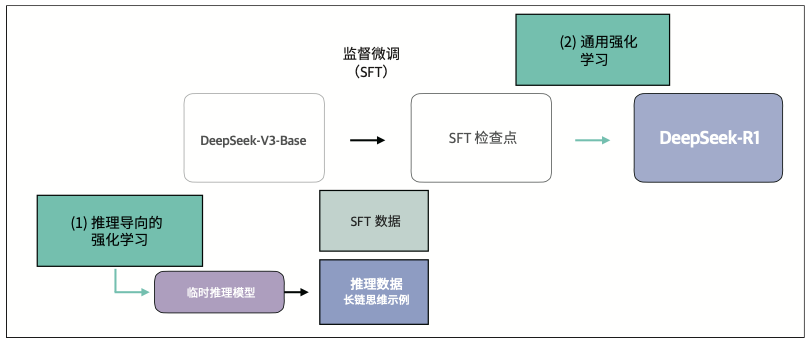
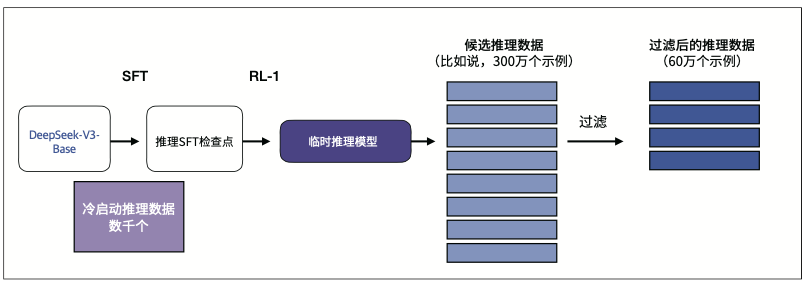
前言
GitHub仓库(https://github.com/HandsOnLLM/Hands-On-Large-Language-Models)
第一部分 理解语言模型
第1章 大语言模型简介
1.2 语言人工智能的近期发展史
1.2.2 用稠密向量嵌入获得更好的表示
如果两个词各自的相邻词集合有更大的交集,它们的词嵌入向量就会更接近,反之亦然。
1.2.3 嵌入的类型
有许多类型的嵌入,如词嵌入和句子嵌入,它们用于表示不同层次的抽象(词与句子)。
词袋模型在文档层面创建嵌入,因为一个嵌入表示的是整个文档。相比之下,word2vec为每个词生成一个嵌入。
1.2.4 使用注意力机制编解码上下文
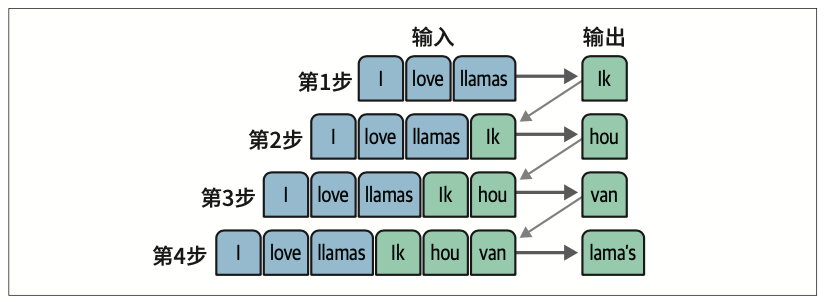
该架构中的每个步骤都是自回归(auto-regressive)的。如图1-12所示,在生成下一个词时,该架构需要使用所有先前生成的词作为输入。
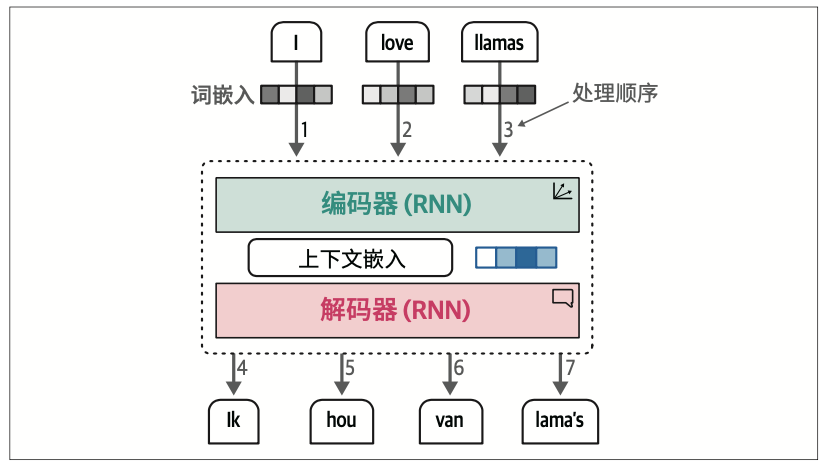
这种上下文嵌入方式存在局限性,因为它仅用一个嵌入向量来表示整个输入,使得处理较长的句子变得困难。
注意力机制通过选择性地聚焦于句子中最关键的词,来突出其重要性。
通过在解码步骤中添加这些注意力机制,RNN可以为输入序列中的每个词生成与潜在输出相关的信号。这并不仅仅是将上下文嵌入传递给解码器,而是传递所有输入词的隐藏状态。
然而,这种序列特性不利于模型训练过程中的并行化。
1.2.5 “Attention Is All You Need”
Transformer … 它完全基于注意力机制,摒弃了此前提到的RNN。与RNN相比,Transformer支持并行训练,这大大加快了训练速度。
在Transformer中,编码和解码组件相互堆叠,如图1-16所示。这种架构仍然是自回归的,每个新生成的词都被模型用于生成下一个词。
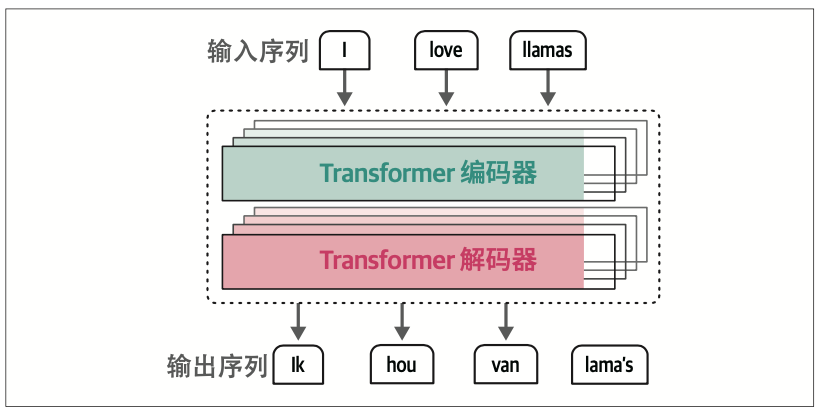
编码器和解码器块都围绕着注意力机制展开,而不是利用带有注意力特征的RNN。
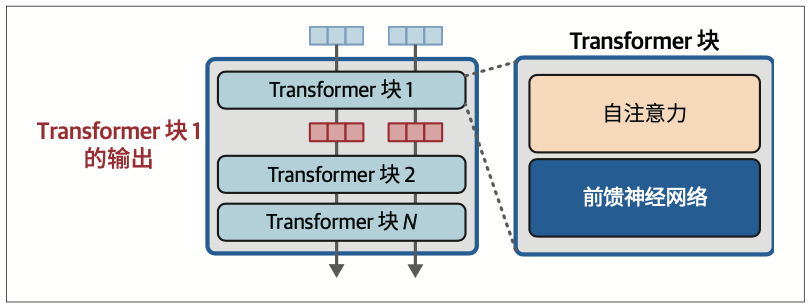
Transformer中的编码器块由两部分组成:自注意力(self-attention)和前馈神经网络(feed-forward neural network),如图1-17所示。
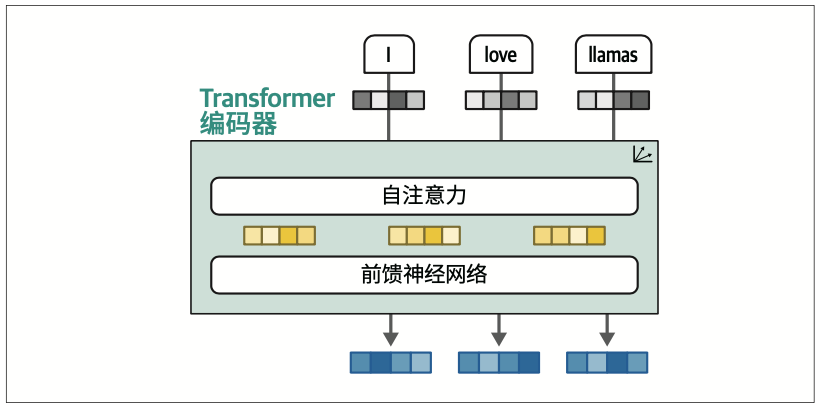
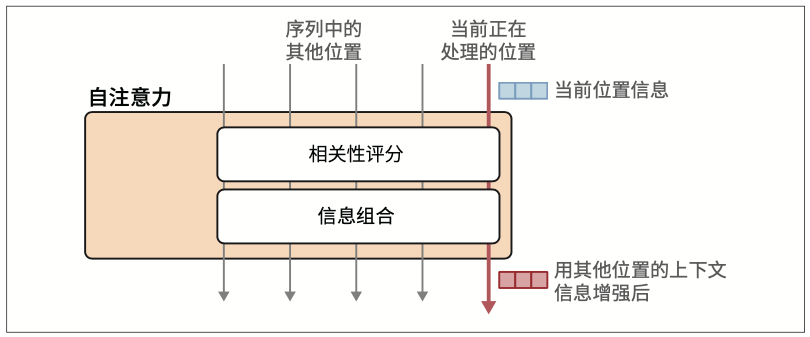
与之前的注意力方法相比,自注意力可以关注单个序列内部的不同位置,从而更高效且准确地表示输入序列
它可以一次性查看整个序列,而不是一次处理一个词元。
与编码器相比,解码器多了一个注意力层,用于关注编码器的输出(以便找到输入中相关的部分)。如图1-19所示
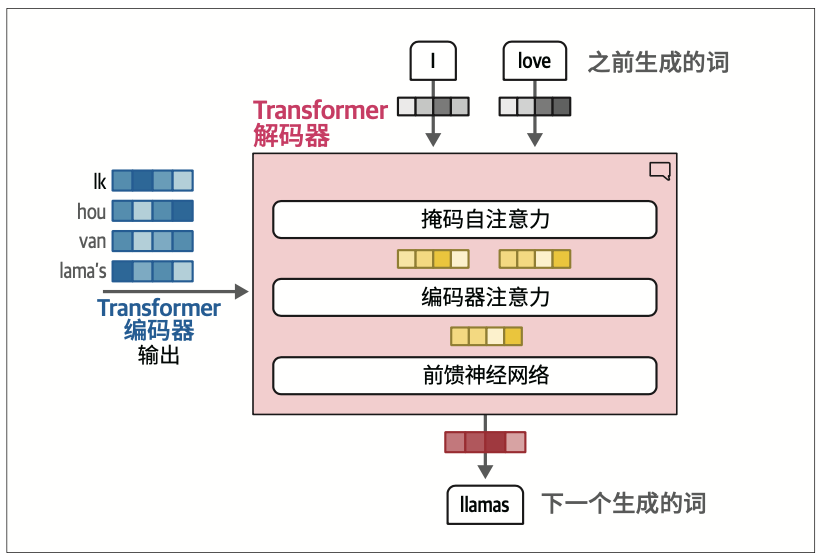
解码器中的自注意力层会掩码未来的位置,这样在生成输出时就只会关注之前的位置,从而避免信息泄露。
1.2.6 表示模型:仅编码器模型
原始的Transformer模型是一个编码器-解码器架构,虽然非常适合翻译任务,但难以用于其他任务,比如文本分类。
BERT(bidirectional encoder representations from Transformers,基于Transformer的双向编码器表示)
BERT是一个仅编码器架构,专注于语言表示。
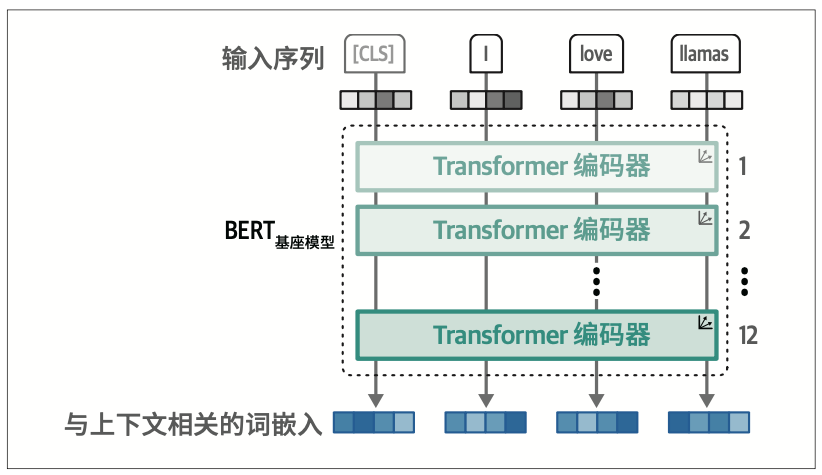
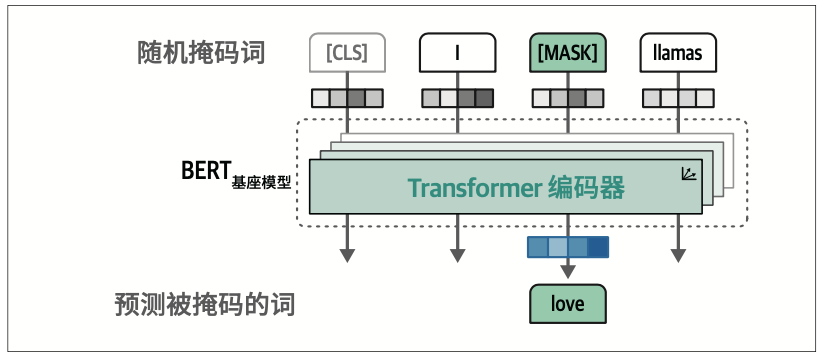
输入中包含一个附加词元——[CLS](分类词元),用于表示整个输入。通常,我们使用[CLS]词元作为输入嵌入(input embedding),用于在特定任务(如分类)上进行模型微调。
