前言
所有代码示例都可以在GitHub(https://github.com/java9-modularity/examples )上找到。
知识是共享的唯一财富
第一部分 Java模块系统介绍
第1章 模块化概述
1.1 什么是模块化
模块必须遵循以下三个核心原则:
1.强封装性
2.定义良好的接口
3.显式依赖
1.2 在Java 9之前
OSGi要求将导入的包在JAR中列为元数据,称之为捆绑包(bundle)。
此外,还必须显式定义导出哪些包,即对其他捆绑包可见的包。
Maven和OSGi构建在JVM和Java语言之上
Java 9解决了JVM和Java语言的核心中存在的一些相同问题。模块系统并不打算完全取代这些工具,Maven和OSGi(及类似工具)仍然有自己的一席之地,只不过现在它们可以建立在一个完全模块化的Java平台之上。
1.3 Java 9模块
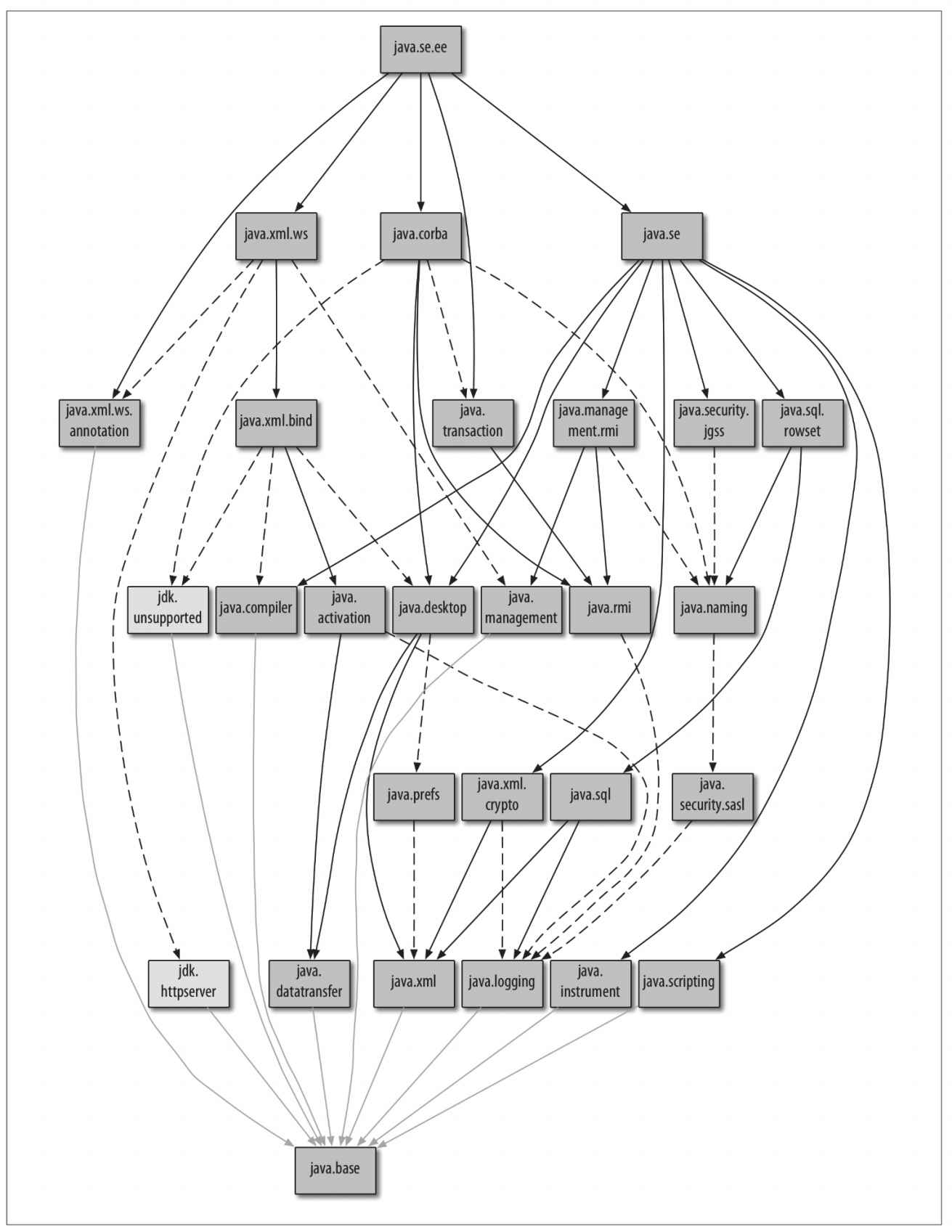
在模块化JDK中,最基本的平台模块是java.base。它公开了诸如java.lang和java.util之类的包,如果没有这些包,其他模块什么也做不了。
第2章 模块和模块化JDK
2.1 模块化JDK
通过运行java–list-modules,可以获取平台模块的完整列表。
2.2 模块描述符
模块描述符保存在一个名为module-info.java的文件中。示例2-1显示了java.prefs平台模块的模块描述符。

2.4 可访问性

在其他模块中,只能访问导出包中的公共类型。如果导出包中的一个类型不是公共的,那么传统的可访问性规则将不允许使用该类型。如果类型是公共的,但没有导出,那么模块系统的可读性规则将阻止使用该类型。
其他模块无法使用未导出包中的任何类型——即使包中的类型是公共的。这是对Java语言可访问性规则的根本变化。
2.5 隐式可读性
默认情况下,可读性是不可传递的。
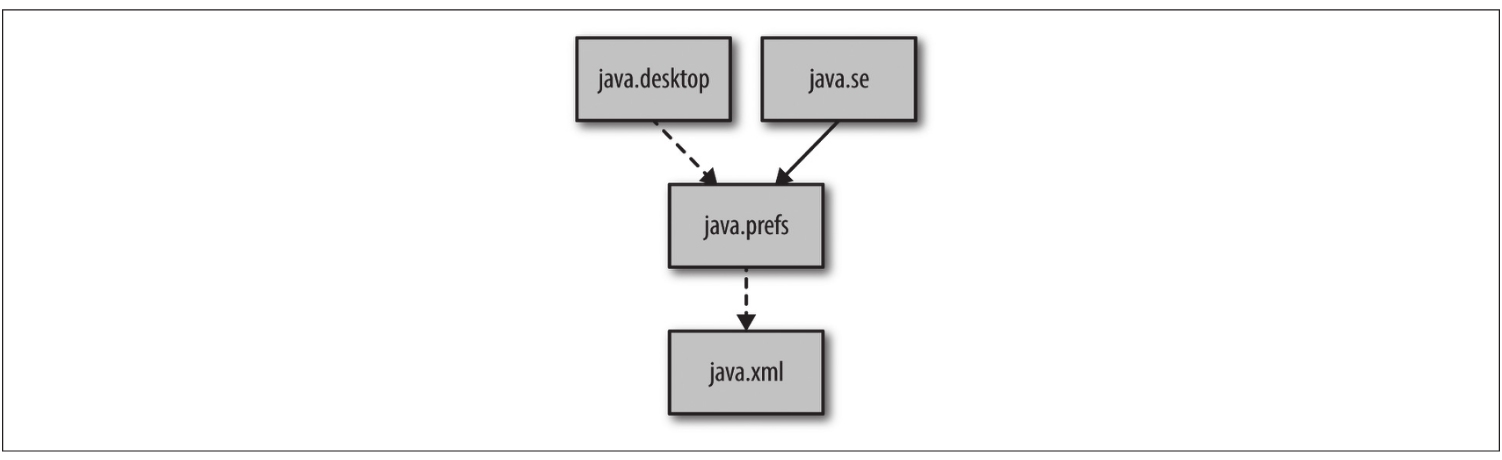
隐式可读性允许模块的作者在模块描述符中表达这种可传递的可读性关系。
通过使用requires transitive,模块作者可以为模块用户设置额外的可读性关系。
非传递依赖(nontransitive dependency)意味着依赖关系是支持模块内部实现所必需的。可传递依赖(transitive dependency)则意味着依赖关系是支持模块API所必需的。
隐式可读性的另一个用例:可用来将多个模块聚合到一个新模块中。
隐式可读性自身也是可传递的。
在应用程序模块中使用java.se.ee或java.se是不明智的,这意味着在模块中复制了Java 9之前可以访问的rt.jar的所有行为。依赖关系应尽可能细化。在模块描述符中要尽可能精确同时只添加实际使用的模块,这是非常重要的。
2.6 限制导出
在某些情况下,可能只需要将包暴露给特定的某些模块。此时,可以在模块描述符中使用限制导出。
导出的包只能由to之后指定的模块访问。可以用由逗号分隔的多个模块名称作为限制导出的目标。to子句中没有提到的任何模块都不能访问包中的类型,即使在读取模块时也是如此。
限制导出的存在并不意味着就一定要使用它们。一般来说,应该避免在应用程序的模块之间使用限制导出。使用限制导出意味着在导出模块和允许的使用者之间建立了直接的联系。从模块化的角度来看,这是不可取的。模块之所以伟大,是因为它可以有效地对API的生产者与使用者进行解耦。而限制导出破坏了这个属性,因为现在使用者模块名称成为提供者模块描述符的一部分。
