Arthur Bench 简介
Arthur Bench 是一个评估大模型的开源工具。
使用 Arthur Bench 评估 LLM,需编写少量代码,即测试套件(TestSuite),在套件中选择内置评分方法(也可自定义评分方法),对 LLM 的相应内容进行评估打分。
内置的评分方法 分为四类:
- 基于提示词评分,如问答正确性(
qa_correctness)、摘要质量(summary_quality)、是否存在幻觉(hallucination); - 基于 Embedding 评分,如(
bertscore)、(hedging_language); - 基于词汇评分,如(
exact_match)、(readability)、(specificity)、(word_count_match); - 代码生成能力评分,如使用 Python 单元测试(
python_unit_testing)验证生成代码正确性。
各类评分方法需要的入参包括以下五类:
- Input:输入的问题
- Reference Output:参考(标准)答案
- Candidate Output:LLM 输出的答案
- Context:上下文
- Unit Tests:单元测试
各类评分方法需要的入参详见官方文档中的 Scoring。
使用 Arthur Bench 评估本地领域模型
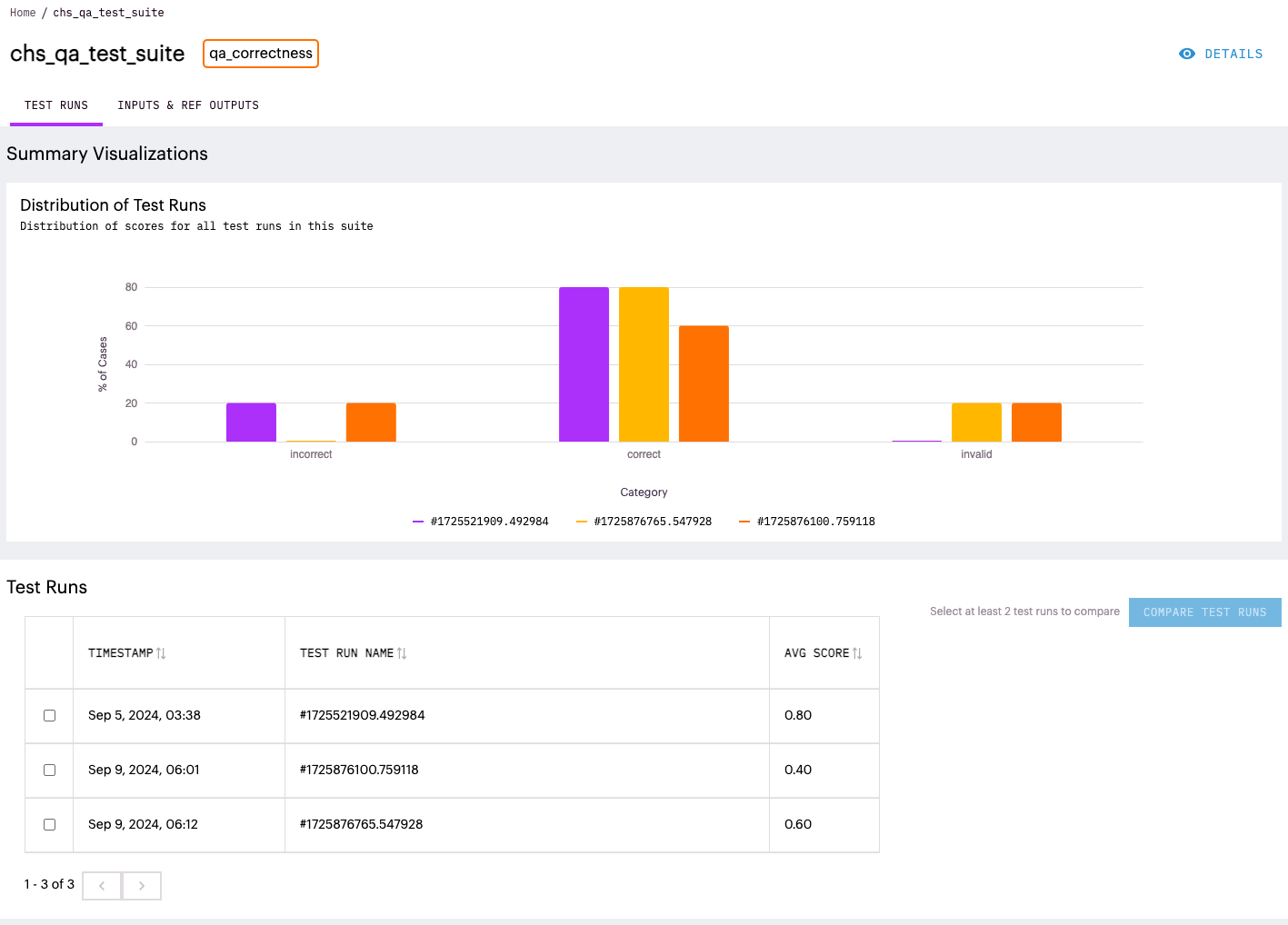
本文采用 LLM 自我评估的方式,使用本地 LLM 同时作为领域模型和评估模型,基于 qa_correctness 评分方法打分,整体流程如下:
- 将准备好的领域知识问题通过 LangChain 输入给本地领域大模型,获得大模型的回复;
- 将领域大模型回复的内容,与准备好的标准答案,以提示词形式输入给本地评估大模型,将领域大模型的回答内容分类为
正确、错误、不确定三类; - 通过评分方法,为领域大模型的回复情况打分。
实现方案
docker 环境准备
在 docker 环境中完成上述过程。
先拉取 python 镜像:
docker pull python:3.10.14python 3.9 中安装
bench好像报错,需要 python 3.10
启动并进入容器:
docker run -it --name bench -p 8088:8000 python:3.10.14 bash容器中安装 Arthur Bench:
pip install 'arthur-bench[server]'内网环境可使用内部源安装,如:
pip install 'arthur-bench[server]' -i http://192.168.131.211:8083/pypi/web/simple/ --trusted-host 192.168.131.211
修改源码
以当前最新发布版 0.3.1 为例,需要修改一些源码,以适应本地离线环境容器内使用。
避免 Tiktoken 对外网的访问
0.3.1 版本在执行测试套件时,即使使用的评分方法(Scoring method)不是 summary_quality,也会执行其中的方法,造成对 tiktoken 相关 host 的访问,离线环境会报如下错误:
requests.exceptions.ConnectionError: HTTPSConnectionPool(host='openaipublic.blob.core.windows.net', port=443): Max retries exceeded with url: /encodings/cl100k_base.tiktoken (Caused by NameResolutionError("<urllib3.connection.HTTPSConnection object at 0x7f23efb00820>: Failedto resolve 'openaipublic.blob.core.windows.net' ([Errno -3] Temporary failure in name resolution)"))可对 /usr/local/lib/python3.10/site-packages/arthur_bench/scoring/summary_quality.py 做如下修改,暂时跳过:
diff --git a/arthur_bench/scoring/summary_quality.py b/arthur_bench/scoring/summary_quality.py
index 71e0ff4..1793e72 100644
--- a/arthur_bench/scoring/summary_quality.py
+++ b/arthur_bench/scoring/summary_quality.py
@@ -21,7 +21,8 @@ CONTEXT_WINDOW_MAP = {
"gpt-4-32k": 32768,
}
EVALUATOR_MODEL = "gpt-3.5-turbo"
-TIKTOKEN_ENCODER = tiktoken.get_encoding("cl100k_base")