这些堆叠起来的编码器很难训练,因此BERT采用了一种被称为掩码语言建模(masked language modeling)的技术来解决这个问题
该方法会掩码部分输入,让模型预测被掩码的部分。这样的预测任务虽然困难,但能让BERT为输入序列创建更准确的(中间)表示。
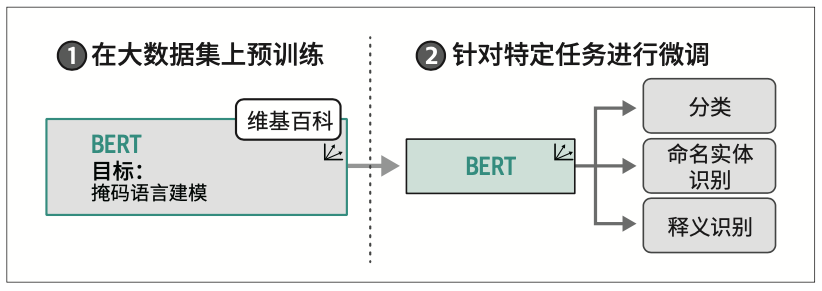
这种架构和训练过程使BERT及相关架构在表示依赖上下文的文本方面表现十分出色。BERT类模型通常用于迁移学习(transfer learning),这包括首先针对语言建模进行预训练(pretraining),然后针对特定任务进行微调(fine-tuning)。例如,通过在整个维基百科的文本数据上训练BERT,它学会了理解文本的语义和上下文性质。然后,如图1-23所示,我们可以使用该预训练模型,针对特定任务(如文本分类)进行微调。
BERT类模型架构在处理过程中的几乎每一步都会生成嵌入,这使得BERT模型成为通用特征提取器,无须针对特定任务进行微调。
在本书中,我们将仅编码器模型称为表示模型(representation model),以区别于仅解码器模型;将仅解码器模型称为生成模型(generative model)。
需要注意的是,表示模型和生成模型的主要区别并不在于底层架构和工作方式。表示模型主要关注语言的表示,例如创建嵌入,而通常不生成文本;相比之下,生成模型主要关注生成文本,通常不会被训练用于生成嵌入。
1.2.7 生成模型:仅解码器模型
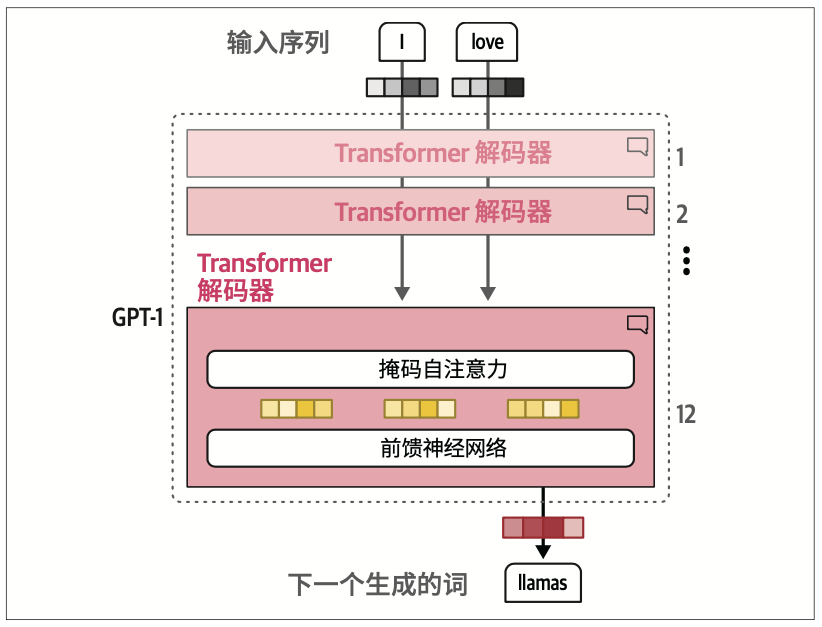
由于这些模型的自回归特性,当生成新的词元时,当前的上下文长度会增加。
1.2.8 生成式AI元年
除了广受欢迎的Transformer架构外,还出现了一些有前景的新架构,如Mamba和RWKV。这些新型架构试图在达到Transformer级别的性能的同时,还有额外的优势,比如更大的上下文窗口或更快的推理速度。
1.4 LLM的训练范式
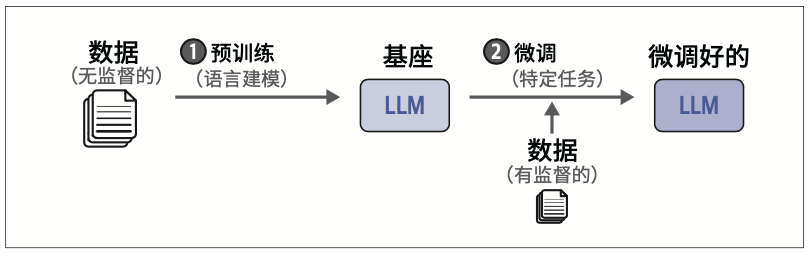
可以添加微调步骤来进一步使模型与用户偏好对齐。
1.5 LLM的应用
可以利用仅编码器模型来执行分类本身,并使用仅解码器模型来标记主题
1.9 生成你的第一段文本
当你使用LLM时,需要加载两个模型:
- 生成模型本身
- 其底层的分词器(tokenizer)
分词器负责在将输入文本送入生成模型之前,将其分割成词元。
第2章 词元和嵌入
2.1 LLM的分词
2.1.2 下载和运行LLM
注意空格字符不用单独的词元表示,代表词的一部分的词元(如izing和ic)在开头有一个特殊的隐藏字符,表示它们与文本中前面的词元相连。没有这个特殊字符的词元前面则都被视为有一个空格。
2.1.3 分词器如何分解文本
决定分词器如何分解输入提示词的因素主要有三个。
首先,在模型设计时,模型创建者会选择一种分词方法。流行的方法包括字节对编码(BPE,byte pair encoding,广泛用于GPT模型)和WordPiece(用于BERT模型)。
其次,在选择方法之后,我们需要做出一些分词器设计选择,如词表大小和使用哪些特殊词元。
最后,分词器需要在特定数据集上进行训练,以建立能最好地表示该数据集的词表。
2.1.4 词级、子词级、字符级与字节级分词
词级分词的一个挑战是,分词器可能无法处理分词器训练完成之后才出现在数据集中的新词。
这个问题可以通过子词级分词来解决
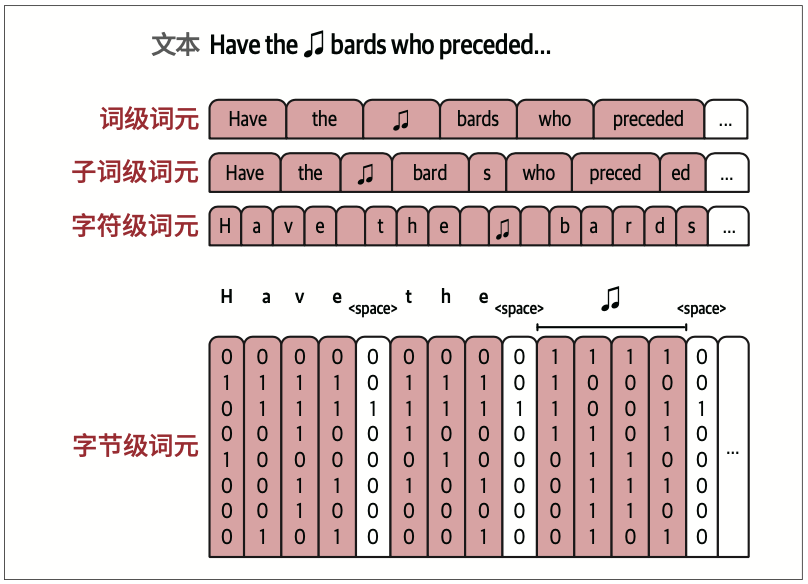
相比字符级分词,子词级分词可以在Transformer模型有限的上下文长度内,容纳更多文本。
某些子词分词器也会在其词表中将字节作为词元,在遇到无法用其他方式表示的字符时,这是最终备选方案
2.1.5 比较训练好的LLM分词器
分词器中出现的词元是由三个主要因素决定的:分词方法、用于初始化分词器的参数和特殊词元,以及用于训练分词器的数据集。
专门的模型(如代码生成模型)通常需要专门的分词器。
特殊词元:
- unk_token [UNK]
未知词元- sep_token [SEP]
分隔符词元- pad_token [PAD]
填充词元- cls_token [CLS]