通过使用限制导出,平台模块可以在不重复代码的情况下变得更细粒度。
2.8 在不使用模块的情况下使用模块化JDK
Java 9可以像以前的Java版本一样使用,而不必将代码移动到模块中。模块系统完全适用于现有的应用程序代码,类路径仍然可以使用。
在一个模块之外编译和加载的代码最终都放在未命名模块(unnamed module)中。
未命名模块非常特殊:它可以读取所有其他模块
当在Java 9类路径上运行(而不是编译)一个应用程序时,使用了更为宽松的强封装形式。在JDK 8以及更早版本上可访问的所有内部类在JDK 9运行时上都是可访问的。但是当通过反射访问这些封装类型时,会出现警告信息。
在未命名模块中编译代码时需要注意的第二件事是编译期间java.se将作为根模块。如示例2-5所示,可以通过java.se访问任何可访问模块中的类型。这意味着java.se.ee(而不是java.se)下的模块(比如java.corba和java.xml.ws)都无法解析,因此也就无法访问。
第3章 使用模块
3.1 第一个模块
文件系统中源文件的布局如下所示:
①模块目录。
②模块描述符。

在src的下面引入了另一个目录helloworld,该目录以所创建的模块名称命名。
模块描述符位于module-info.java文件中,是Java模块的关键组成部分。它的存在相当于告诉Java编译器正在使用的是一个模块,而不是普通的Java源代码。
使用新关键字module并紧跟模块名称声明了一个模块。该名称必须与包含模块描述符的目录名称相匹配。否则,编译器将拒绝编译并报告匹配错误。
仅在多模块模式下(这种情况是非常常见的)运行编译器时,才需要满足名称匹配要求。
单模块方案,目录名称无关紧要。但在任何情况下,使用模块名称作为目录名称不失为一个好主意。
该模块隐式地依赖java.base平台模块。
此时,你可能会问,向语言中添加新的关键字是否会破坏使用module作为标识符的现有代码。幸运的是,情况并非如此。仍然可以在其他源文件中使用名为module的标识符,因为module关键字是限制关键字(restricted keyword),它仅在module-info.java中被视为关键字。对于目前在模块描述符中所看到的requires关键字和其他新关键字来说,也是一样的。
在module-info.java之前,就已经有了package-info.java。
在package-info.java中,可以向包声明中添加文档和注释。
当具有相同名称的多个模块位于模块路径上的不同目录中时,则不会产生错误,而是选择第一个模块,并忽略具有相同名称的后续模块。
3.3 使用平台模块
当运行java–list-modules时,运行时将输出所有可用的平台模块
以java.为前缀的平台模式是Java SE规范的一部分。它们通过Java SE的JCP(Java Community Process)导出标准化的API。JavaFX API分布在共享javafx.前缀的模块中。以jdk.开头的模块包含了JDK特定的代码,在不同的JDK实现中可能会有所不同。
第4章 服务
4.2 用于实现隐藏的服务
如果没有来自模块系统的特殊支持,想要将服务实现暴露给另一个模块而又不导出实现类是不可能的。Java模块系统允许在module-info.java中添加提供和消费服务的声明性描述。
示例4-2:提供了Analyzer服务的模块描述符( chapter4/easytext-services)