+# TIKTOKEN_ENCODER = tiktoken.get_encoding("cl100k_base")
+TIKTOKEN_ENCODER = None
TIKTOKEN_ERROR_PADDING = 150
LLM_CHOICE_TO_FLOAT = {"0": 0.0, "1": 1.0, "tie": 0.5}
LLM_CHOICE_TO_CATEGORIES = {或直接使用 sed 命令修改:
sed -i \
's/.*TIKTOKEN_ENCODER = tiktoken.get_encoding("cl100k_base")/TIKTOKEN_ENCODER = None/g' \
/usr/local/lib/python3.10/site-packages/arthur_bench/scoring/summary_quality.py使测试套件可使用本地评估模型重复执行
本文示例中,评分方法使用的是 qa_correctness,并且将评估模型也替换成了本地的 LLM。为使测试套件可多次执行,需修改 /usr/local/lib/python3.10/site-packages/arthur_bench/scoring/qa_quality.py 中的 QAQualityCorrectness 初始化方法:
diff --git a/arthur_bench/scoring/qa_quality.py b/arthur_bench/scoring/qa_quality.py
index e8389f8..e669f2e 100644
--- a/arthur_bench/scoring/qa_quality.py
+++ b/arthur_bench/scoring/qa_quality.py
@@ -29,6 +29,8 @@ class QAQualityCorrectness(Scorer):
"Custom LLM is allowed, but unexpected results may occur if it is not a"
" chat model"
)
+ if isinstance(llm, dict):
+ llm = ChatOpenAI(**llm)
self.evaluator = LLMChain(llm=llm, prompt=DECIDE)
@staticmethod或直接使用 sed 命令修改:
sed -i \
'/self.evaluator = LLMChain(llm=llm, prompt=DECIDE)/i \
if isinstance(llm, dict):\
llm = ChatOpenAI(**llm)' \
/usr/local/lib/python3.10/site-packages/arthur_bench/scoring/qa_quality.py使 HTTP 服务可从外部访问
修改 /usr/local/lib/python3.10/site-packages/arthur_bench/server/run_server.py 中的 host 为 0.0.0.0:
diff --git a/arthur_bench/server/run_server.py b/arthur_bench/server/run_server.py
index 9346ef4..3a67ebf 100644
--- a/arthur_bench/server/run_server.py
+++ b/arthur_bench/server/run_server.py
@@ -231,7 +231,7 @@ def run():
uvicorn.run(
"arthur_bench.server.run_server:app",
- host="127.0.0.1",
+ host="0.0.0.0",
port=8000,
log_level="info",
)或直接使用 sed 命令修改:
sed -i 's/host="127.0.0.1",/host="0.0.0.0",/g' /usr/local/lib/python3.10/site-packages/arthur_bench/server/run_server.py数据准备
以 高效办成一件事,全国医保经办系统练兵比武大赛 中的部分题目为例,作为 QA 数据考察本地领域模型能力,将题目和参考答案整理成 csv 格式:
$ cat > qa_test_data.csv <<EOF
input,reference_output
医保亲情账户是指什么?有什么功能?,医保亲情账户是指国家医保局为了方便老人、小孩等申领医保电子凭证,在国家医保服务APP上推出的一项便民功能。亲情账户可以帮助家庭成员出示医保电子凭证用于挂号、买药、结算。
个账家庭共济是指什么?,个账家庭共济是指职工医保个人账户余额共济给家庭成员使用,支付个人负担的医药费用,或代缴家庭成员的城乡居民医保费。
"""两病""患者门诊用药保障机制中的""两病""指的是哪两个病种?","""两病""是指高血压、糖尿病。"
