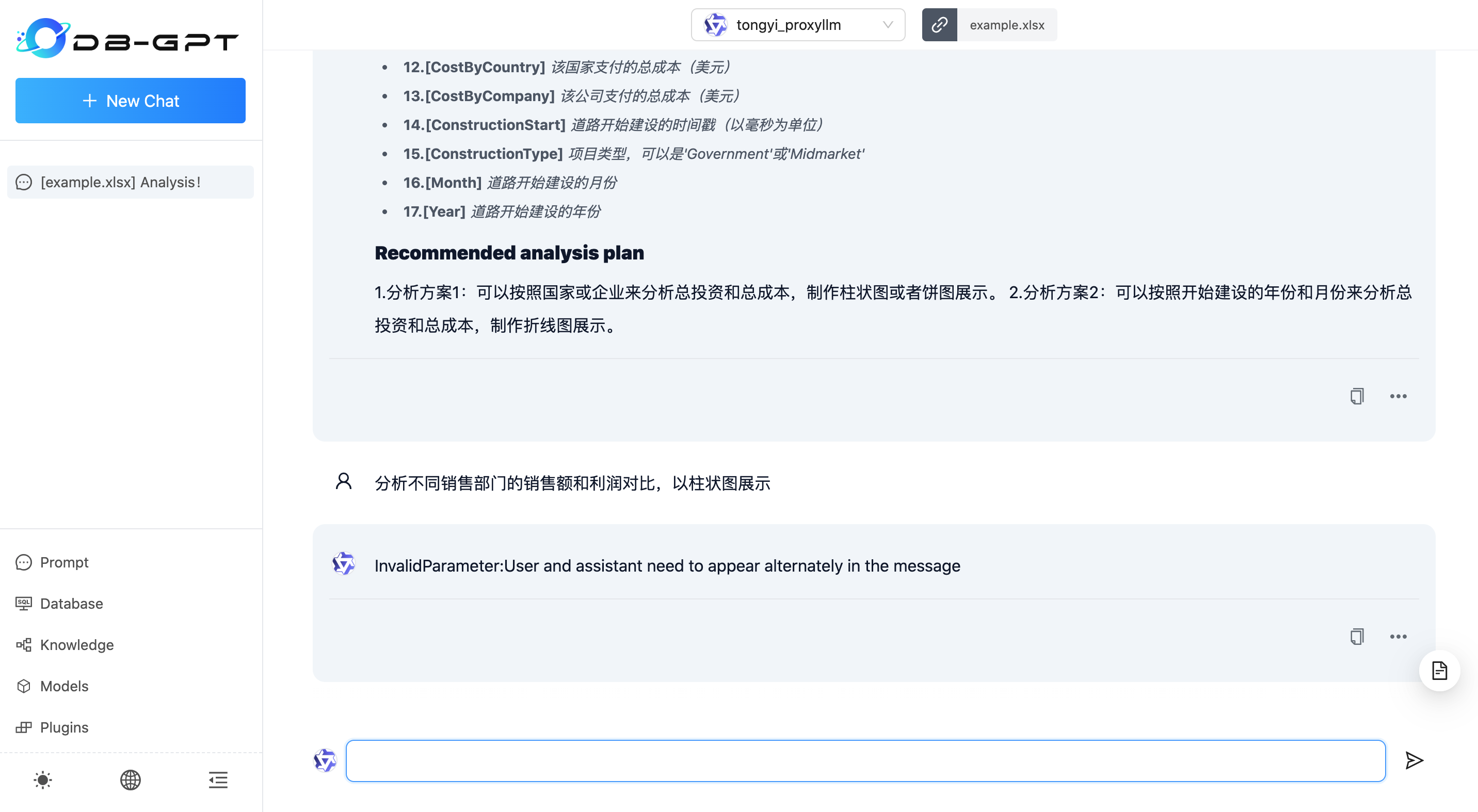
我创建了一个 Issue #756 描述了这个现象,此问题将会在 0.4.1 版本中修正。
修正方法
如果希望在本地先临时修正这个问题,可以参照下面的修改方式:
diff --git a/pilot/model/proxy/llms/tongyi.py b/pilot/model/proxy/llms/tongyi.py
index fb826e49..13031e96 100644
--- a/pilot/model/proxy/llms/tongyi.py
+++ b/pilot/model/proxy/llms/tongyi.py
@@ -36,7 +36,7 @@ def tongyi_generate_stream(