module easytext.analysis.coleman { requires easytext.analysis.api; provides javamodularity.easytext.analysis.api.Analyzer with javamodularity.easytext.analysis.coleman.ColemanAnalyzer; }
provides with语法声明该模块提供了Analyzer接口的一个实现(使用ColemanAnalyzer作为实现类)。服务类型(provides之后)和实现类(with之后)必须是完全限定类型名称。最重要的是,包含ColemanAnalyzer实现类的包并不从此提供者模块中导出。
服务允许一个模块向其他模块提供实现,而不导出具体的实现类。
在Java模块系统中,消费服务需要两个步骤。第一步是向CLI模块的module-info.java中添加uses子句:
module easytext.cli { requires easytext.analysis.api; uses javamodularity.easytext.analysis.api.Analyzer; }
uses子句告知ServiceLoader(稍后将介绍该API)该模块想要消费Analyzer的实现,然后ServiceLoader使Analyzer实例可用于模块。

每次调用ServiceLoader::load时,都会实例化一个新的ServiceLoader。当请求提供者类时,新的ServiceLoader会重新实例化它们。从现有的ServiceLoader实例请求服务将返回提供者类的缓存实例。
如下面代码所示:

提供者方法是一个名为provider的public static无参数方法,其返回类型是服务类型。
4.3 工厂模式回顾
示例4-7:在服务接口上提供一个工厂方法(chapter4/easytext-services-factory)
public interface Analyzer { String getName(); double analyze(List<List<String>> text); static Iterable<Analyzer> getAnalyzers() { return ServiceLoader.load(Analyzer.class); } }
①此时,查询在服务类型内部完成。
由于ServiceLoader查找是在API模块的Analyzer内完成的,因此其模块描述符必须使用uses约束:
module easytext.analysis.api { exports javamodularity.easytext.analysis.api; uses javamodularity.easytext.analysis.api.Analyzer; }
现在,API模块导出了接口并使用了Analyzer接口的实现。想要获得Analyzer实现的消费者模块不再需要使用ServiceLoader了(当然,仍然可以使用Service-Loader),取而代之,所有消费者模块需要做的就是请求API模块,并调用Analyzer::getAnalyzers。从消费者角度来看,不再需要uses约束或Service-Loader API了。
通过这种机制,可以悄无声息地使用服务的强大功能,不再强迫API用户去了解服务或ServiceLoader,与此同时仍然可以获得解耦和可扩展性所带来的好处。