分类词元- mask_token [MASK]
掩码词元
BERT分词器有两个版本:大小写敏感(保留大写字母)的版本和大小写不敏感(所有大写字母先转换为小写字母)的版本。
[CLS] 和[SEP] 是用于包裹输入文本的功能性词元,各有其用途。[CLS] 代表分类(classification),因为它有时被用于句子分类。[SEP] 代表分隔符(separator),用于在某些需要向模型传递两个句子的应用中分隔句子
一个能够使用单个词元来表示连续四个空白字符的模型,更适合处理Python代码数据集。
对话词元。随着对话LLM于2023年流行,LLM的对话特性开始成为其主要应用。分词器通过添加表示对话轮次和对话者角色的词元来适应这一趋势。这些特殊词元包括:
- <|user|>
- <|assistant|>
- <|system|>
2.1.6 分词器属性
有三大类设计上的选择决定了分词器如何分解文本:分词方法、用于初始化分词器的参数以及训练分词器的目标数据所在的领域。
2.2 词元嵌入
2.2.1 语言模型为其分词器的词表保存嵌入
在训练开始之前,这些向量会像模型的其他权重一样被随机初始化,但训练过程会为它们分配值,使其能够执行有意义的行为。
2.2.2 使用语言模型创建与上下文相关的词嵌入
与使用静态向量表示每个词元或词不同,语言模型会创建与上下文相关(contextualized)的词嵌入
2.3 文本嵌入(用于句子和整篇文档)
文本嵌入——用单个向量来表示长度超过一个词元的文本片段。
2.4 LLM之外的词嵌入
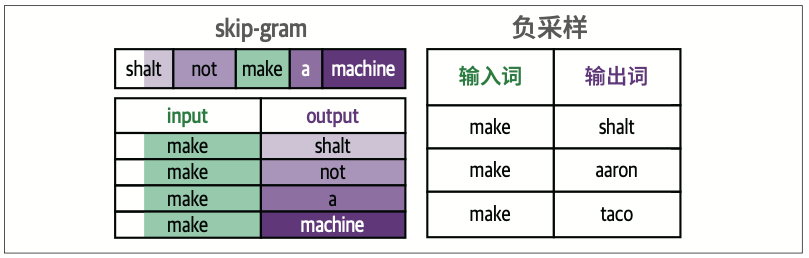
2.4.2 word2vec算法与对比训练
嵌入向量是通过分类任务生成的。这种任务用于训练神经网络,以预测词是否经常出现在相同的上下文中
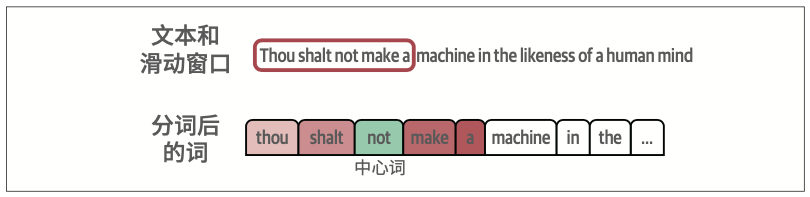
word2vec的两个主要概念(见图2-14):skip-gram,选择相邻词的方法;负采样(negative sampling),通过从数据集中随机采样来添加负例。
2.6 小结
分词器设计中有三个主要决策点:分词器算法(如BPE、WordPiece、SentencePiece)、分词参数(包括词表大小、特殊词元、大小写处理策略和不同语言的处理)以及用于训练分词器的数据集。
第3章 LLM的内部机制
3.1 Transformer模型概述
3.1.1 已训练Transformer LLM的输入和输出
每个词元生成步骤都是模型的一次前向传播(在机器学习中,前向传播指的是输入进入神经网络并流经计算图,最终在另一端产生输出所需的计算过程)。
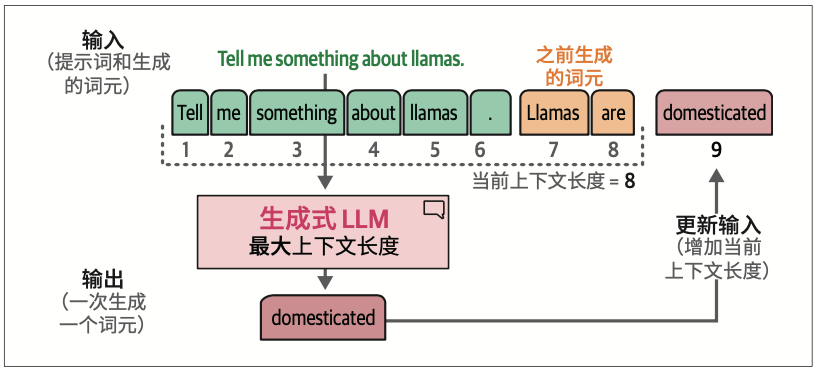
在生成当前词元后,我们将输出词元追加到输入提示词的末尾,从而调整下一次生成的输入提示词。
在机器学习中,有一个专门的词用来描述使用早期预测来进行后续预测的模型(例如,模型使用生成的第一个词元来生成第二个词元),这类模型被称为自回归模型(autoregressive model)。这就是为什么文本生成式LLM也被称为自回归模型。
这一名称通常用于区分文本生成模型与像BERT这样的非自回归的文本表示模型。
3.1.2 前向传播的组成
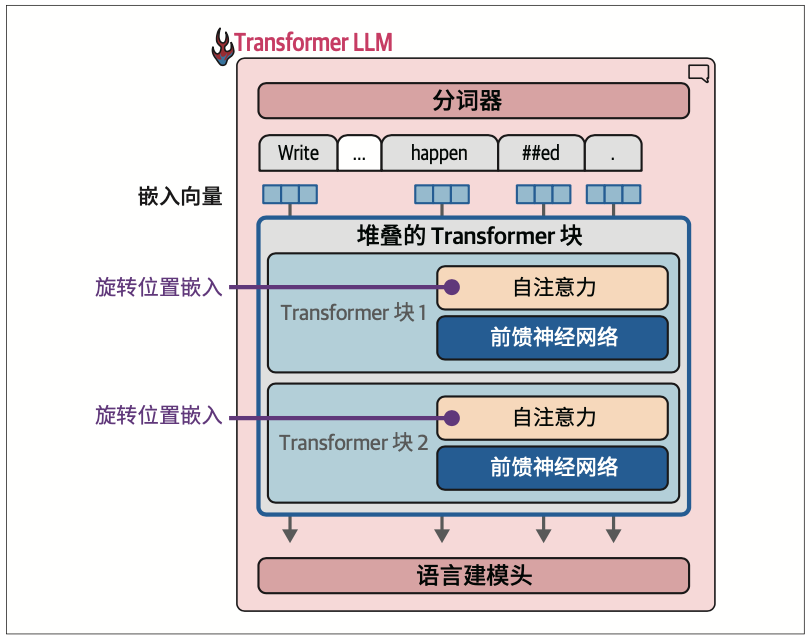
除了循环之外,前向传播还有两个关键的内部组件:分词器和语言建模头(language modeling head,LM head)。
分词器之后是神经网络,由一系列Transformer块堆叠而成,负责执行所有的处理工作。在这些堆叠的块之后是语言建模头,它将Transformer块的输出转换为预测下一个词元的概率分数。
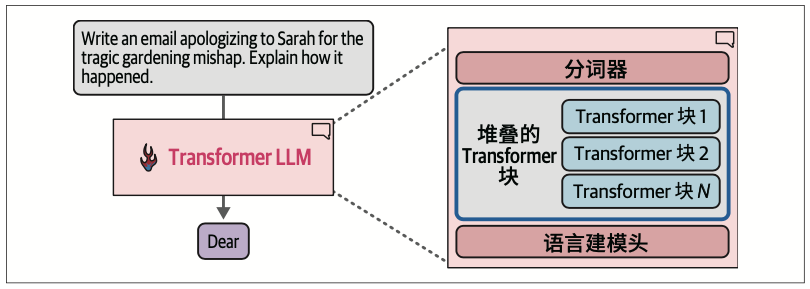
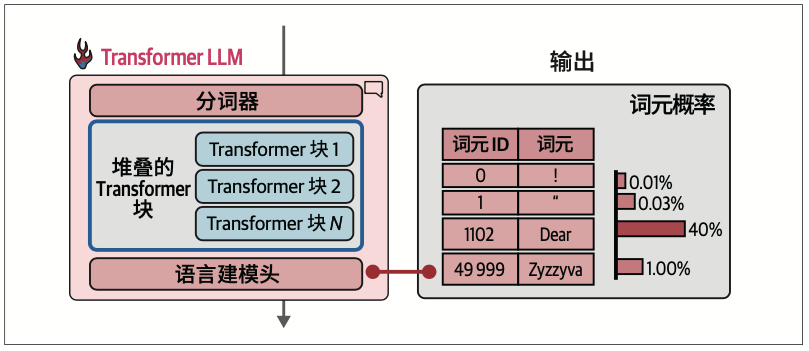
语言建模头本身是一个简单的神经网络层。它可以连接到堆叠的Transformer块上的多种可能的“头”之一,用于构建不同类型的系统。其他类型的Transformer头包括序列分类头和词元分类头。
3.1.3 从概率分布中选择单个词元(采样/解码)
从概率分布中选择单个词元的方法称为解码策略。
最简单的解码策略就是始终选择概率分数最高的词元。但在实践中,对于大多数使用场景来说,这种方法往往无法产生最佳输出。一个更好的方法是引入一些随机性,有时选择概率第二高或第三高的词元。用统计学家的话来说,这种思想就是根据概率分数对概率分布进行采样。
每次都选择概率分数最高的词元的策略被称为贪心解码。这就是在LLM中将温度(temperature)参数设为零时会发生的情况。
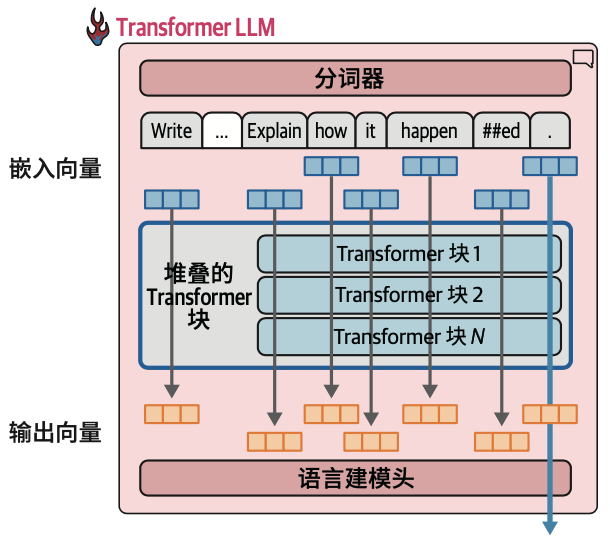
3.1.4 并行词元处理和上下文长度
Transformer最引人注目的特性之一是,它比之前的语言处理神经网络架构更适合并行计算。
当前的Transformer模型对一次可以处理的词元数量有限制,这个限制被称为模型的上下文长度。一个具有4K上下文长度的模型只能处理4000个词元,也就是只有4000条这样的流。
对于文本生成来说,只有最后一条计算流的输出结果用于预测下一个词元。当语言建模头计算下一个词元的概率时,该输出向量是唯一的输入。
你可能会疑惑,既然最终只用到最后一个词元的输出,为什么还需要所有的计算流?答案是,之前的流的计算结果是最终的流所必需的。没错,我们不会使用它们的最终输出向量,但会在每个Transformer块的注意力机制中使用其早期输出。
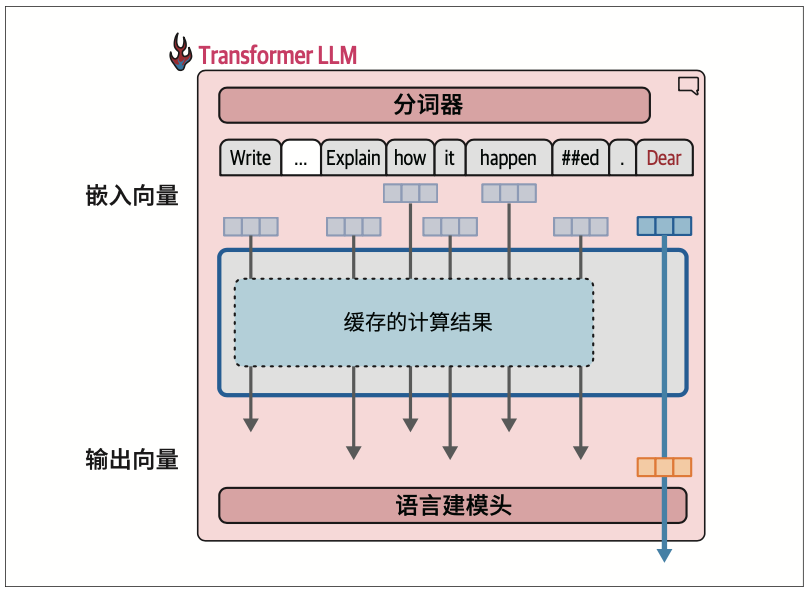
3.1.5 通过缓存键−值加速生成过程
回想一下,在生成第二个词元时,我们只是简单地将输出词元追加到输入的末尾,然后再次通过模型进行前向传播。如果模型能够缓存之前的计算结果(特别是注意力机制中的一些特定向量),就不需要重复计算之前的流,而只需要计算最后一条流了。这种优化技术被称为键-值(key-value,KV)缓存,它能显著加快生成过程。
3.1.6 Transformer块的内部结构
要想成功训练一个LLM,需要让它记住大量信息。但它并不仅仅是一个大型数据库。记忆只是生成出色文本的众多要素之一。模型能够利用相同的机制在数据点之间进行插值,识别更复杂的模式,从而实现泛化,这意味着它能够很好地处理以前从未见过、不在训练数据集中的输入。
原始语言模型(如GPT-3)对用户来说很难用,因此语言模型需要通过指令微调和基于人类偏好与反馈的微调,来满足人们对模型输出的期望。
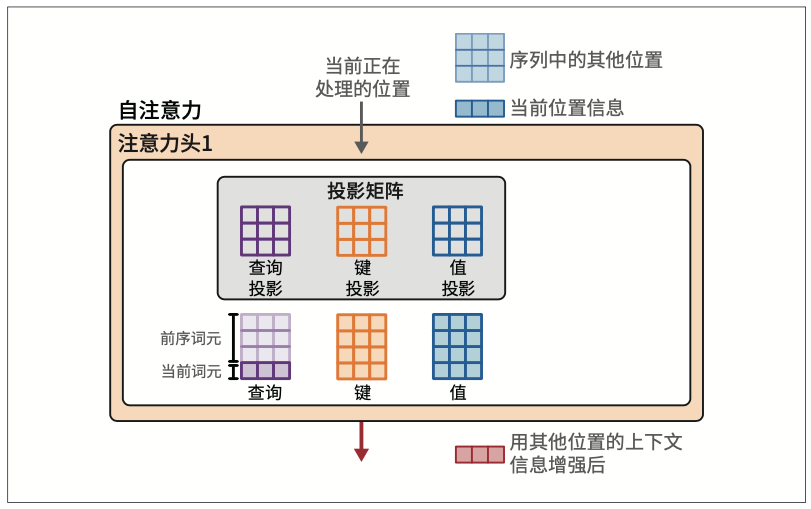
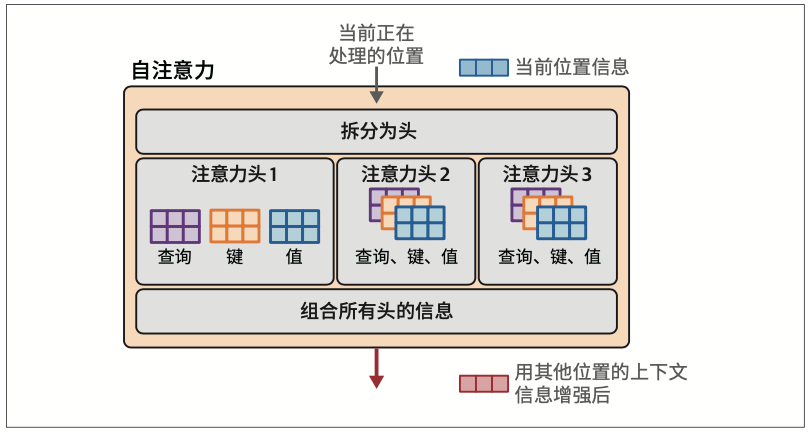
为了赋予Transformer更强大的注意力能力,注意力机制被复制多份,并行执行。这些并行的注意力执行过程被称为注意力头(attention head)。这提高了模型对输入序列中复杂模式的建模能力,使其能够同时关注不同的模式。
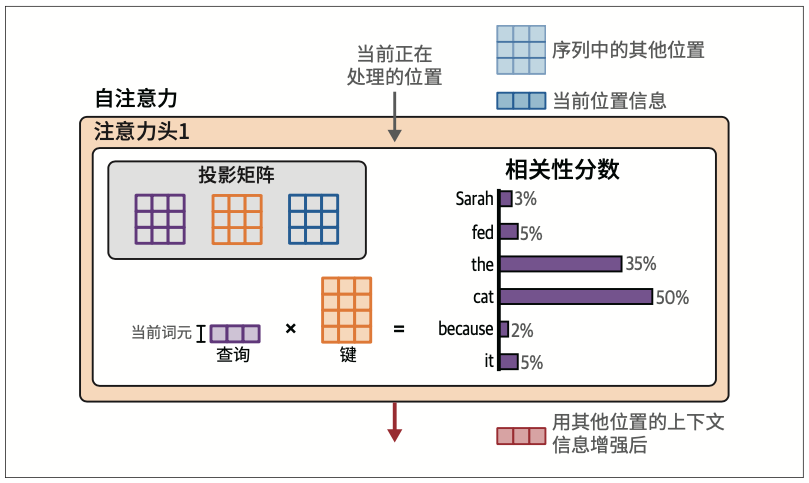
注意力首先将输入与投影矩阵相乘,得到三个新矩阵,称为查询矩阵、键矩阵和值矩阵。这些矩阵包含了投影到三个不同空间的输入词元信息,用于执行注意力的两个步骤:
- 相关性评分
- 信息组合
3.2 Transformer架构的最新改进
3.2.1 更高效的注意力机制
Transformer的自注意力层是学术界最关注的部分。这是因为注意力计算是整个过程中计算开销最大的部分。
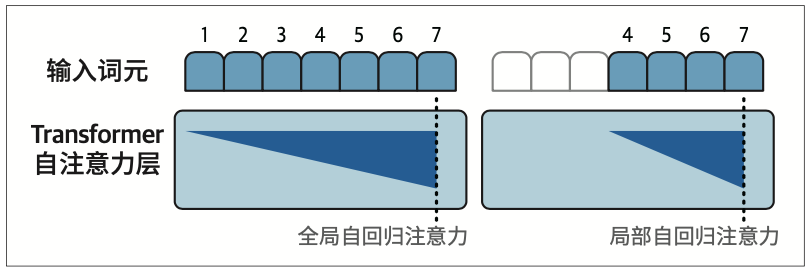
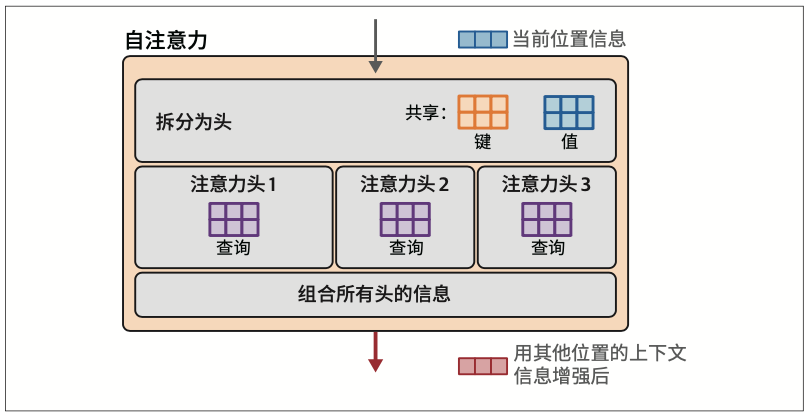
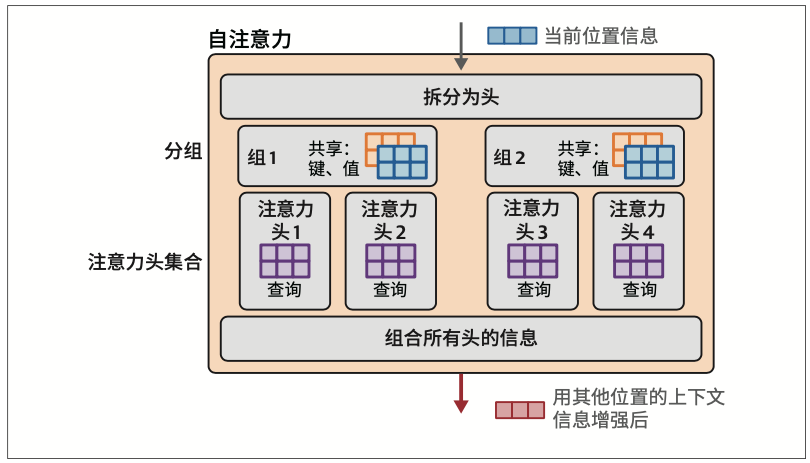
- 优化注意力机制:从多头到多查询再到分组查询
Flash Attention是一种广受欢迎的方法和实现,可以显著提升GPU上Transformer LLM的训练和推理速度。它通过优化GPU共享内存(GPU’s shared memory,SRAM)和高带宽内存(high bandwidth memory,HBM)之间的数据加载和迁移来加速注意力计算。
3.2.2 Transformer块