if message.role == ModelMessageRoleType.HUMAN:
history.append({"role": "user", "content": message.content})
for message in messages:
- if message.role == ModelMessageRoleType.SYSTEM:
+ if message.role == ModelMessageRoleType.SYSTEM or message.role == ModelMessageRoleType.HUMAN:
history.append({"role": "user", "content": message.content})
# elif message.role == ModelMessageRoleType.HUMAN:
# history.append({"role": "user", "content": message.content})
@@ -45,17 +45,24 @@ def tongyi_generate_stream(
else:
pass
- # temp_his = history[::-1]
- temp_his = history
+ temp_his = history[::-1]
last_user_input = None
for m in temp_his:
if m["role"] == "user":
last_user_input = m
break
- if last_user_input:
+ temp_his = history
+ prompt_input = None
+ for m in temp_his:
+ if m["role"] == "user":
+ prompt_input = m
+ break
+
+ if last_user_input and prompt_input and last_user_input != prompt_input:
history.remove(last_user_input)
- history.append(last_user_input)
+ history.remove(prompt_input)
+ history.append(prompt_input)
gen = Generation()
res = gen.call(报错的原因是通义千问 API 在对话时,需要 user 和 assistant 两个角色交替进行,且 user 先发言。而在 tongyi.py 中,传递给 LLM Server 的 messages 是将对话历史中的 human 角色内容过滤,system 提示词部分作为 user 角色内容移至末尾,导致 assistant 先于 user 发言了,如:
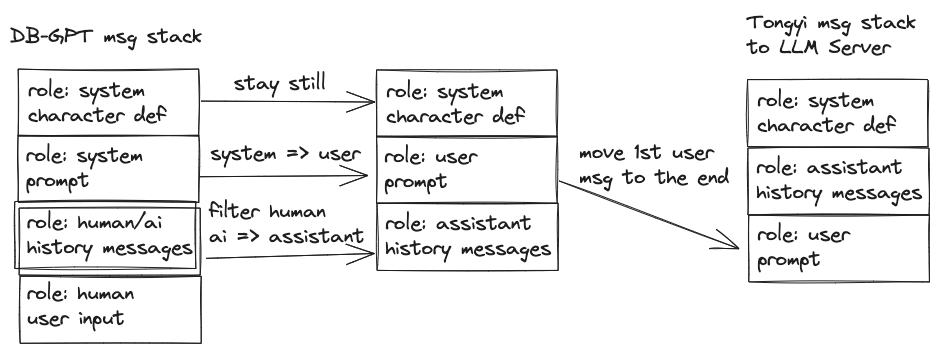
上面的修改方法将消息栈的转换方式变更为保留 human 角色信息,将除第一个 system 角色信息保留外,其余 system 和 human 角色信息修改为 user 角色,ai 角色修改为 assistant 角色,之后移除最后一条 user 消息,并将第一条 user 消息(根据用户最后输入的信息,使用场景的提示词模板生成的提示词)移至消息栈的末尾。