4.5 服务实现的选择
ServiceLoader.Provider类使得在请求实例之前检查服务提供者成为可能。
4.7 服务和链接
在jlink中不执行自动服务绑定的一个更切合实际的原因是java.base具有大量的uses子句。所有这些服务类型的提供者位于其他各种平台模块中,默认绑定所有这些服务将会增大映像的大小。如果jlink中没有执行自动服务绑定,就可以创建一个仅包含java.base和应用程序模块的映像
第5章 模块化模式
5.2 精益化模块
在考虑模块的度量时,需要考虑两个指标:模块公共区域面积(surface area)的大小以及内部实现的大小。
建议尽量减少模块的公共区域面积。
5.3 API模块
使用-Xlint:exports进行编译,那么导出类型中应该以传递方式依赖但却没有依赖的类型就会产生警告信息。这样一来,就可以在编译API模块时发现问题。
隐式可读性仅用于防止以前所看到的编译器错误等意外情况,将模块所拥有的真正依赖关系全权委托给隐式可读性是一种“懒惰的做法”。
当希望有多个API的实现时,分离API和实现是一个有用的模式。而当只有一个实现时,将API和实现捆绑在同一个模块中则更有意义的。
5.5 避免循环依赖
模块划分与现有的包边界不能保持一致时就会产生拆分包。

Java模块系统不允许拆分包。只允许一个模块可以将给定的包导出到另一个模块。由于导出是根据包名称声明的,因此如果两个模块导出相同的包,那么就会产生不一致。如果允许这样做,那么两个模块就可能会导出具有相同的完全限定名称的类。而当另外一个模块依赖于这两个模块并且想要使用这个类时,就会出现该类应该来自哪个模块的冲突。
模块系统会检查在所有模块中是否存在重叠包,其中包括平台模块。
当JAR所包含的包与JDK包重叠时,如果将这些JAR放到类路径上,那么它们的类型将被忽略,并且不会被加载。
服务可以互相使用,从而在运行时形成一个循环调用图。
那么,为什么在编译时严格禁止循环呢?JVM可以在运行时延迟加载类,在出现循环的情况下允许多级解析策略。但是,只有在编译器所使用的所有其他类型已经被编译或在同一编译运行中正在被编译时,编译器才能编译该类型。
5.6 可选的依赖关系
这些可选的依赖关系无法使用前面所介绍的模块描述符来表达
服务提供了极大的灵活性,并且是解决应用程序中可选依赖关系的好方法
当不能选择使用服务时,可以使用模块系统的另一个特性来建立可选依赖关系:编译时依赖关系。
通过将修饰符static添加到requires子句中,可以在模块上表达编译时依赖关系
requires static可能并不是在模块之间创建可选耦合的最佳方式。
当在运行时检索元素的注释并且注释类不存在时,JVM会正常降级,并且不会抛出任何类加载异常。不过,编译代码时仍然需要访问注释类型。
虽然static可以与transitive结合使用,但这样做并不是一个好主意。此时需要在API消费者上创建适当的防护代码,这显然不符合最小惊讶原则(the principle of least surprise)。
虽然使用编译时依赖关系来建立可选依赖关系是可能的,但需要经常使用反射来保护类的加载。此时,使用服务更加合适。
5.7 版本化模块
可以使用jar工具的–module-version=
标志来设置版本。版本V被设置为已编译的module-info.class上的一个属性,并且在运行时可用。
始终从模块消费者的角度来推理:模块的下一个版本应该反映即将发生的变化对模块用户的影响。
即使支持向模块化JAR添加版本,模块系统也不会以任何方式使用它。模块完全是由名称进行解析的。
事实证明,这些版本选择算法以及相关的冲突解决试探法既复杂又不同(有时仅存在微小的区别)。这就是为什么现在的Java模块系统在模块解析过程中避开了版本选择的概念。
将正确版本的依赖关系的选择和检索委托给现有的构建工具来完成。
如果两个具有相同名称的模块位于模块路径上的不同目录中,那么解析器将使用所遇到的第一个模块,而忽略第二个模块。此时,不会产生任何错误。
5.8 资源封装
也可以通过ClassLoader::getResource*方法加载资源。在模块上下文中,最好使用Class和Module上的方法。ClassLoader方法不会像Class和Module方法那样考虑当前模块上下文,从而导致潜在的混乱结果。
第6章 高级模块化模式
6.1 重温强封装性
即使一个类型被导出,也并不意味着可以无条件地通过反射“闯入”这些类型的私有部分。
Java中,深度反射由反射对象上的setAccessible方法提供支持。它绕过了检查,从而可以访问不可访问的部分。
模块系统和强封装出现之前,setAccessible基本上不会失败。但如果使用了模块系统,那么规则就发生了变化。图6-1显示了不再适用的场景。

此时需要的是一种可以在不导出类型的情况下在运行时让类型可用于深度反射的方法。一旦具备了这样的功能,框架可以完成自己的工作,同时在编译时仍然可以保持强封装性。
开放式模块提供了这些功能的组合。当开放一个模块时,所有类型都可以在运行时被其他模块深度反射。无论是否导出包,该属性都是成立的。
只需在模块描述符中添加关键字open,就可以开放一个模块
当知道需要开放哪些包时(大多数情况下都应该知道),可以有选择性地从一个普通模块中开放所需的包:
module deepreflection { exports api; opens internal; }
合适的opens可以将范围缩小到一个或多个明确提到的模块。如果可以限定opens声明,那么最好这样做。这样一来,就可以防止任意模块通过深度反射窥探内部细节信息。
有时需要对第三方模块进行深度反射。在某些情况下,有些库甚至想反射访问JDK平台模块的私有部分。此时添加open关键字并重新编译模块是不可能的。针对这些情况,为Java命令引入了一个命令行标志:
–add-opens
/ =
上面的命令行标志等同于将module中的package限定开放给targetmodule
Java 9为应用程序中非公共类成员的基于反射的框架访问提供了一种替代方案:MethodHandles和VarHandles。
应用程序可以将具有适当权限的java.lang.invoke.Lookup实例传递给框架,显式委派私有查找功能。然后,框架模块使用MethodHandles.privateLookupIn(Class,Lookup)访问应用程序模块类中的非公共成员。
6.2 对模块的反射
Module target = ...; // 以某种方式获得想要导出到的模块 Module module = getClass().getModule(); // 获取当前类的模块 module.addExports("javamodularity.export.atruntime", target);
可以通过Module API向特定的模块添加限制导出。
当尝试将导出添加到正在执行调用的当前模块之外的任何其他模块时,VM就会引发异常。无法通过模块反射API从外部升级模块的权限。
那些从不同地方调用时行为方式不同的方法被称为调用者敏感(caller sensitive)方法。可以在JDK源代码中找到许多用@CallerSensitive进行注释的方法,比如addExports。调用者敏感方法可以根据当前的调用堆栈找出哪个类(和模块)正在调用它们。
6.3 容器应用程序模式
使用新的类加载器将每个插件模块加载到自己的层中还有另一个好处。通过这种方式来隔离插件,可以让插件依赖于相同模块的不同版本。
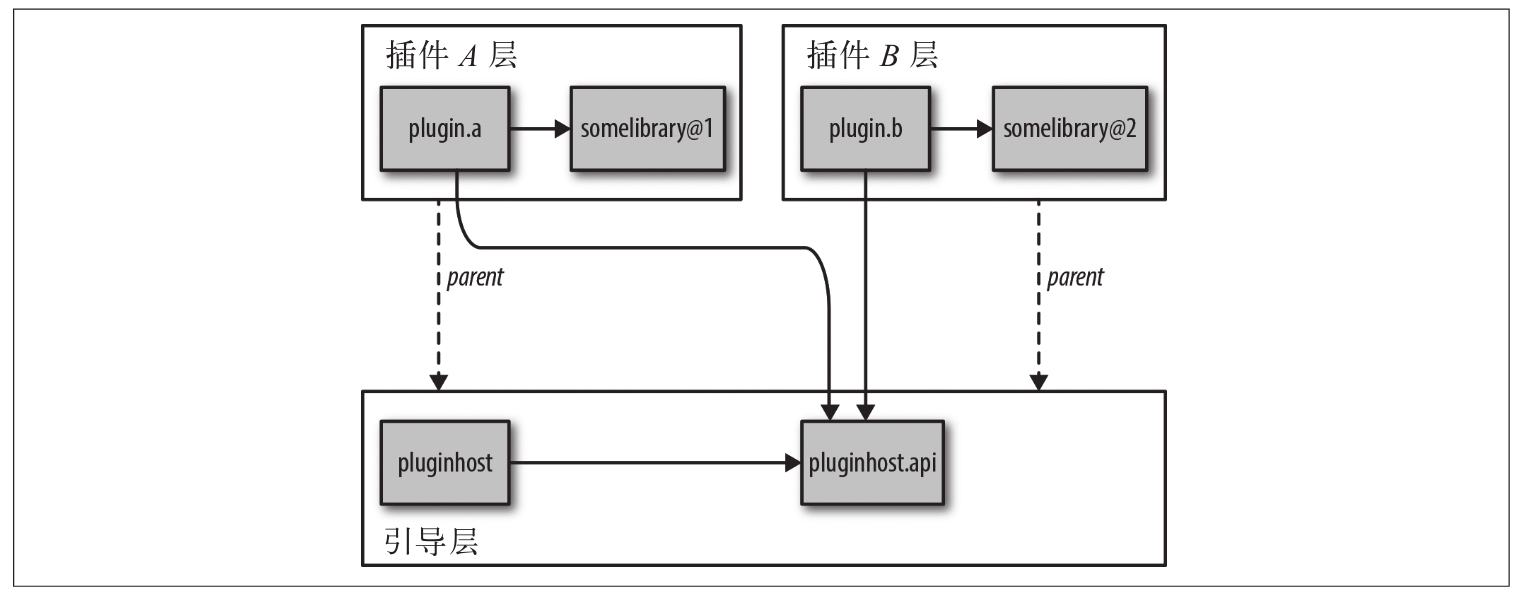
正常的模块解析规则是:启动的根模块决定哪些平台模块被解析。当根模块是容器启动器时,只考虑容器启动器模块的依赖项。只有根模块的(可传递)依赖项在运行时最终到达引导层。
第二部分 迁移
第7章 没有模块的迁移
7.7 其他更改
–illegal-access=deny来运行你的应用程序,以便为将来做好准备。
第8章 迁移到模块
8.4 自动模块
Java模块系统提供了一个有用的功能来处理非模块的代码:自动模块。只需将现有的JAR文件从类路径移动到模块路径,而不改变其内容,就可以创建一个自动模块。这样一来,JAR就转换为一个模块,同时模块系统动态生成模块描述符。相比之下,显式模块始终有一个用户自定义的模块描述符。
自动模块具有以下特征:
- 不包含module-info.class。
- 它有一个在META-INF/MANIFEST.MF中指定或者来自其文件名的模块名称。
- 通过requires transitive请求所有其他已解析模块。
- 导出所有包。
- 读取路径(或者更准确地讲,读取前面所讨论的未命名模块)。
- 它不能与其他模块拆分包。
模块图中的所有模块都需要通过自动模块传递。这实际上意味着,如果请求一个自动模块,那么就可以“免费”获得所有其他模块的隐式可读性。这是一种权衡
自动模块的名称可以在META-INF/MANIFEST.MF文件的新引入的Automatic-Module-Name字段中指定。
如果没有指定名称,则模块名称是从JAR的文件名派生的。命名算法大致如下:
- 使用点(.)替换破折号(-)。
- 忽略版本号。
8.8 自动模块和类路径
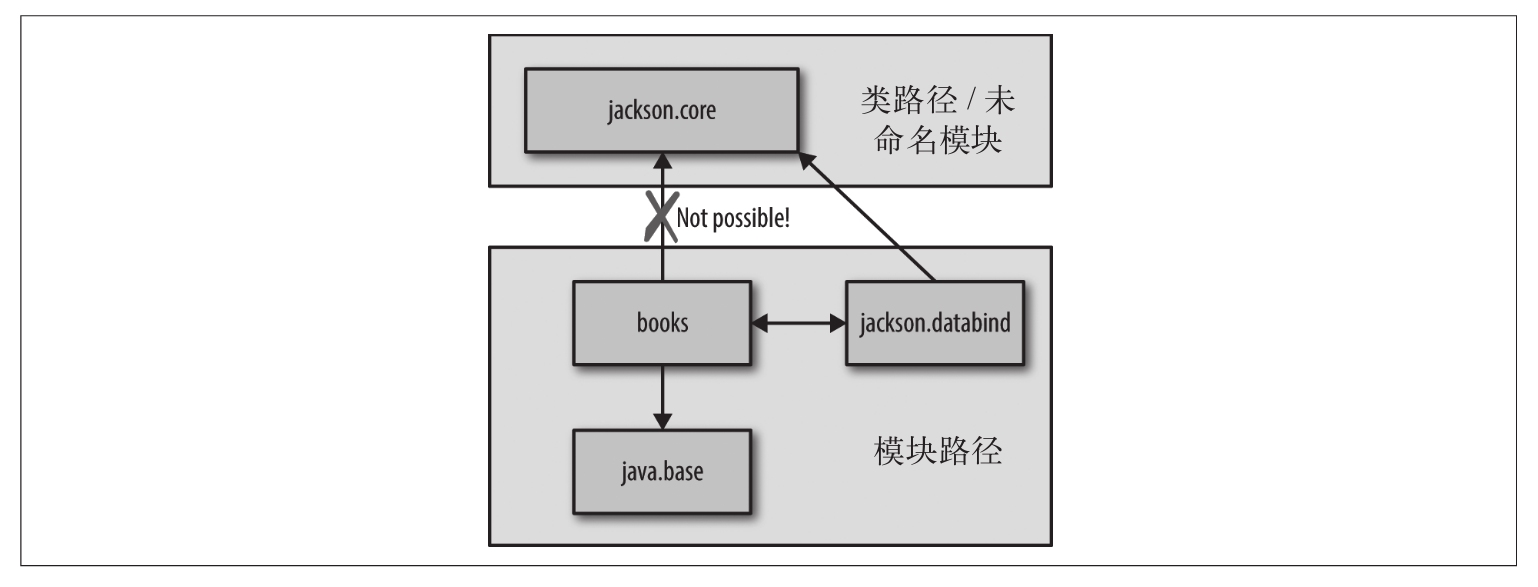
显式模块只能读取其他显式模块和自动模块。而自动模块可读取所有模块,包括未命名模块。
8.9 使用jdeps
jdeps是JDK附带的一个工具,用于分析代码并提供关于模块依赖关系的了解。
jdeps分析的是字节码
8.11 拆分包
为了使迁移变得容易一些,当涉及自动模块和未命名模块时,上述规则存在一个例外,即承认很多类路径是不正确的,并且包含拆分包。当(自动)模块和未命名模块都包含相同的包时,将使用来自(自动)模块的包,而未命名模块中的包被忽略。
通过在类路径上放置相关包来覆盖平台包是很常见的,但这种方法已经不再适用于Java 9了
第9章 迁移案例研究:Spring和Hibernate
9.8 重构到多个模块
将现有的基于类路径的应用程序迁移到模块所需的所有工具和流程。使用jdeps分析现有的代码和依赖关系。将库移动到模块路径以使其转换为自动模块,从而允许为应用程序创建模块描述符。当应用程序使用涉及反射的库时(如依赖注入、对象关系映射或序列化库),则需要开放包和模块。
第10章 库迁移
10.2 选择库模块名称
在META-INF/MANIFEST.MF中添加一个Automatic-Module-Name:
条目到非模块化JAR。当该JAR被用作自动模块时,它将采用清单中定义的名称,而不是从JAR文件名中派生名称。
jar命令有一个-m
选项,告诉它将来自给定文件的条目添加到JAR中所生成的MANIFEST.MF中
10.3 创建模块描述符
除了列出依赖项之外,jdeps甚至可以生成一个初始模块描述符:
jdeps –generate-module-info ./out mylibrary.jar
如果依赖关系是可选的,那么这些子句可以是requires static。如果库使用了服务,则必须手动添加uses子句。
对于库,最好使用反向DNS表示法来创建完全限定的名称。
10.5 针对较旧的Java版本
JDK 9包含的–release新标志来编译
这个新标志保证至少支持当前JDK的前三个主要版本。
–release标志是通过JEP 247(http://openjdk.java.net/jeps/247 )添加的。在此之前,可以使用-source和-target选项。
这些标志确保不会使用错误级别的语言特性(-source),并且生成的字节码符合正确的Java版本(-target)。但是,这些标志没有强制正确使用目标JDK的API。
如果使用–release,正确的库级别也由Java编译器强制执行——不再需要安装和管理多个JDK。
10.6 库模块依赖关系
服务uses子句不能由jdeps自动生成。这些子句必须根据库中的ServiceLoader使用情况手动添加。
依赖阴影(dependency shading)。其主要思想是通过将外部代码内联到库中来避免外部依赖。简而言之,外部依赖项的类文件被复制到库JAR中。为了防止原始外部依赖项也出现在类路径上时所发生的名称冲突,在内联过程中将重命名包。例如,来自org.apache.commons.lang3的类将会被重命名为com.javamodularity.mylibrary.org.apache.commons.lang3。所有这些都是自动完成的,并通过后期处理字节码在构建时发生。这可以防止恶意软件包名称渗透到实际的源代码中。
10.7 针对多个Java版本
JAR在符合特定布局并且其清单包含Multi-Release:true条目时启用了多版本。类的新版本需要位于META-INF/versions/
目录中,其中 对应于主要的Java平台版本号。不能专门为次要版本或补丁版本进行版本升级。
与所有清单条目一样,Multi-Release:true条目周围不能有前导或尾随空格。条目的关键字和值不区分大小写。
由于替代类文件位于META-INF目录下,因此早期的JDK将忽略它。但是,当在JDK 9上运行时,加载的是此类文件而不是顶级的Helper类。该机制在类路径和模块路径上都可以工作。JDK 9中的所有类加载器都可以进行多版本JAR识别。由于在JDK 9中引入了多版本JAR,因此versions目录下只能使用9及以上版本。任何早期的JDK都只能看到顶级类。
只需使用不同的–release设置编译不同的源就可以创建一个多版本JAR:
javac --release 7 -d mrlib/7 src/<all top-level sources> javac --release 9 -d mrlib/9 src9/mrlib/Helper.java jar -cfe mrlib.jar src/META-INF/MANIFEST.MF -C mrlib/7 . jar -uf mrlib.jar --release 9 -C mrlib/9 .①在所需的最低版本级别下编译所有常规源代码。
②仅针对Java 9单独编译代码。
③使用正确的清单和顶级类创建一个JAR文件。
④使用新的–release标志更新JAR文件,将类文件放置到正确的META-INF/versions/9目录中。
尽量减少版本化类的数量是一个好主意。将差异分解成若干个类减少了维护的负担,但对JAR中的所有类进行版本化是不可取的。
当前的JVM总是加载与Java运行时自身版本相匹配的该类的最新版本。资源遵守与类相同的规则。可以将不同JDK版本的特定资源放在versions目录中,并将按照相同的优先顺序加载它们。
使用版本化的模块描述符是允许的,如versions/9下的模块描述符以及versions/10下的模块描述符。模块描述符之间所允许的差异应该尽可能小。这些差异不应导致Java版本之间可观察到的行为差异,就像普通类的不同版本必须具有相同的签名一样。
第三部分 模块化开发工具
第11章 构建工具和IDE
11.1 Apache Maven
依赖项可能是也可能不是显式模块。如果找不到module-info.class,则依赖项变成一个自动模块。这一切对用户是透明的:从Apache Maven用户的角度来看,使用显式模块或自动模块没有任何区别。
第12章 测试模块
12.3 白盒测试
通过使用称为模块修补(module patching)的功能,可以将新类添加到现有模块中。
需要使用–patch-module标志编译
类和资源都可以修补到模块中,唯一不能被替换的是模块描述符。
–patch-module标志也适用于平台模块。所以,从技术上讲,可以(重新)在java.base模块的java.lang包中放置类。模块修补将替换-Xbootclasspath:/p,这是在JDK 9中已删除的功能。
第13章 使用自定义运行时映像惊醒缩减
13.2 使用jlink
只有通过requires子句才会对模块图进行解析;默认情况下jlink并不遵循uses和provides依赖关系。
可以将–bind-services标志添加到jlink,从而指示jlink在解析模块时考虑uses/provides。但是,这样一来就绑定了平台模块之间的所有服务。因为java.base已经使用了很多(可选的)服务,所以这样做会导致重复解析更多不需要的已解析模块。
13.3 查找正确的服务提供者模块
可以通过使用–suggest-providers选项来帮助选择合适的服务提供者模块。
13.4 链接期间的模块解析
jlink不会将模块路径上的非模块JAR识别为自动模块。只有当应用程序完全模块化时(包括所有库),才可以使用jlink。
13.5 基于类路径应用程序的jlink
还可以使用jlink创建Java平台的自定义映像,而不包括任何应用程序模块。
jlink的这种用法显示了JDK和JRE之间的界限在模块化的世界中如何变得模糊。链接允许使用任何所需的一组平台模块来创建Java分发,并且不局限于平台供应商提供的选项。
13.6 压缩大小
可以通过运行jlink –list-plugins来获得所有当前可用插件的概述。
13.7 提升性能
默认启用的一种优化是预先创建平台模块描述符缓存,其主要想法是在构建映像时确切知道哪些平台模块是模块图的一部分。如果在链接时创建了模块描述符的组合表示,那么就没有必要在运行时单独解析原始模块描述符了,从而减少JVM启动时间。