Transformer块的两个主要组成部分是自注意力层和前馈神经网络层。如图3-29所示,深入Transformer块的细节,还能发现残差连接和层归一化操作。
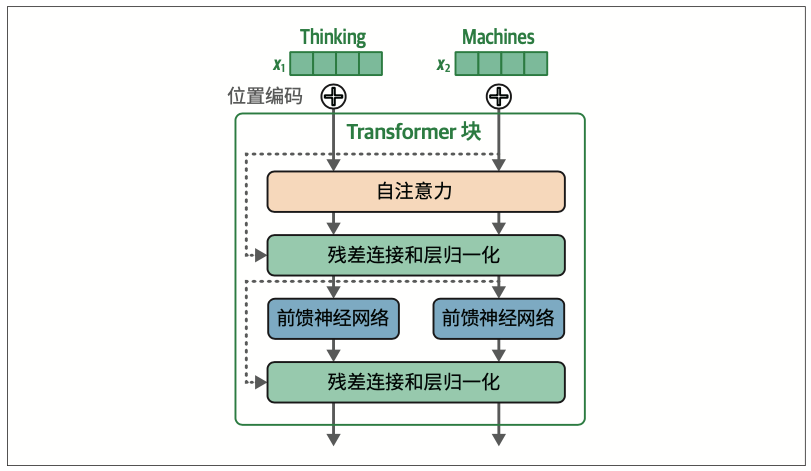
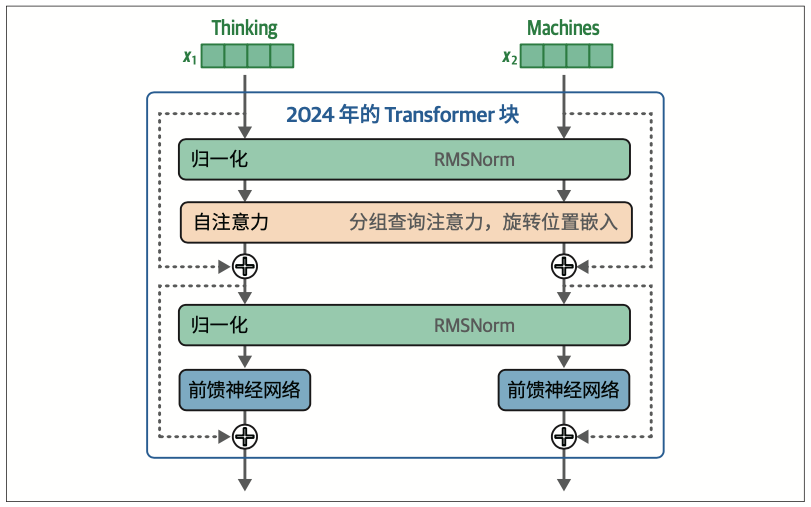
在这个版本的Transformer块中,我们看到的一个区别是归一化发生在自注意力层和前馈神经网络层之前。据称,这种方式可以减少所需的训练时间
这里对归一化的另一个改进是使用RMSNorm,它比原始Transformer中使用的LayerNorm更简单、更高效(参见论文“Root Mean Square Layer Normalization”)。
最后,相比原始Transformer的ReLU激活函数,现在像SwiGLU这样的新变体(参见论文“GLU Variants Improve Transformer”)更为常见。
3.2.3 位置嵌入:RoPE
位置嵌入自原始Transformer以来一直是关键组件。它们使模型能够跟踪序列/句子中词元/词的顺序,这是语言中不可或缺的信息来源。在过去几年提出的众多位置编码方案中,旋转位置嵌入(rotary position embedding,RoPE,参见论文“RoFormer: Enhanced Transformer with Rotary Position Embedding”)尤其值得关注。

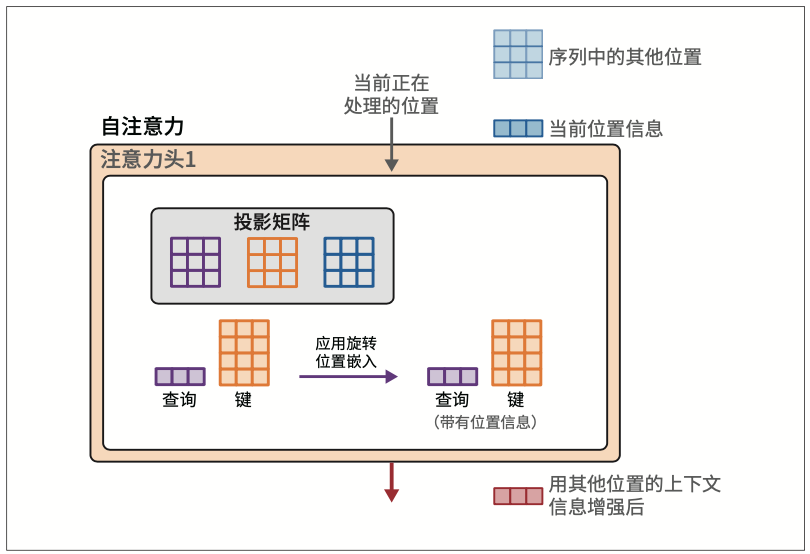
与在前向传播开始时添加的静态绝对嵌入不同,旋转位置嵌入是一种以捕获绝对和相对词元位置信息的方式来编码位置信息的方法,其思想的基础是嵌入空间中旋转的向量。在前向传播中,旋转位置嵌入是在注意力步骤中添加的,如图3-32所示。
在注意力步骤中,我们特意把位置信息混合到查询矩阵和键矩阵中。这个混合过程发生在我们将查询向量和键矩阵相乘,进行相关性评分之前,如图3-33所示。
3.3 小结
下面总结一下本章讨论的关键概念。
- Transformer LLM 每次生成一个词元。
- 生成的词元会被追加到提示词中,然后,这个更新后的提示词会再次被输入模型进行下一次前向传播,以生成下一个词元。
- Transformer LLM的三个主要组件是分词器、一系列Transformer块和语言建模头。
- 分词器包含模型的词元词表。模型中包含与这些词元相关联的词元嵌入。将文本分解成词元,然后使用这些词元的嵌入向量,是词元生成过程的第一步。
- 前向传播会依次经过所有阶段。
- 在处理接近尾声时,语言建模头会对下一个可能的词元进行概率评分。解码策略决定了在这一生成步骤中选择哪个实际词元作为输出(有时是概率最高的下一个词元,但并非总是如此)。
- Transformer表现出色的原因之一是它能够并行处理词元。每个输入词元都流入其独立的计算流(也称为处理路径)。这些流的数量就是模型的“上下文长度”,代表模型可以处理的最大词元数量。
- 由于Transformer LLM通过循环来一次生成一个词元的文本,因此缓存每个步骤的处理结果是一种很好的策略,这样可以避免重复处理工作(这些结果以各种矩阵的形式存储在层中)。
- 大部分处理发生在Transformer块中。这些块由两个组件组成,其中一个是前馈神经网络,它能够存储信息,并根据训练数据进行预测和插值。
- Transformer块的另一个主要组件是自注意力。自注意力整合了上下文信息,使模型能够更好地捕捉语言的细微差别。
- 注意力过程分为两个主要步骤:相关性评分;信息组合。
- Transformer的自注意力层并行执行多个注意力操作,每个操作都发生在注意力头内,它们的输出被聚合成自注意力层的输出。
- 通过在所有注意力头或一组注意力头(分组查询注意力)之间共享键矩阵和值矩阵,可以加速注意力计算。
- Flash Attention等方法通过优化在GPU不同显存系统上的操作方式来加速注意力计算。
第二部分 使用预训练语言模型
第4章 文本分类
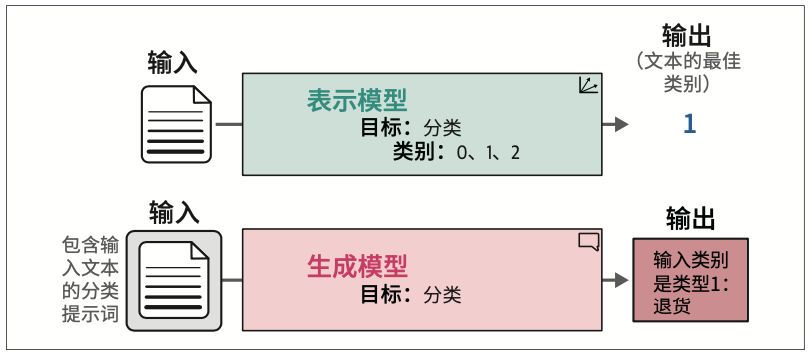
4.2 使用表示模型进行文本分类
使用预训练表示模型进行分类,通常有两种方式:要么使用特定任务模型,要么使用嵌入模型。
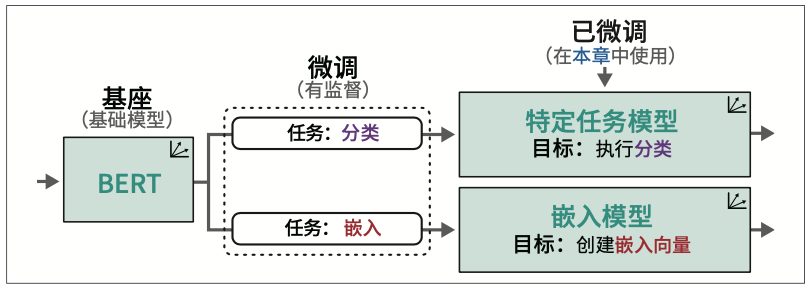
4.4 使用特定任务模型
根据预测结果是正确(True)还是错误(False),以及预测的分类是正例(Positive,此处即正面评论)还是负例(Negative,此处即负面评论),有四种组合。我们可以将这些组合用矩阵形式表示,通常称为混淆矩阵(confusion matrix),如图4-8所示。
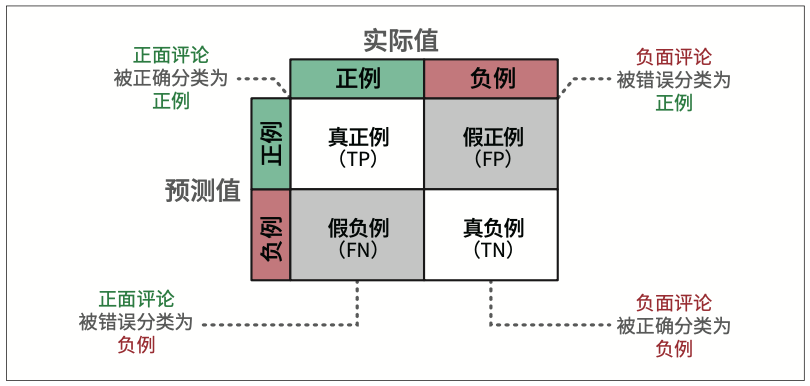
四个常用的指标:精确率、召回率、准确率和F1分数。

4.5 利用嵌入向量的分类任务
4.5.1 监督分类
我们不直接使用表示模型进行分类,而是使用嵌入模型生成特征。这些特征随后可以输入到分类器中,从而创建一个如图4-10所示的两步法。
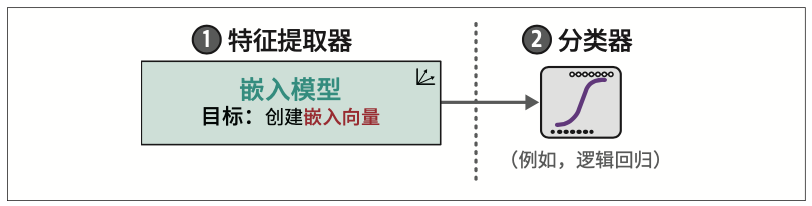
这种分离架构的一个主要优点是,我们不需要微调嵌入模型,耗费大量资源,而是可以在CPU上训练逻辑回归等传统分类器。
4.5.2 没有标注数据怎么办
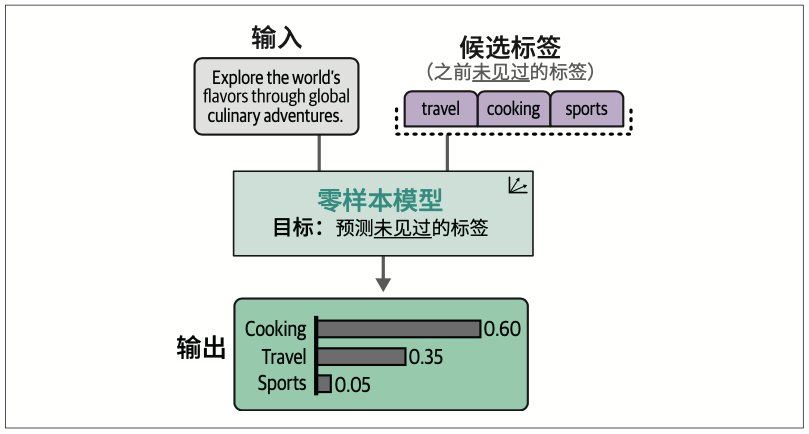
要借助嵌入向量执行零样本分类,我们可以使用一个巧妙的方法:基于标签应该表示的内容来描述它们。
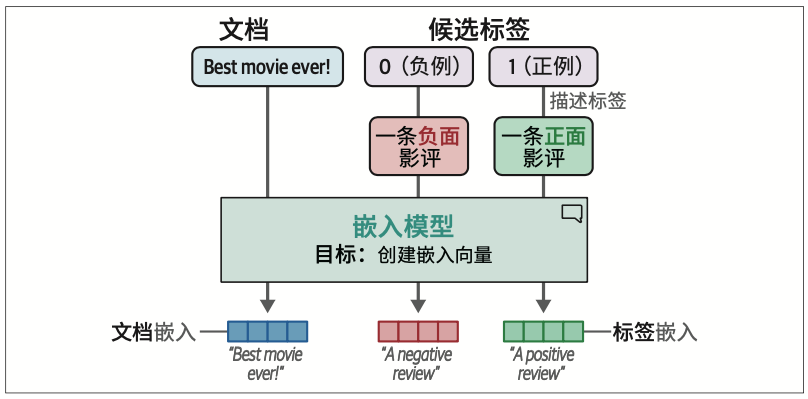
余弦相似度是两个向量夹角的余弦值,通过嵌入向量的点积除以它们长度的乘积来计算
4.6 使用生成模型进行文本分类
生成模型接收文本输入并生成文本,因此有时称其为序列到序列模型是很恰当的。
迭代改进提示词以获得期望的输出的过程被称为提示工程(prompt engineering)。
4.6.1 使用T5
在本书中,我们主要探讨仅编码器(表示)模型(如BERT)和仅解码器(生成)模型(如ChatGPT)。然而,正如第1章所讨论的,原始Transformer架构实际上由编码器-解码器架构组成。与仅解码器模型一样,这些编码器-解码器模型也是序列到序列模型,通常被归类为生成模型。
T5(Text-to-Text Transfer Transformer,文本到文本迁移Transformer)模型
其架构与原始Transformer类似,将12个解码器和12个编码器堆叠在一起
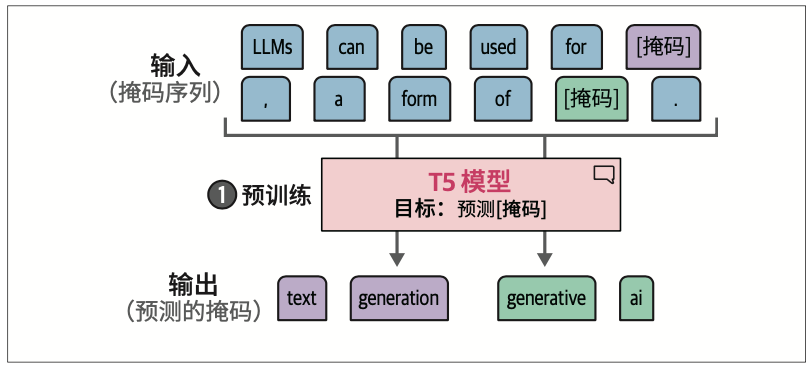
T5系列模型首先使用掩码语言建模进行预训练。在训练的第一步,
预训练过程不是仅对单个词元进行掩码,而是对词元集合(也称词元跨度,token span)整体进行掩码。
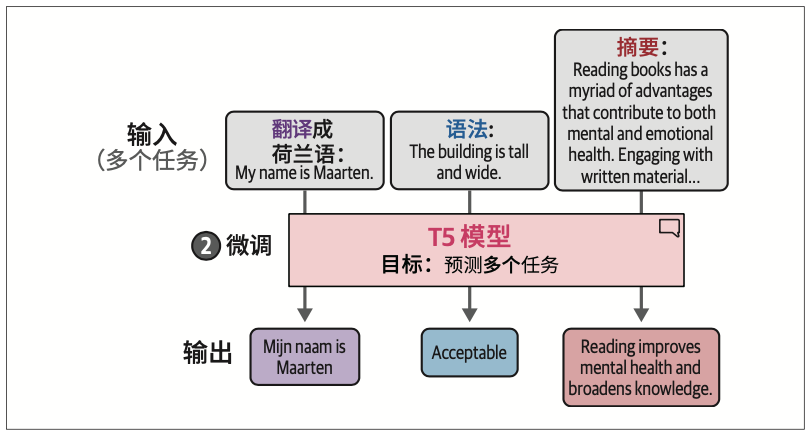
在训练的第二步,即微调基础模型过程中,真正的“魔法”才开始发生。模型不是针对单个特定任务进行微调,而是将每个任务转换为序列到序列任务并同时进行训练。如图4-21所示,这使得模型可以在多种任务上进行训练。
4.6.2 使用ChatGPT进行分类
使用偏好数据而非指令数据的一个主要优势在于,它能够体现细微的差别。通过展示好的输出和更好的输出之间的差异,生成模型学会了生成符合人类偏好的文本。
指数退避(exponential backoff),也就是每次遇到速率限制错误时执行短暂的休眠,然后重试未成功的请求。每当再次失败时,休眠时间会增加,直到请求成功或达到最大重试次数。
第5章 文本聚类和主题建模
文本聚类旨在基于文本的语义内容、含义和关系对相似文本进行分组。
5.1 ArXiv文章:计算与语言
ArXiv是一个主要面向计算机科学、数学和物理领域的开放的学术文章平台。
5.2 文本聚类的通用流程
当前比较流行的通用流程主要包含以下三个步骤(每一步对应一种算法):
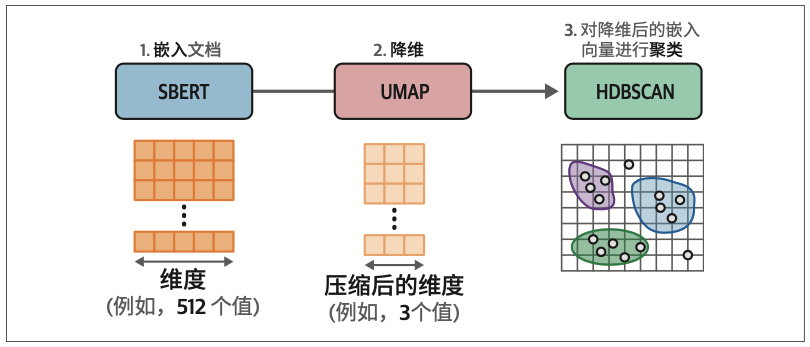
第一步,使用嵌入模型(embedding model)将输入文档转换为嵌入向量;
第二步,使用降维模型(dimensionality reduction model)将嵌入向量降至更低维度空间;
第三步,使用聚类模型(cluster model)对降维后的嵌入向量进行聚类。
5.2.1 嵌入文档
