MindIE Benchmark
MindIE Benchmark 是 昇腾推理引擎(MindIE,Mind Inference Engine)中推理服务组件 MindIE Service 组件包含的性能测试套件,提供测试大语言模型在不同配置参数下推理性能和精度的能力。
详细信息可参见官方文档 MindIE Benchmark 1.0.0 功能介绍。
MindIE Benchmark 支持 Client 和 Engine 两种不同的推理模式:
- Client 模式调用 MindIE Client 的 .generate() 和 .generate_stream() 接口,对应 MindIE Server 的 兼容Triton的文本推理接口 和 兼容Triton的流式推理接口。适用于模拟多用户并发场景,主要用于测量服务化性能。Client测量的吞吐量为用户真实感知的吞吐量,其计入包括网络请求和数据处理等消耗的时间。
- Engine 模式直接调用底层 API,并将 NPU 推理返回的结果暂存,当所有推理完成后再由 CPU 处理暂存的数据,其测量的吞吐量更接近 NPU 卡的真实性能。
Client 推理模式样例
- 文本非流式推理
benchmark \
--DatasetPath "/{数据集路径}/GSM8K" \
--DatasetType "gsm8k" \
--ModelName llama_7b \
--ModelPath "/{模型权重路径}/llama_7b" \
--TestType client \
--Http https://{ipAddress}:{port} \
--ManagementHttp https://{managementIpAddress}:{managementPort} \
--Concurrency 128 \
--TaskKind text \
--Tokenizer True \
--MaxOutputLen 512- 文本流式推理
benchmark \
--DatasetPath "/{数据集路径}/GSM8K" \
--DatasetType "gsm8k" \
--ModelName llama_7b \
--ModelPath "/{模型权重路径}/llama_7b" \