"请简述""两病""患者门诊用药保障机制明确的用药范围。",按最新版国家基本医疗保险药品目录所列品种,优先选用目录甲类药品,优先选用国家基本药物,优先选用通过一致性评价的品种,优先选用集中招标采购中选药品。
【多选】根据《医疗保障基金使用监督管理条例》(国务院令 第735号),参保人员不得利用其享受医疗保障待遇的机会()A.转卖药品 B.接受返还现金 C.接受实物 D.获得其他非法利益,答案:ABCD
EOF编写测试套件代码并执行
参考官方文档中,对接本地大模型的 Compare LLM Providers 和使用 csv 数据文件的 Creating test suites,编写测试套件代码如下:
$ cat > qa_test_suite.py <<EOF
import time
import pandas as pd
from arthur_bench.scoring import QAQualityCorrectness
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from arthur_bench.run.testsuite import TestSuite
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(
temperature=0.5,
openai_api_base='http://192.168.174.64:19131/v1',
openai_api_key='api_key',
model_name='qwen1.5-72b-chat'
)
data = pd.read_csv('qa_test_data.csv')
# 问题列
input_data = data['input']
# 参考答案列
reference_data = data['reference_output']
# 使用 apply 函数组合 'input' 列和 'reference_output' 列的数据作为 context 数据,即提供问题和答案,供 LLM 对生成的问题答案进行评价
context_data = [i for i in data.apply(lambda row: row['input']+row['reference_output'], axis=1)]
# 定义提示模板
prompt_template = PromptTemplate(
input_variables=["text"],
template="""{text}"""
)
# 创建链
chain = LLMChain(
llm=llm,
prompt=prompt_template
)
# 调用链
responses = [chain.run(i) for i in input_data]
my_suite = TestSuite(
"chs_qa_test_suite",
scoring_method=QAQualityCorrectness(llm),
input_text_list=input_data,
)
my_suite.run(
f"#{time.time()}",
context_list=context_data,
candidate_output_list=responses
)
EOF执行测试套件:
$ python qa_test_suite.py
Custom LLM is allowed, but unexpected results may occur if it is not a chat model
25it [00:06, 3.75it/s]如需多次执行测试套件,需在首次执行之后,修改 ./bench_runs/<test_suite_name> 下的 suite.json,将其中 scoring_method 的
"config": {}修改为需要用来执行评估的本地模型,如:
"config": {"llm": {"temperature": 0.0, "openai_api_base": "http://192.168.174.64:19131/v1", "openai_api_key": "your_openai_api_key", "model_name": "qwen1.5-72b-chat"}}或直接使用 sed 命令修改:
sed -i \
's/"config": {}/"config": {"llm": {"temperature": 0.5, "openai_api_base": "http:\/\/192.168.174.64:19131\/v1", "openai_api_key": "your_openai_api_key", "model_name": "qwen1.5-72b-chat"}}/g' \
./bench_runs/chs_qa_test_suite/suite.json查看测试结果
启动容器时,将容器内的 8000 端口映射到了宿主机的 8088 端口,所以可以直接在宿主机访问 http://localhost:8088 进入 bench web UI 查看测试结果。