选择为语义相似度任务优化的嵌入模型对聚类任务特别重要
5.2.2 嵌入向量降维
高维数据对许多聚类技术来说是一个难题,因为识别有意义的聚类变得更加困难。我们可以通过降维来解决这个问题。
主成分分析(Principal Component Analysis,PCA)以及统一流形逼近和投影(Uniform Manifold Approximation and Projection,UMAP)是著名的降维方法。
需要注意的是,降维技术并非完美无缺。它们无法完美地将高维数据压缩到低维表示中。这个过程总是会损失一些信息。因此,需要在降维和保留尽可能多的信息之间找到平衡点。
通常,5和10之间的值能很好地捕捉高维全局结构。
5.2.3 对降维后的嵌入向量进行聚类
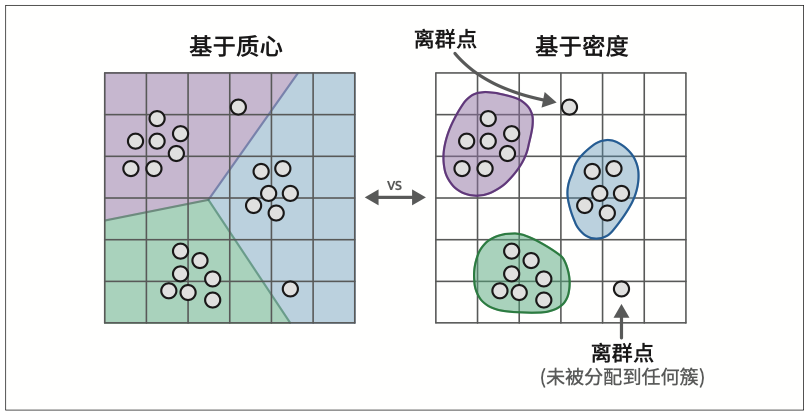
一个常见的基于密度的算法是HDBSCAN(Hierarchical Density-Based Spatial Clustering of Applications with Noise,具有噪声的分层密度空间聚类)。HDBSCAN是聚类算法DBSCAN的层次化变体,它无须显式指定簇的数量就能发现密集的(微型)簇。作为一种基于密度的方法,HDBSCAN还可以检测数据中的离群点,即不属于任何簇的数据点。这些离群点不会被分配或强制归属于任何簇,换句话说,它们会被忽略。
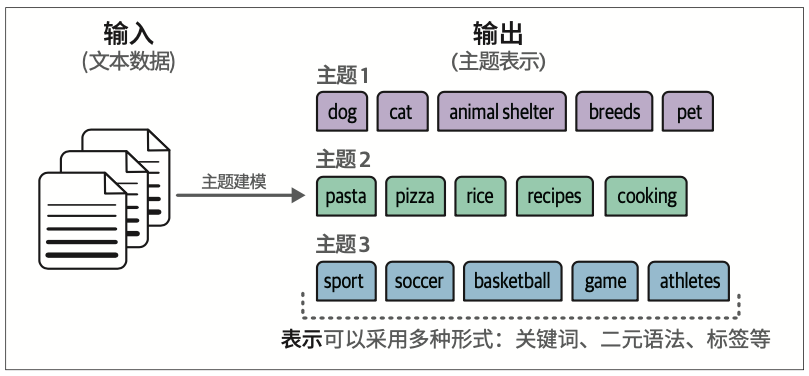
5.3 从文本聚类到主题建模
这种在文本数据集合中寻找主题或潜在语义的思路,通常被称为主题建模。
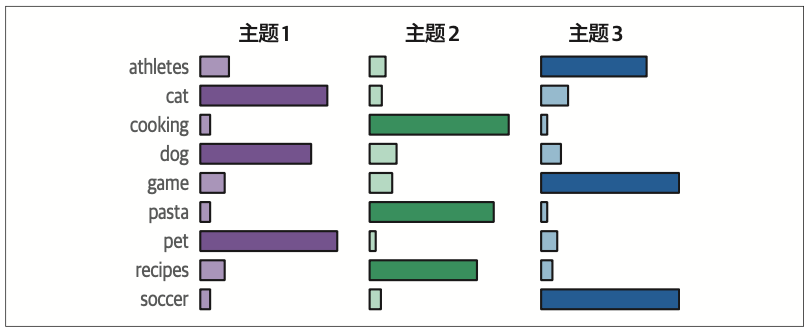
经典方法,如潜在狄利克雷分配(latent Dirichlet allocation,LDA),假设每个主题都由语料库词表中词的概率分布来表示。图5-10展示了词表中的每个词是如何根据其与每个主题的相关性被评分的。
这些经典方法通常使用词袋技术提取文本数据的主要特征,而没有考虑词和短语的上下文及含义。
5.3.1 BERTopic:一个模块化主题建模框架
BERTopic是一种主题建模技术,它利用语义相似的文本聚类来提取各种类型的主题表示。
BERTopic使用基于类的词频-逆文档频率(c-TF-IDF),来提升对单个簇更有意义的词的权重,降低在所有簇中都常用的词的权重。
结果是每个词的权重(IDF),我们可以将其与词频(c-TF)相乘得到加权值(c-TF-IDF)。

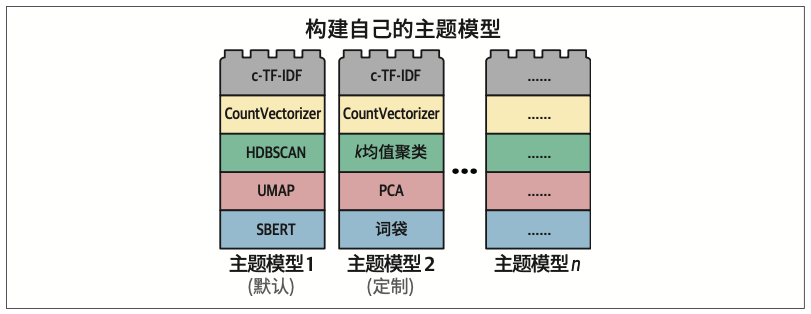
5.3.2 添加特殊的“乐高积木块”
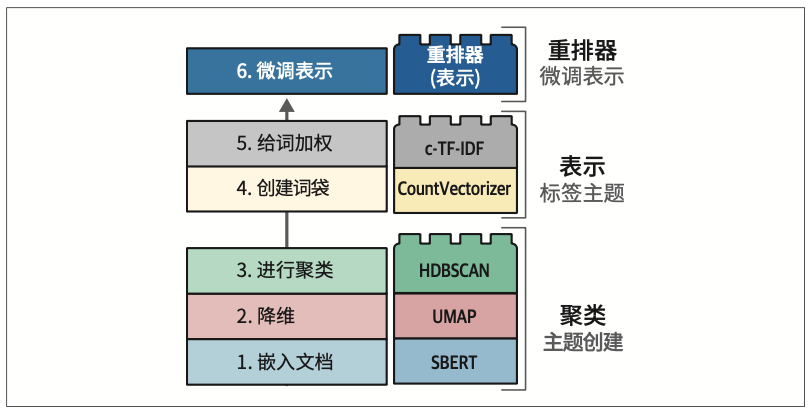
优化主题表示的过程只需要循环执行与主题数量相等的次数。
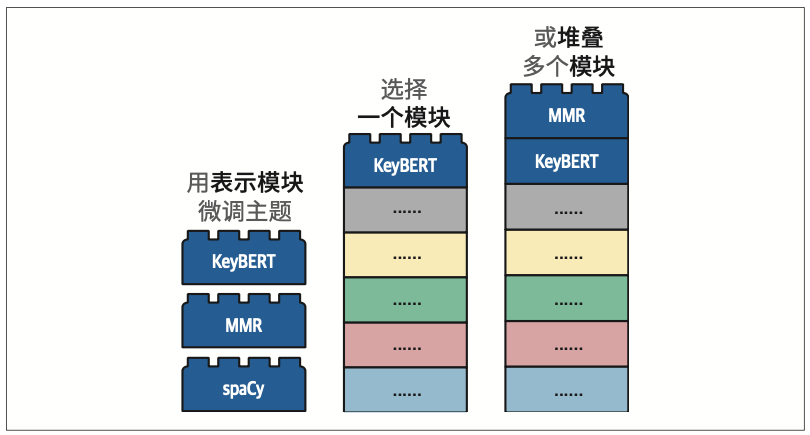
可以使用最大边际相关性(maximal marginal relevance,MMR)来使主题表示更加多样化。该算法的目的是找到一组相互之间具有差异性,但仍然与所比较的文档相关的关键词。
5.3.3 文本生成的“乐高积木块”
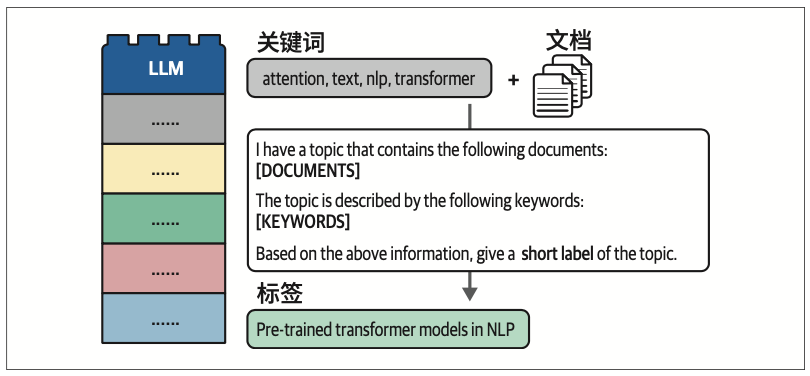
第6章 提示工程
6.1 使用文本生成模型
6.1.3 控制模型输出
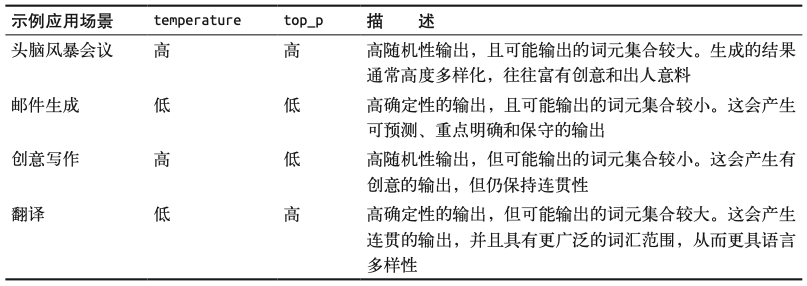
要使用temperature和top_p参数,我们需要设置do_sample=True。
top-p采样,也称为核采样(nucleus sampling),是一种控制LLM可以考虑哪些词元子集(核)的采样技术。它会考虑概率最高的若干词元,直到达到其累积概率限制。如果我们将top_p设置为0.1,模型会从概率最高的词元开始考虑,直到这些词元的累积概率达到0.1。如果我们将top_p设置为1,模型会考虑所有词元。
top_k参数精确控制LLM可以考虑的词元数量。如果你将其值更改为100,LLM将只考虑可能性最大的前100个词元。
6.2 提示工程简介
6.2.2 基于指令的提示词