--TestType client \
--Http https://{ipAddress}:{port} \
--ManagementHttp https://{managementIpAddress}:{managementPort} \
--Concurrency 128 \
--TaskKind stream \
--Tokenizer True \
--MaxOutputLen 512Engine 推理模式样例
- 文本推理模式
# Engine模式 文本推理
benchmark \
--DatasetPath "/{数据集路径}/GSM8K" \
--DatasetType gsm8k \
--ModelName baichuan2_13b \
--ModelPath "/{模型权重路径}/baichuan2-13b" \
--TestType engine \
--MaxOutputLen 512 \
--Tokenizer True测试数据集
支持的数据集以及数据集获取链接,可在 MindIE 镜像中获取,以 1.0.0 版本为例,镜像中 /usr/local/Ascend/atb-models/tests/modeltest/README_NEW.md 文档包含支持数据集相关信息如下:
| 支持数据集 | 下载地址 |
|---|---|
| BoolQ | dev.jsonl |
| CEval | ceval-exam |
| CMMLU | cmmlu |
| HumanEval | humaneval |
| HumanEval_X | cpp java go js python |
| GSM8K | gsm8k |
| LongBench | longbench |
| MMLU | mmlu |
| NeedleBench | PaulGrahamEssays multi_needle_reasoning_en multi_needle_reasoning_zh names needles zh_finance zh_game zh_general zh_government zh_movie zh_tech |
| TextVQA | train_val_images.zip textvqa_val.jsonl textvqa_val_annotations.json |
| VideoBench | Eval_QA/ Video-Bench |
| VocalSound | VocalSound 16kHz Version |
| TruthfulQA | truthfulqa |
实测数据
环境准备
以使用 swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:1.0.0-800I-A2-py311-openeuler24.03-lts 镜像和 GSM8K 数据集为例(测试数据集在 /data 路径下):
# 启动容器
docker run -it -d --net=host --shm-size=1800g \
--name=mindie-bench \
--privileged \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device=/dev/devmm_svm \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /usr/local/sbin:/usr/local/sbin:ro \
-v /etc/hccn.conf:/etc/hccn.conf \
-v /data:/data:rw \
swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:1.0.0-800I-A2-py311-openeuler24.03-lts bash# 进入容器
docker exec -it mindie-bench bash# 修改 benchmark 中 config.json 文件权限
chmod 640 /usr/local/lib/python3.11/site-packages/mindiebenchmark/config/config.jsonClient 模式非流式推理性能测试
# Client 模式非流式 128 并发数执行性能测试
nohup benchmark \
--DatasetPath "/data/test.jsonl" \
--DatasetType "gsm8k" \
--ModelName llama_7b \
--ModelPath "/{模型权重路径}/llama_7b" \
--TestType client \
--Http https://{ipAddress}:{port} \
--ManagementHttp https://{managementIpAddress}:{managementPort} \
--Concurrency 128 \
--TaskKind text \
--Tokenizer True \
--MaxOutputLen 2048 \
> /home/client_text_128.log 2>&1 &mindie 2.0 需要先设定
MINDIE_LOG_TO_STDOUT环境变量,否则日志中没有输出内容:export MINDIE_LOG_TO_STDOUT="benchmark:1; client:1"
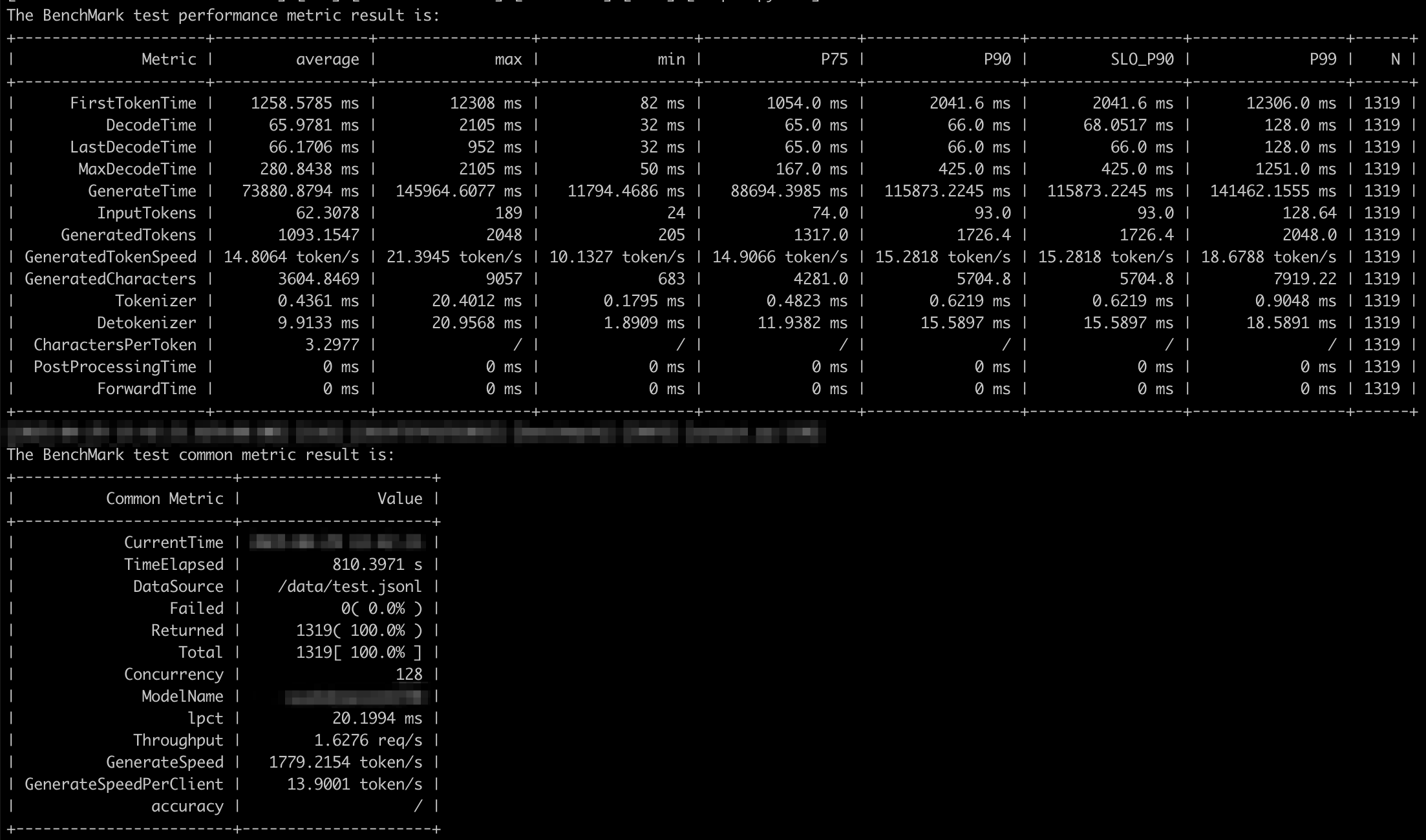
Client 模式流式推理性能测试
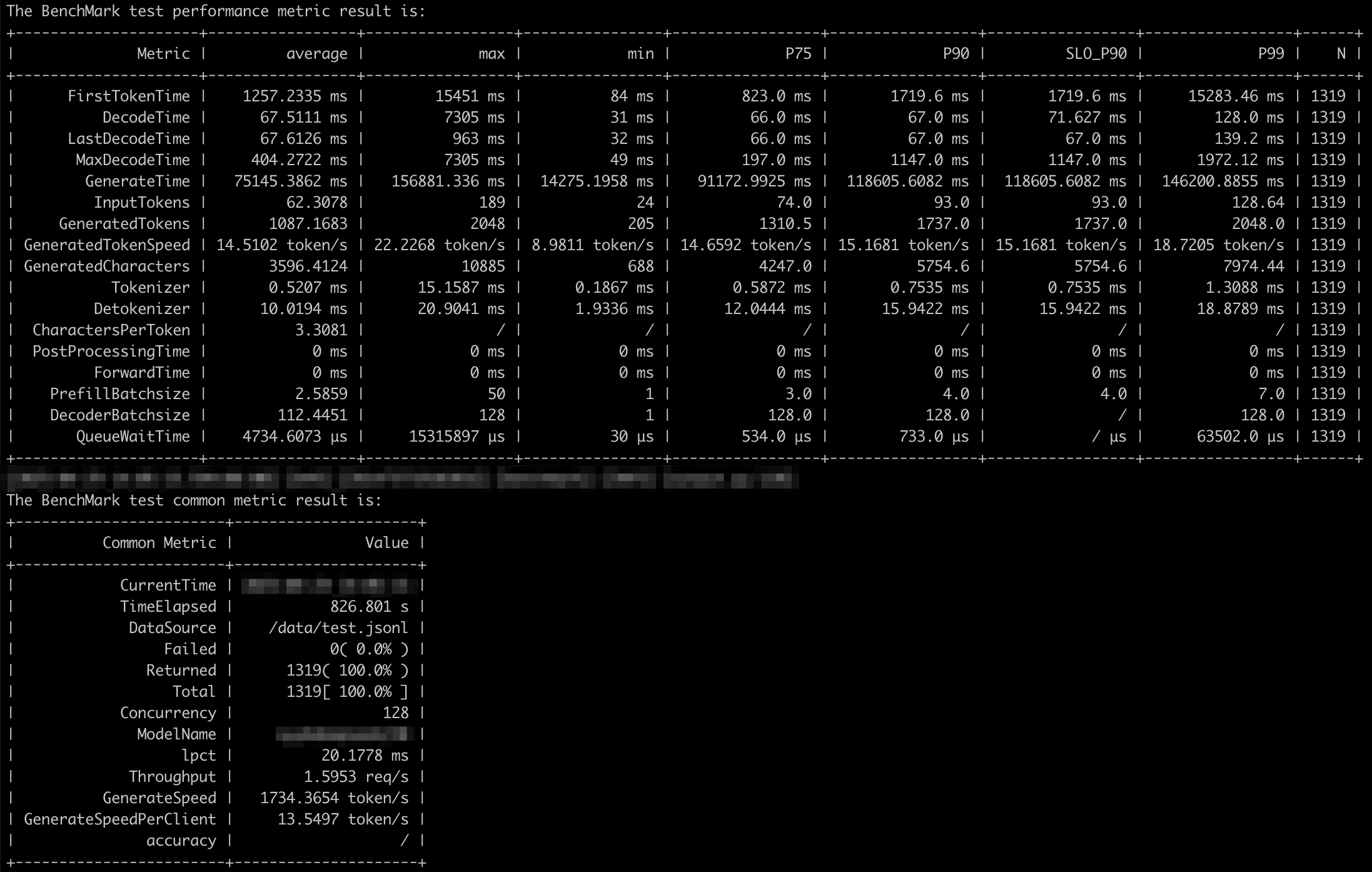
性能监控
MindIE Service 中提供了普罗米修斯格式的服务监控指标查询接口:GET: http(s)://{ip}:{port}/metrics。
- {ip}字段优先读取环境变量值MIES_CONTAINER_MANAGEMENT_IP;如果没有该环境变量,则取配置文件的“managementIpAddress”参数;如果配置文件中没有“managementIpAddress”参数,则取配置文件的“ipAddress”参数。
- {port}字段读取配置文件的“metricsPort”参数。
如需使用该接口,请确保在启动服务前,开启服务化监控开关。开启服务化监控功能的命令如下:
export MIES_SERVICE_MONITOR_MODE=1接口详情可参考 服务监控指标查询接口(普罗格式)。
使用 Prometheus 存储和检索监控数据
使用 ARM 版镜像启动 Prometheus 服务:
# 拉取镜像
$ docker pull prom/prometheus-linux-arm64:v3.3.0
# 启动容器
$ docker run --name prometheus -d -p 9090:9090 \
-v /root/prometheus-conf:/etc/prometheus/ \
prom/prometheus-linux-arm64:v3.3.0Prometheus 配置 MindIE Metrics 端点地址时,需要添加 fallback_scrape_protocol: PrometheusText0.0.4:
# /root/prometheus-conf/prometheus.yml
...
scrape_configs:
...
- job_name: "mindie"
# set fallback_scrape_protocol to be compatible with mindie metrics API's response content type (application/json)
fallback_scrape_protocol: PrometheusText0.0.4
static_configs:
- targets: ["localhost:1027", "localhost:1028"]
labels:
app: "mindie"# 重启容器
docker restart prometheus更新配置重启容器后,可通过 http://localhost:9090 访问 Prometheus Web UI。
节点监控
普罗米修斯官方也提供了很多 Exporter 组件用于监控各类资源使用情况,如监控计算资源节点的 Node Exporter。同样可以通过官方镜像快速启动:
# 拉取镜像
$ docker pull prom/node-exporter:v1.9.1 --platform arm64
# 启动容器
$ docker run -d \
--net="host" \
--pid="host" \
-v "/:/host:ro,rslave" \
prom/node-exporter:v1.9.1 \
--path.rootfs=/hostnode_exporter 默认监听 HTTP 9100 端口。容器启动成功后,可添加到 Prometheus 配置文件中:
# /root/prometheus-conf/prometheus.yml
...
scrape_configs:
...
- job_name: "node"
static_configs:
- targets: ["localhost:9100"]
labels:
app: "node"包含 Node Exporter 和 MindIE Metrics 的完整配置文件可参考 prometheus.yml。
使用 Grafana 可视化监控数据
使用 ARM 版镜像启动 Grafana 服务:
# 拉取镜像
$ docker pull grafana/grafana:11.6.0 --platform arm64
# 启动容器
$ docker run -d --name=grafana -p 3000:3000 grafana/grafana:11.6.0容器启动成功后,访问 http://localhost:3000/ 可进入 Grafana Web UI。默认用户名和密码均为 admin,第一次登录会需要修改密码。
以下内容引自 MindIE服务化部署实现监控功能:
点击 Connection > Data sources > Add new data source,选择 prometheus,之后把 prometheus 的 URL http://localhost:9090/ 填上去,点击最下面 Save & test。
之后可以在 Grafana 页面建立 dashboard,在 Home > Dashboards > New dashboard 建立 dashboard, Dashboard 手动构建较麻烦,可以参考一些 Grafana教程 https://imageslr.com/2024/grafana.html。
好在可以通过 json 格式输入或 json 文件 import 快速构建 dashboard
这里选择参考下面 vllm 的 grafana json 文件,将其中的 vllm: 字段去掉(因为 MindIE 的 metrics 字段和 vllm 的 metric 有区别)
http://www.gitpp.com/digiman/vllm/-/blob/main/examples/production_monitoring/grafana.json?ref_type=heads
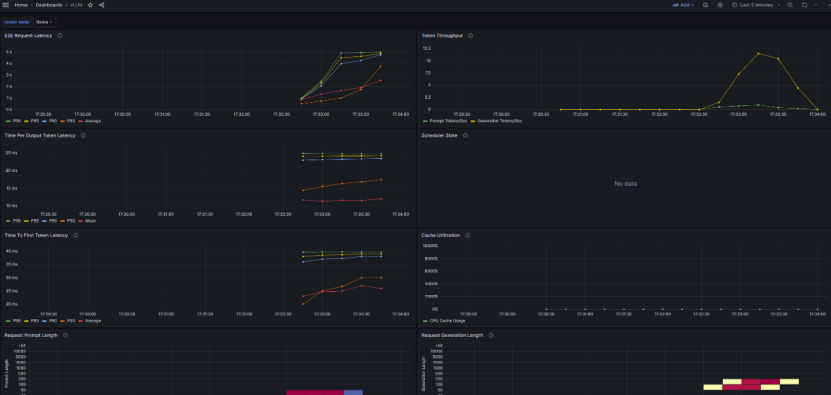
最终得到MindIE指标监控看板界面
MindIE Dashboard json 配置文件可参考 mindie-dashboard.json。
Node Exporter Dashboard json 配置文件可从 https://grafana.com/grafana/dashboards/16098-node-exporter-dashboard-20240520-job/ 下载,或直接使用 node-exporter-dashboard.json。
实测数据
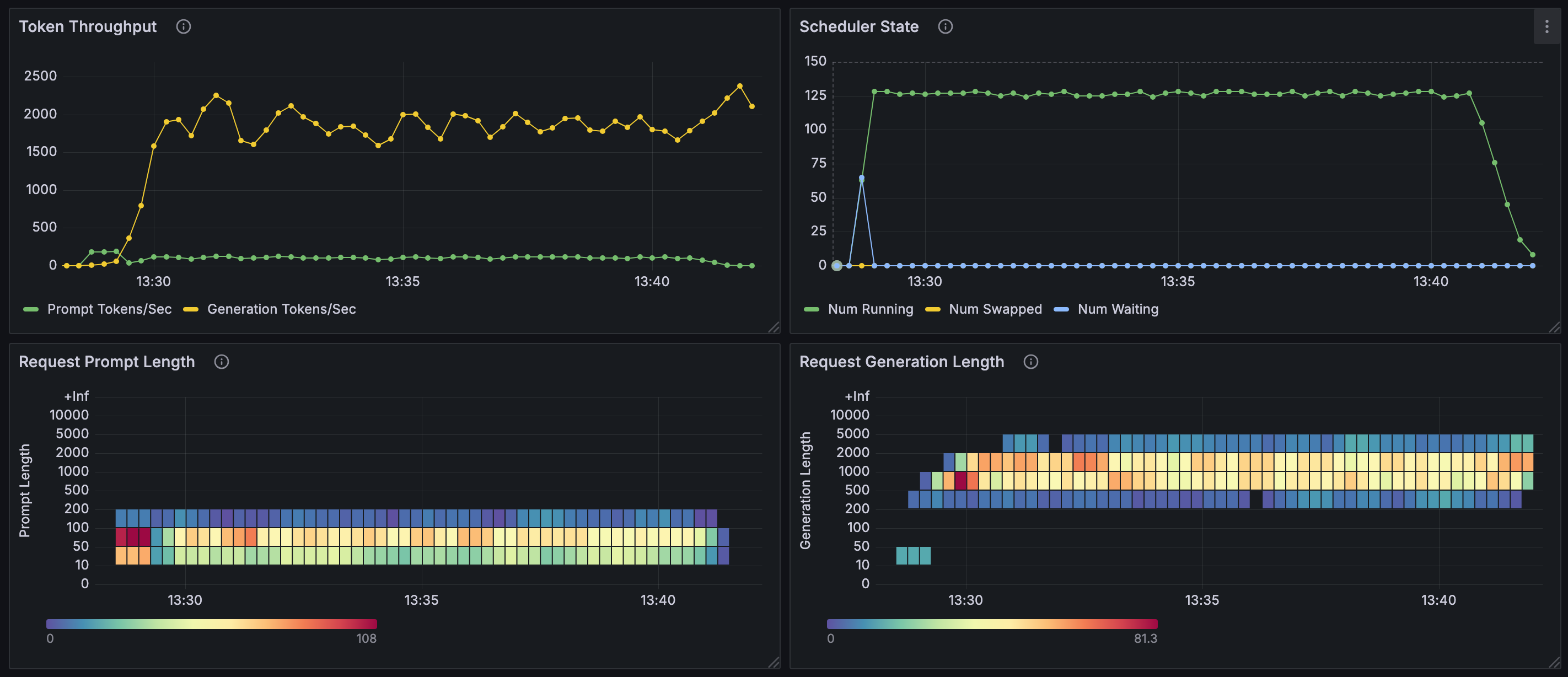
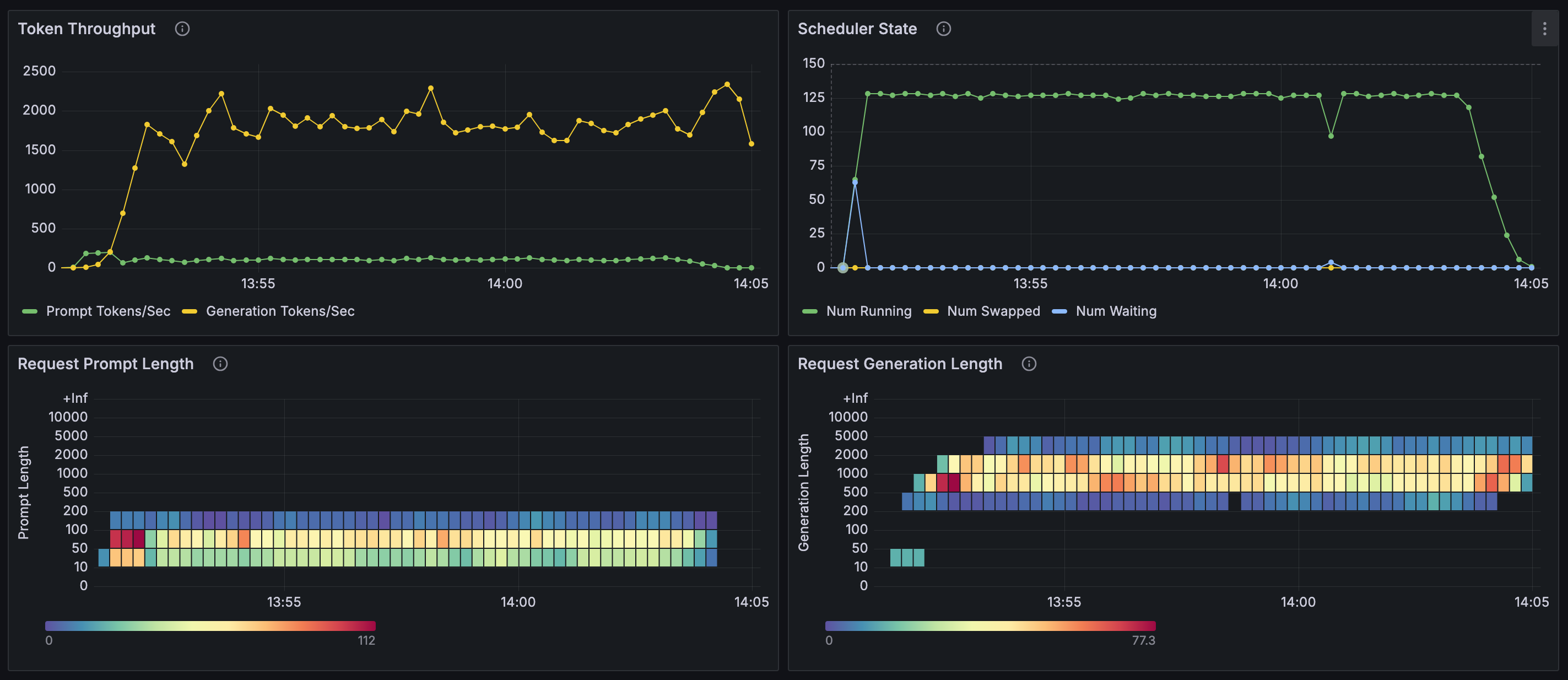
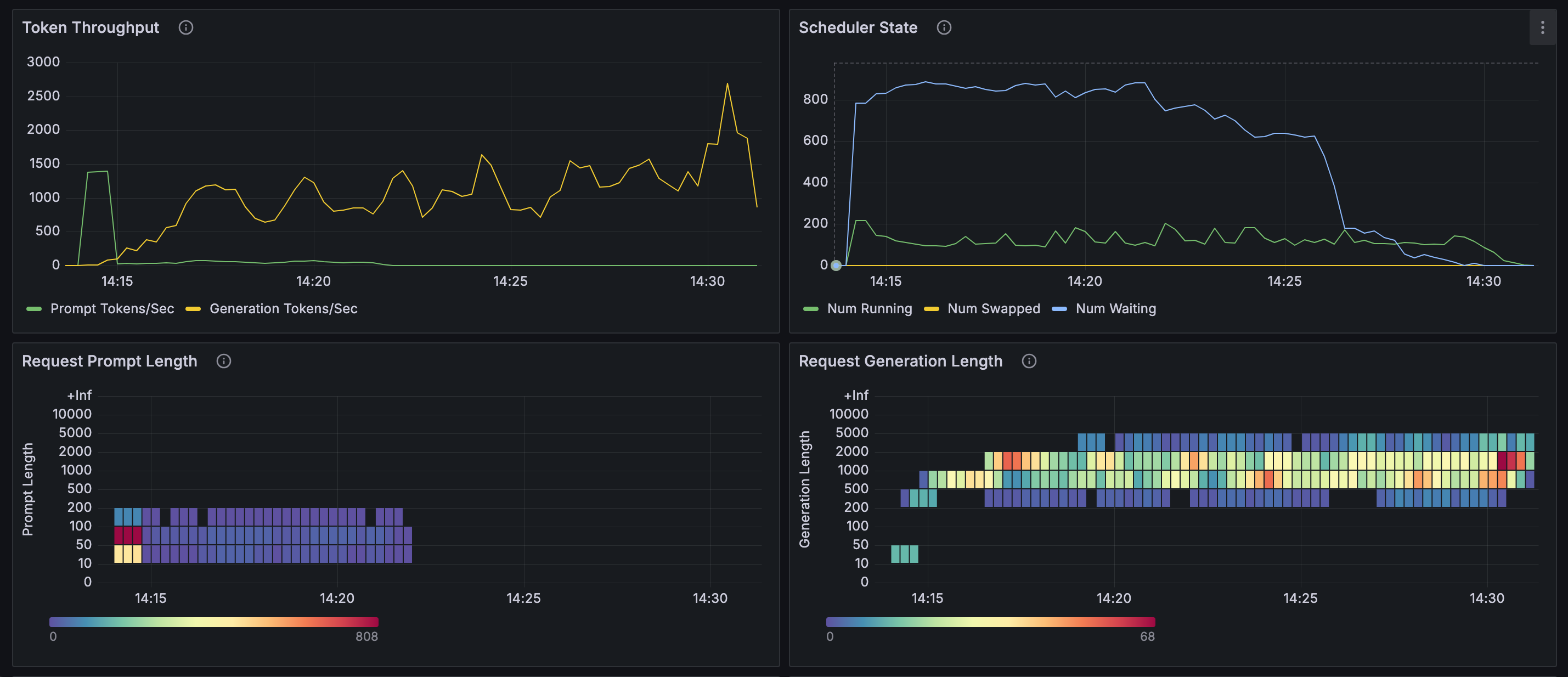
由上面的图表可知(使用 GSM8K 数据集):
- 128 并发进行推理时,流式及非流式推理性能差别不大:请求提示词 token 数在
10~200范围,响应 token 数在200~5000范围,并行推理数基本能够稳定在 128,等待推理的请求数基本为 0,每秒生成 token 数量在1500~2000左右。 - 1000 并发时:出现大量等待请求,并行推理数与等待请求数呈互补型波动,每秒生成 token 数也呈现出较大范围的波动。
每秒输出 token 总数,会受到输入 token 数、输出 token 数、并行推理数、等待请求数的影响:
- 输入输出 token 数越多,能够并行的推理数就会越少;
- 等待的请求数增多,并行推理数也会减少;
- 并行推理数下降,每秒输出的 token 总数就会下降;
- 并行推理数最大值,受限于 NPU 卡的性能和 maxBatchSize 配置参数及 TotalBlockNum 影响。计算 maxBatchSize 最大值,可参考 性能调优流程 文档;TotalBlockNum 值也可参照该文档,且可能会根据不同的输入输出 token 数而变化。