效果
看下修改之后的效果吧:
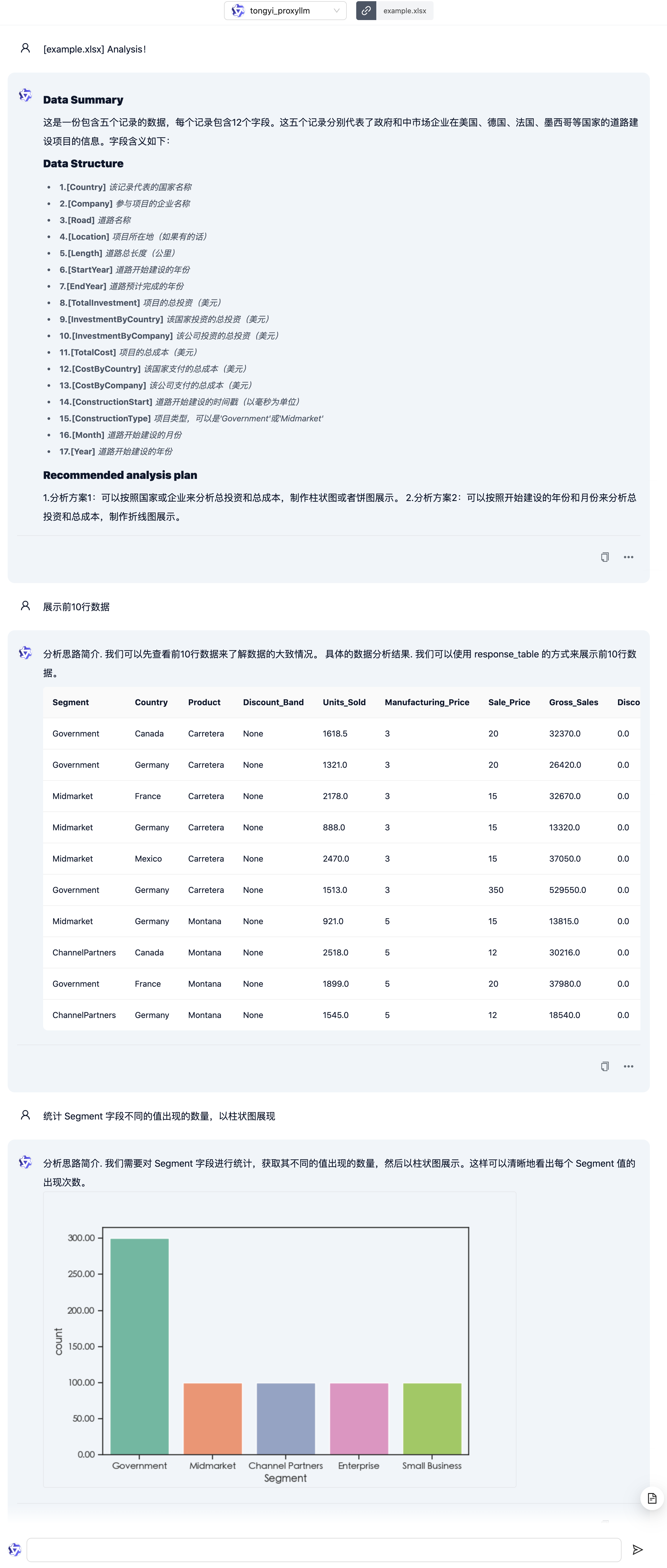
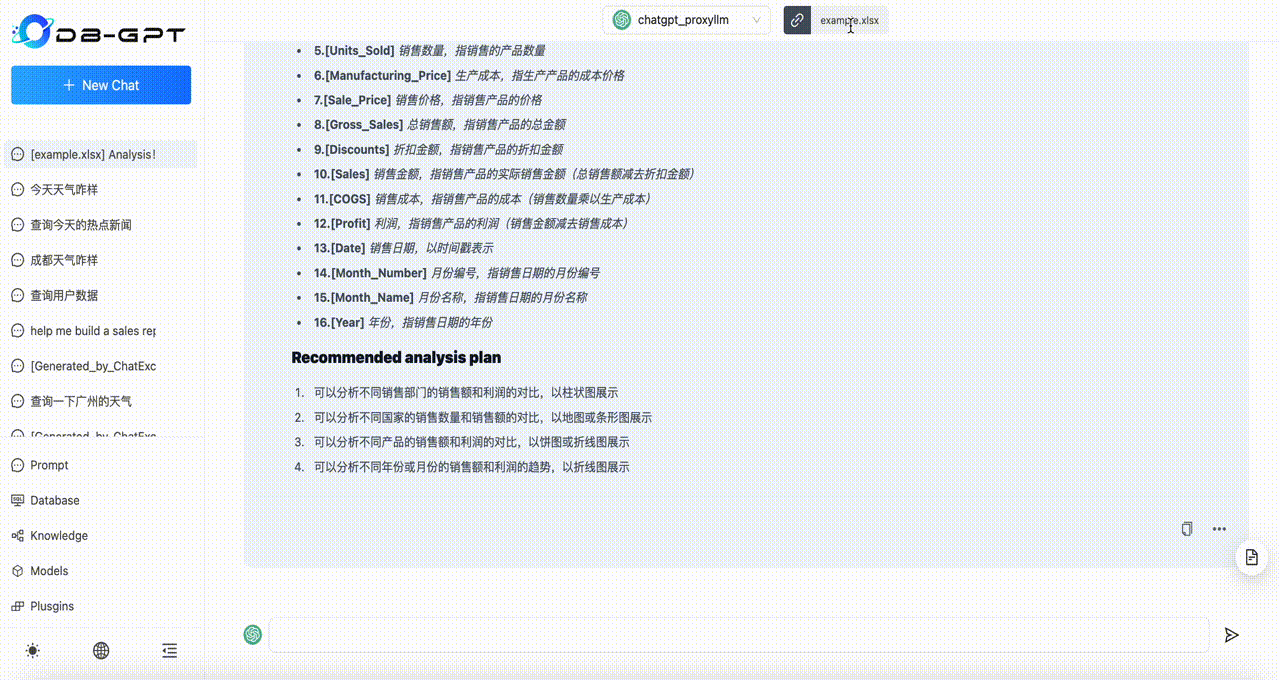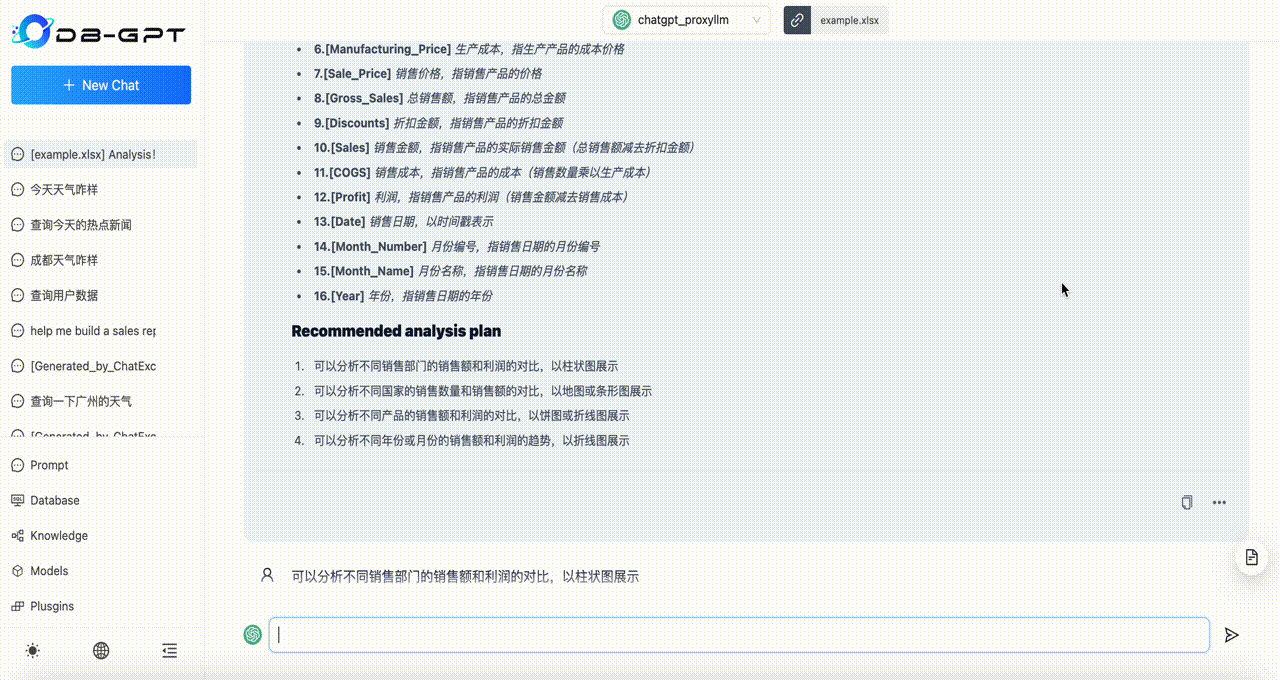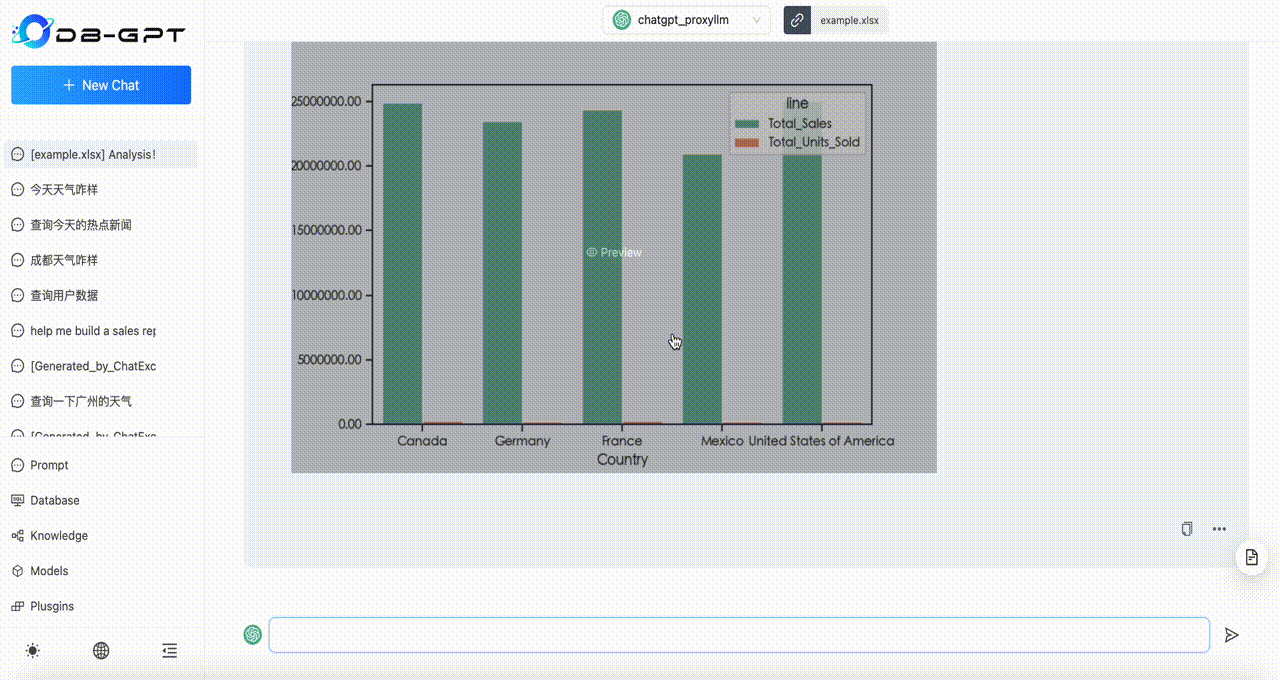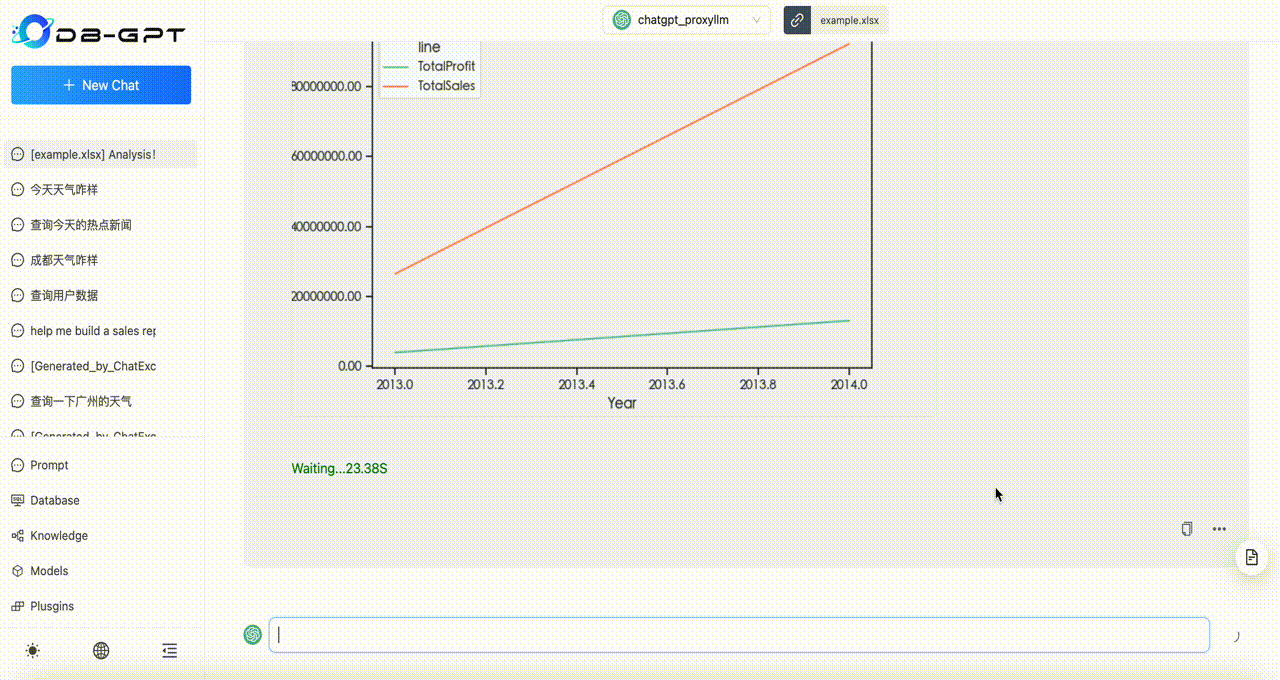
在 WPS 中查看统计数据,与柱状图中信息一致:
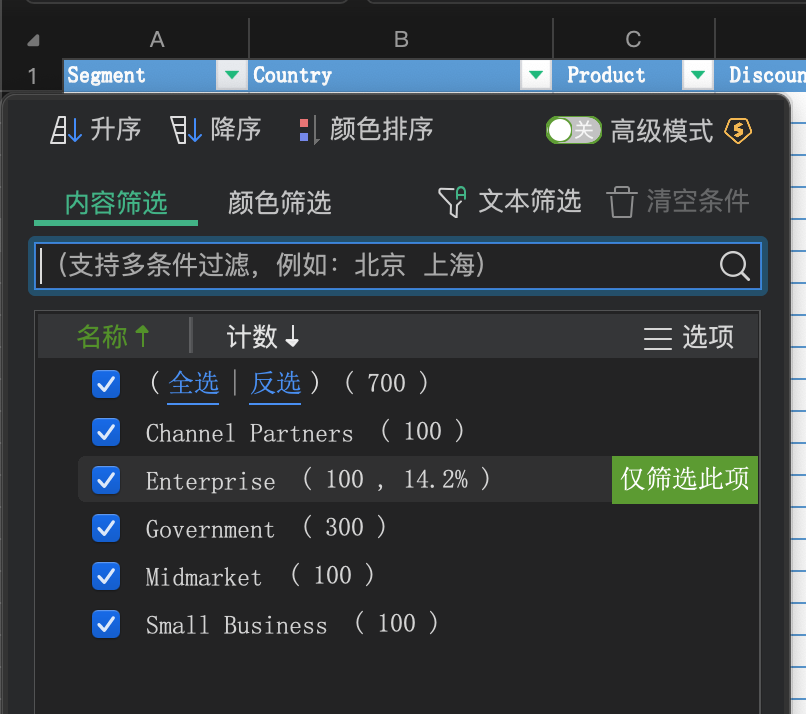
不过遗憾的是,使用 demo 中的对话内容 —— 分析不同销售部门的销售额和利润对比,以柱状图展示,通义千问还是得不到 ChatGPT 3.5 的效果:

