TEI
TEI(Text Embeddings Inference)是 Hugging Face 提供的一个服务框架,用于部署和运行文本嵌入模型,以及序列分类模型(重排模型)。它支持多种模型格式,性能优异,并提供了 RESTful API 接口,方便与其他应用集成。
Benchmark for BAAI/bge-base-en-v1.5 on an Nvidia A10 with a sequence length of 512 tokens:

部署
CPU 环境部署
最新 1.7 版本 CPU 镜像可能存在某些模型无法启动问题,可能是 https://github.com/huggingface/text-embeddings-inference/issues/388 原因导致,使用 1.4 版本可以正常启动:
$ image=ghcr.io/huggingface/text-embeddings-inference:cpu-1.4
$ docker pull $image
$ model=/data/bge-large-zh-v1.5
# Set the models directory as the volume path
$ volume=/path/to/models
$ docker run -d --name tei-cpu -p 9090:80 -v $volume:/data $image --model-id $model启动时若遇
OS can't spawn worker thread: Operation not permitted (os error 1)报错,可添加--privileged参数:docker run --privileged -d --name tei-cpu -p 9090:80 -v $volume:/data $image --model-id $model
需要为模型设置 API KEY 时,可以在 docker 启动命令中设置环境变量参数
-e API_KEY=sk-xxx,或在命令最后添加--api-key sk-xxx启动参数。设置 API KEY 后,访问 TEI 接口时均需设置Authorization: Bearer sk-xxx请求头。
查看启动日志:
$ docker logs -f tei-cpu
2025-06-28T07:42:35.789940Z INFO text_embeddings_router: router/src/main.rs:175: Args { model_id: "/dat*/***-*****-**-v1.5", revision: None, tokenization_workers: None, dtype: None, pooling: None, max_concurrent_requests: 512, max_batch_tokens: 16384, max_batch_requests: None, max_client_batch_size: 32, auto_truncate: false, default_prompt_name: None, default_prompt: None, hf_api_token: None, hostname: "e8bd63738b34", port: 80, uds_path: "/tmp/text-embeddings-inference-server", huggingface_hub_cache: Some("/data"), payload_limit: 2000000, api_key: None, json_output: false, otlp_endpoint: None, otlp_service_name: "text-embeddings-inference.server", cors_allow_origin: None }
2025-06-28T07:42:35.806005Z INFO text_embeddings_router: router/src/lib.rs:199: Maximum number of tokens per request: 512
2025-06-28T07:42:35.807919Z INFO text_embeddings_core::tokenization: core/src/tokenization.rs:26: Starting 20 tokenization workers
2025-06-28T07:42:35.914301Z INFO text_embeddings_router: router/src/lib.rs:250: Starting model backend
2025-06-28T07:42:35.919736Z INFO text_embeddings_backend_candle: backends/candle/src/lib.rs:194: Starting Bert model on Cpu
2025-06-28T07:42:37.985431Z WARN text_embeddings_router: router/src/lib.rs:276: Backend does not support a batch size > 4
2025-06-28T07:42:37.985467Z WARN text_embeddings_router: router/src/lib.rs:277: forcing `max_batch_requests=4`
2025-06-28T07:42:37.985669Z WARN text_embeddings_router: router/src/lib.rs:328: Invalid hostname, defaulting to 0.0.0.0
2025-06-28T07:42:37.988948Z INFO text_embeddings_router::http::server: router/src/http/server.rs:1684: Starting HTTP server: 0.0.0.0:80
2025-06-28T07:42:37.988971Z INFO text_embeddings_router::http::server: router/src/http/server.rs:1685: Ready启动后可访问 http://localhost:9090/docs 查看 Swagger 文档:
调用向量嵌入接口:
$ curl localhost:9090/embed \
-X POST \
-d '{"inputs":"What is Deep Learning?"}' \
-H 'Content-Type: application/json'
[[-0.005919599,0.005813143,0.01830068,0.012513345,……,-0.006120732]]华为昇腾环境部署
在华为昇腾推理环境使用 TEI 需进行适配,可参考 MindIE开源第三方服务化框架适配开发指南 - TEI,或直接使用华为提供的 mis-tei镜像。
镜像需申请权限后才能下载,也可在 魔乐社区 直接下载 mis-tei:7.0.RC1-800I-A2-aarch64.tar.gz。
mis-tei:7.0.RC1-800I-A2-aarch64 镜像中 TEI 版本为 1.2.3。
昇腾镜像仓库 中还有提供配置好 TEI model-id 的镜像(启动时只需传入 host 和 port,需要更换 model-id 时较为麻烦,建议需要启动不同模型时,直接使用 mis-tei 镜像),如 bge-reranker-v2-m3:7.1.T2-800I-A2-aarch64,该镜像中 TEI 版本为 1.6.1。
mis-tei 镜像页面 中提供的启动命令如下:
docker run -u <user> -e ENABLE_BOOST=True -e ASCEND_VISIBLE_DEVICES=0 -itd --name=tei --net=host \
-v <model dir>:/home/HwHiAiUser/model \
<image id> <model id> <listen ip> <listen port>按此方式启动时可能会遇到如下报错:
...
2025-06-28T06:21:36.936649Z INFO text_embeddings_router: router/src/lib.rs:234: Starting model backend
2025-06-28T06:21:36.948436Z INFO text_embeddings_backend_python::management: backends/python/src/management.rs:68: Starting Python backend
2025-06-28 06:21:38.658 | INFO | __main__:<module>:8 - wait tei service ready...
2025-06-28T06:21:40.001106Z ERROR text_embeddings_backend: backends/src/lib.rs:414: Could not start Python backend: Could not start backend: Python backend failed to start
2025-06-28 06:21:41.737 | INFO | __main__:<module>:8 - wait tei service ready...
...
2025-06-28 06:22:55.662 | INFO | __main__:<module>:8 - wait tei service ready...
Error: Could not create backend
Caused by:
Could not start backend: Could not start a suitable backend
2025-06-28 06:22:58.663 | ERROR | __main__:<module>:8 - create engine meet error:tei-service start error
2025-06-28 06:22:58.663 | ERROR | __main__:<module>:8 - create engine failed如遇类似报错,可尝试按该页面关键参数解释中内容,改成下面方式启动容器:
-e ASCEND_VISIBLE_DEVICES: 挂载指定的npu卡到容器中,只有宿主机安装了Ascend Docker Runtime,此环境变量才会生效,如果未安装Ascend Docker Runtime,可参考配置如下参数挂载指定的卡到容器
--device=/dev/davinci_manager \ --device=/dev/hisi_hdc \ --device=/dev/devmm_svm \ --device=/dev/davinci0 \ --device=/dev/davinci1 \ -v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \ -v /usr/local/sbin:/usr/local/sbin:ro
docker run -u <user> -e ENABLE_BOOST=True \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device=/dev/devmm_svm \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/sbin:/usr/local/sbin:ro \
-itd --name=tei --net=host \
-v <model dir>:/home/HwHiAiUser/model \
<image id> <model id> <listen ip> <listen port>使用
mis-tei镜像启动 TEI 服务时,因为镜像的entrypoint调整为了自定义脚本,不是官方镜像中的text-embeddings-router命令,所以不能在 docker 启动命令中以命令行参数形式设置 API KEY。可参考官方镜像方式,在 docker 启动命令中设置环境变量,或在镜像中/home/HwHiAiUser/start.sh脚本内的text-embeddings-router命令后添加命令行参数来配置 API KEY。
API
/v1/embeddings
查看本地部署的 TEI 服务 Swagger 文档,或在线文档( https://huggingface.github.io/text-embeddings-inference ),可以看到除了 /embed 接口外,还有兼容 OpenAI 向量嵌入接口 格式的 /v1/embeddings 接口:
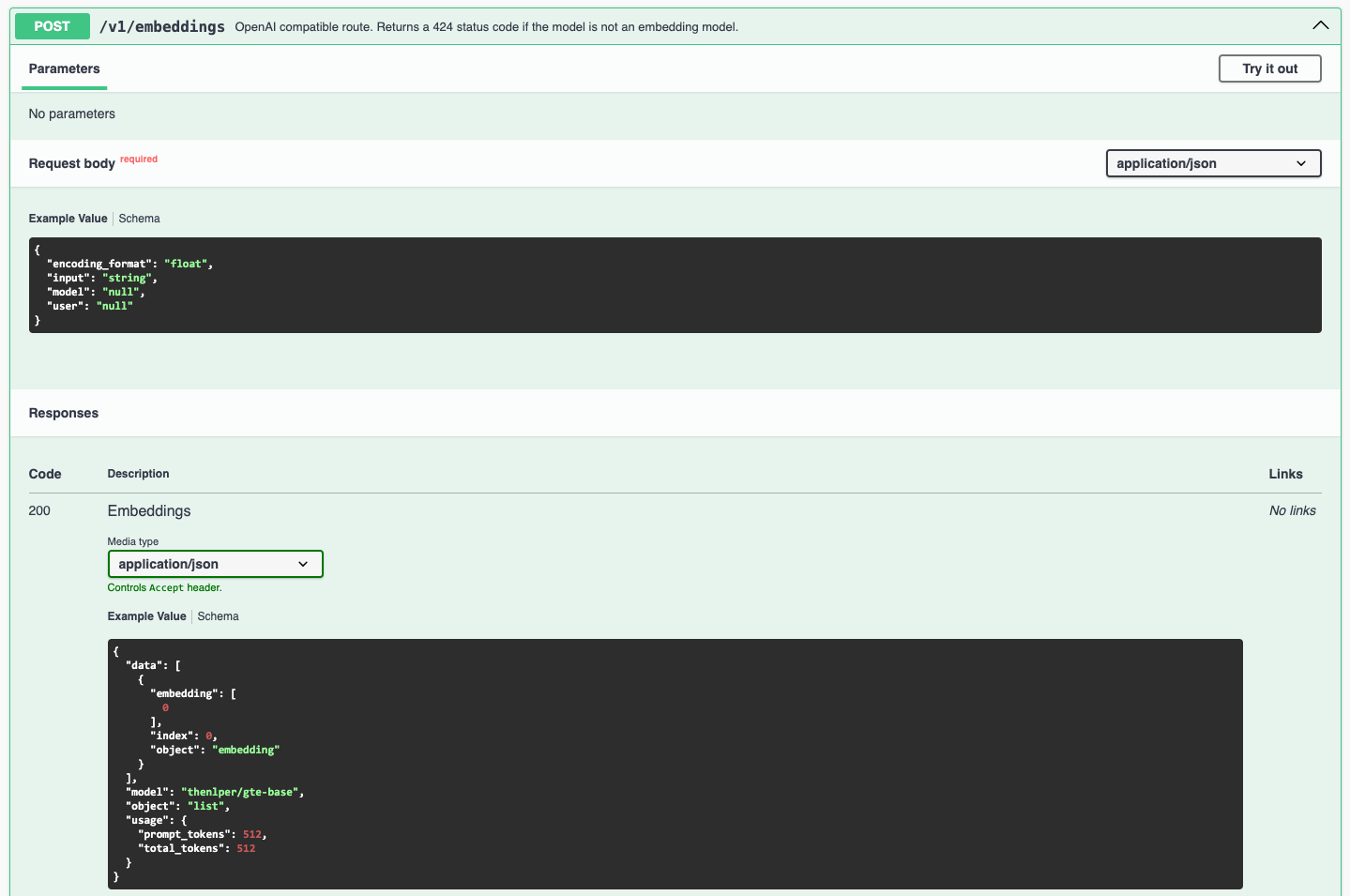
可在源码中找到相关内容:
let mut routes = Router::new()
// Base routes
.route("/info", get(get_model_info))
.route("/embed", post(embed))
.route("/embed_all", post(embed_all))
.route("/embed_sparse", post(embed_sparse))
.route("/predict", post(predict))
.route("/rerank", post(rerank))
.route("/similarity", post(similarity))
.route("/tokenize", post(tokenize))
.route("/decode", post(decode))
// OpenAI compat route
.route("/embeddings", post(openai_embed))
.route("/v1/embeddings", post(openai_embed))
// Vertex compat route
.route("/vertex", post(vertex_compatibility));async fn openai_embed(
infer: Extension<Infer>,
info: Extension<Info>,
Extension(context): Extension<Option<opentelemetry::Context>>,
Json(req): Json<OpenAICompatRequest>,
) -> Result<(HeaderMap, Json<OpenAICompatResponse>), (StatusCode, Json<OpenAICompatErrorResponse>)>并通过 curl 验证:
$ curl http://localhost:9090/v1/embeddings \
-X POST \
-d '{"input": "What is Deep Learning?"}' \
-H 'Content-Type: application/json'
{"object":"list","data":[{"object":"embedding","embedding":[-0.005919599,0.005813143,0.01830068,0.012513345,...,-0.006120732],"index":0}],"model":"/data/bge-large-zh-v1.5","usage":{"prompt_tokens":7,"total_tokens":7}}/rerank
重排接口请求体结构在 https://github.com/huggingface/text-embeddings-inference/blob/v1.7.2/router/src/http/types.rs#L240-L258 中定义:
#[derive(Deserialize, ToSchema)]
pub(crate) struct RerankRequest {
#[schema(example = "What is Deep Learning?")]
pub query: String,
#[schema(example = json!(["Deep Learning is ..."]))]
pub texts: Vec<String>,
#[serde(default)]
#[schema(default = "false", example = "false", nullable = true)]
pub truncate: Option<bool>,
#[serde(default)]
#[schema(default = "right", example = "right")]
pub truncation_direction: TruncationDirection,
#[serde(default)]
#[schema(default = "false", example = "false")]
pub raw_scores: bool,
#[serde(default)]
#[schema(default = "false", example = "false")]
pub return_text: bool,
}#[derive(Serialize, ToSchema)]
pub(crate) struct Rank {
#[schema(example = "0")]
pub index: usize,
#[schema(nullable = true, example = "Deep Learning is ...", default = "null")]
#[serde(skip_serializing_if = "Option::is_none")]
pub text: Option<String>,
#[schema(example = "1.0")]
pub score: f32,
}
#[derive(Serialize, ToSchema)]
pub(crate) struct RerankResponse(pub Vec<Rank>);可通过如下方式调用:
$ curl http://localhost:9093/rerank \
-X POST \
-d '{"query":"What is Deep Learning?", "texts": ["Deep Learning is not...", "Deep learning is..."]}' \
-H 'Content-Type: application/json'
[{"index":1,"score":0.99762183},{"index":0,"score":0.0.12474516}]需要通过 TEI 启动多个模型时,需要启动多个
text-embeddings-router进程,或多个 docker 容器。
在 Dify 中配置 TEI 部署的模型
Dify 支持通过 Text Embedding Inference 模型提供商配置 TEI 部署的向量嵌入和重排模型:

嵌入模型
配置嵌入模型时,会调用以下接口进行验证:/info、/tokenize、/v1/embeddings。
没错,用的是兼容 OpenAI 接口格式的向量嵌入接口,不是 TEI 自定义的 /embed 接口,在通过反向代理访问 TEI 服务时需注意。
既然如此,也可以直接使用 Dify 中 OpenAI-API-compatible 模型供应商配置 TEI 发布的嵌入模型服务。
相关源码位置:
- v0.15.x:https://github.com/langgenius/dify/blob/0.15.8/api/core/model_runtime/model_providers/huggingface_tei/tei_helper.py
- v1.x:https://github.com/langgenius/dify-official-plugins/blob/main/models/huggingface_tei/models/helper.py
重排模型
使用 TEI 模型供应商配置重排模型时,会调用 /info 及 /rerank 接口进行校验。
若 /info 接口返回的模型类型(model_type)不是 reranker,则无法完成配置。
- 向量嵌入模型 info 示例:
{
"model_id": "/data/bge-large-zh-v1.5",
"model_sha": null,
"model_dtype": "float32",
"model_type": {
"embedding": {
"pooling": "cls"
}
},
"max_concurrent_requests": 512,
"max_input_length": 512,
"max_batch_tokens": 16384,
"max_batch_requests": 4,
"max_client_batch_size": 32,
"auto_truncate": false,
"tokenization_workers": 20,
"version": "1.4.0",
"sha": "a0549e625b7c9045257d61d302322d9b64fc7395",
"docker_label": "sha-a0549e6"
}- 重排模型 info 示例:
{
"model_id": "/data/bge-reranker-v2-m3",
"model_sha": null,
"model_dtype": "float16",
"model_type": {
"reranker": {
"id2label": {"0":"LABEL_0"},
"label2id": {"LABEL_0":0}
}
},
"max_concurrent_requests": 512,
"max_input_length": 8192,
"max_batch_tokens": 16384,
"max_batch_requests": null,
"max_client_batch_size": 32,
"auto_truncate": false,
"tokenization_workers": 20,
"version": "1.2.3",
"sha": "a0549e625b7c9045257d61d302322d9b64fc7395",
"docker_label": null
}OpenAI API Reference 中并没有 /rerank 接口的定义。
Dify 中的 OpenAI-API-compatible 模型供应商在配置 Rerank 模型时,使用的是 Jina 重排器 的接口:
Jina API 文档 中关于 Reranker API 的定义如下:
Endpoint: https://api.jina.ai/v1/rerank
Request body schema:
{
"application/json": {
"documents": {
"description": "A list of strings, TextDocs, and/or images to rerank. If a document object is provided, all text fields will be preserved in the response. Only jina-reranker-m0 supports images.",
"required": true,
"type": "If v2 or colbert reranker: array of strings and/or TextDocs. If m0 reranker: object with keys \"text\" and/or \"image\", and values of strings, TextDocs, and/or images (URLs or base64-encoded strings)"
},
"model": {
"description": "Identifier of the model to use.",
"options": [
{
"name": "jina-reranker-m0",
"size": "2.4B"
},
{
"name": "jina-reranker-v2-base-multilingual",
"size": "278M"
},
{
"name": "jina-colbert-v2",
"size": "560M"
}
],
"required": true,
"type": "string"
},
"query": {
"description": "The search query.",
"required": true,
"type": "string, TextDoc, or image (URL or base64-encoded string)"
},
"return_documents": {
"default": true,
"description": "If false, returns only the index and relevance score without the document text. If true, returns the index, text, and relevance score.",
"required": false,
"type": "boolean"
},
"top_n": {
"description": "The number of most relevant documents or indices to return, defaults to the length of documents.",
"required": false,
"type": "integer"
}
}
}Example response:
{
"model": "jina-reranker-m0",
"results": [
{
"index": 0,
"relevance_score": 0.9587112551898949
},
{
"index": 1,
"relevance_score": 0.9337408271911014
}
],
"usage": {
"total_tokens": 2829
}
}可以看到,与 TEI 定义的 /rerank 接口在主要的请求和响应体结构上均有区别,TEI 接口传入待排序文本列表使用的属性是 texts,而 Jina 接口使用的是 documents。