在提示词的开头或结尾放置指令。特别是对于长提示词,中间的信息往往会被遗忘。LLM往往会关注提示词的开头部分(首位效应)或结尾部分(近因效应)。
6.3 高级提示工程
6.3.1 提示词的潜在复杂性
在教育目的下,使用ELI5(Explain like I’m 5,“向5岁的孩子解释”)通常很有帮助。
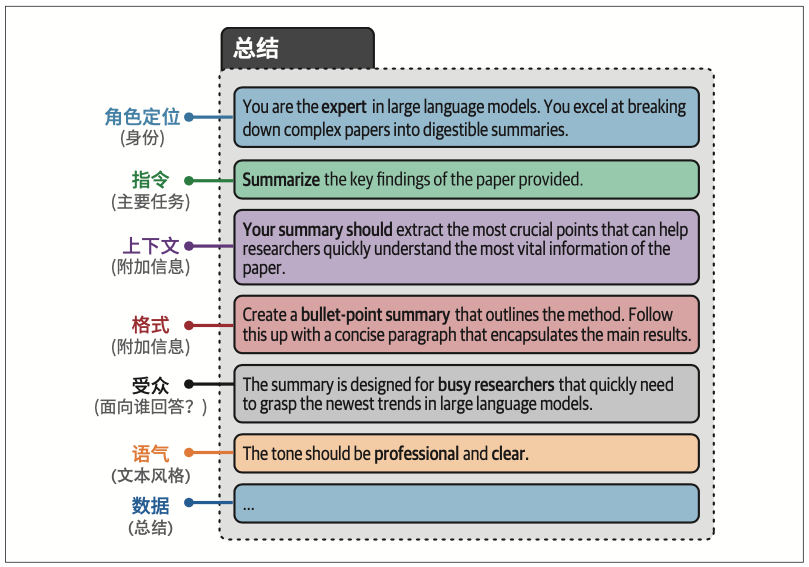
我们可以添加各种组件,包括创意性组件,比如情感刺激(例如,“这对我的职业生涯非常重要”)。
然而,请注意,某些提示词在不同的模型上效果不同,因为这些模型的训练数据不一样,或者它们的训练目标各异。
6.3.2 上下文学习:提供示例
我们可以为LLM提供我们想要完成的目标任务的具体示例。这通常被称为上下文学习(in-context learning)
6.3.3 链式提示:分解问题
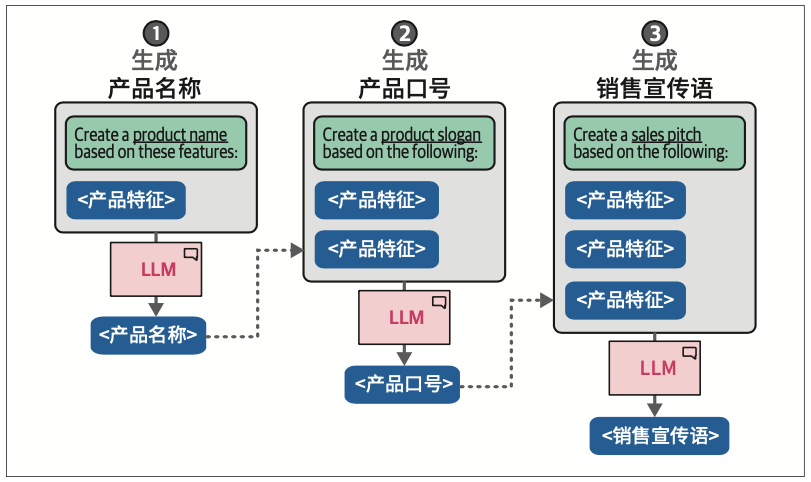
链式提示技术让LLM能够在每个独立问题上投入更多时间,而不是一次性解决整个问题。
虽然我们需要调用两次模型,但这样做的一个重要优势是我们可以为每次调用设置不同的参数。
6.4 使用生成模型进行推理
简单来说,我们的推理方法可以分为系统1和系统2两种思维过程。
系统1思维代表一种自动的、直觉的、几乎即时的过程。它与自动生成词元而没有任何自我反思行为的生成模型有相似之处。相比之下,系统2思维是一个有意识的、缓慢的、有逻辑性的过程,类似于头脑风暴和自我反思。
6.4.1 思维链:先思考再回答
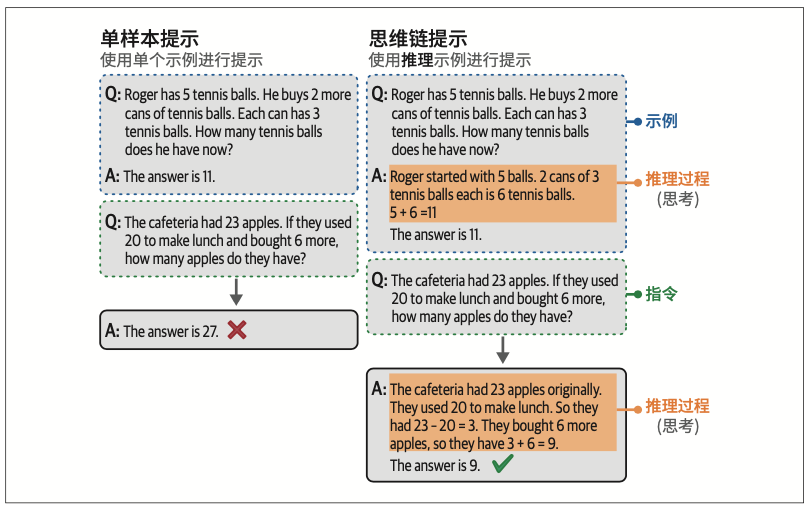
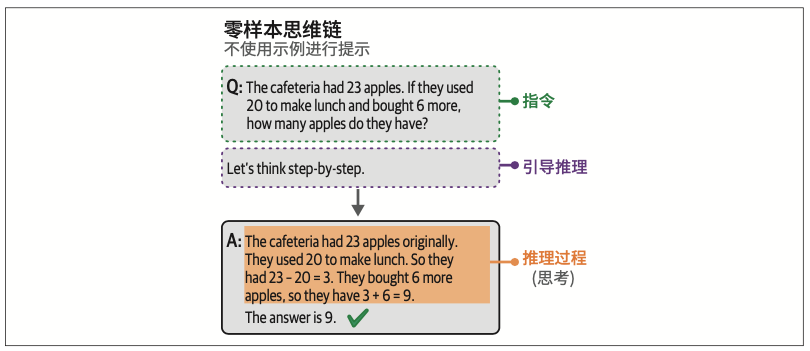
6.4.2 自洽性:采样输出
为了抵消这种随机性并提高生成模型的性能,研究人员引入了自洽性(self-consistency)的概念。这种方法会用相同的提示词向生成模型多次提问,并将占多数的结果作为最终答案。
6.4.3 思维树:探索中间步骤
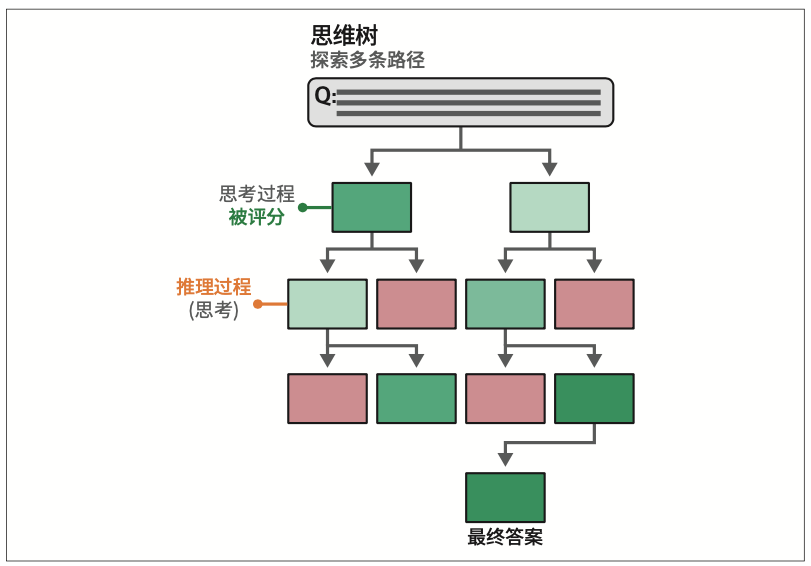
在这种提示技术中,我们无须多次调用生成模型,而是要求模型通过模拟多个专家之间的对话来模仿这种行为。这些专家会互相质疑,直到达成共识。以下是一个思维树提示词的示例:
# 零样本思维树 zeroshot_tot_prompt = [ {"role": "user", "content": "Imagine three different experts are answering this question. All experts will write down 1 step of their thinking, then share it with the group. Then all experts will go on to the next step, etc. If any expert realizes they're wrong at any point then they leave. The question is 'The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?' Make sure to discuss the results."} ]
6.5 输出验证
通常有三种控制生成模型输出的方法。
- 示例
提供多个预期输出的示例。- 语法
控制词元选择过程。- 微调
在包含预期输出的数据上对模型进行微调。
6.5.1 提供示例
需要注意的是,模型输出是否遵循指定的格式仍然取决于模型本身。有些模型比其他模型更善于遵循指令。
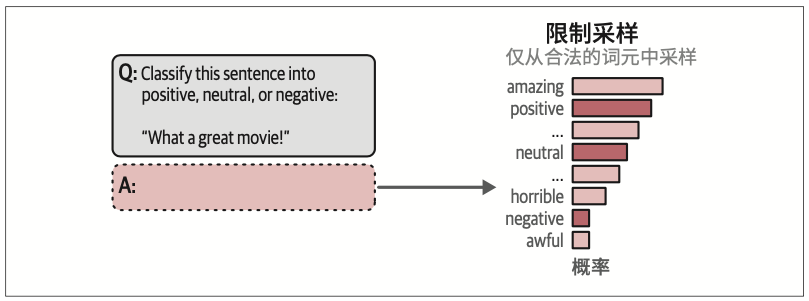
6.5.2 语法:约束采样
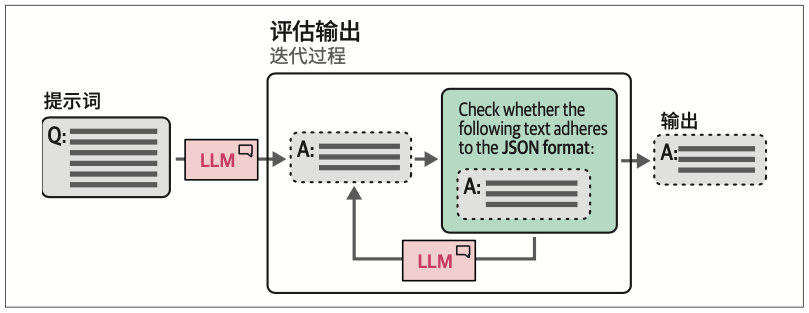
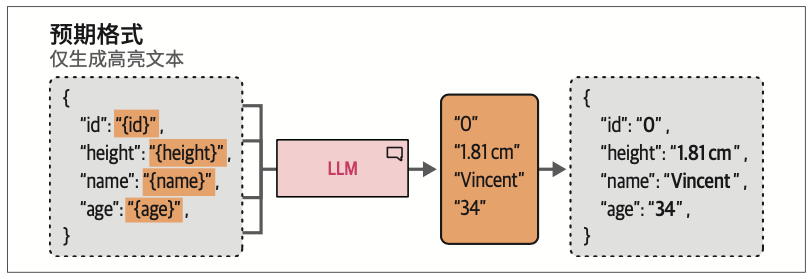
这个过程可以更进一步,我们不必在生成完输出后再验证,而是可以在词元采样过程中进行验证。在采样词元时,我们可以定义一些LLM在选择下一个词元时应遵循的语法或规则。
如图6-21所示,通过约束采样过程,我们可以让LLM只输出我们感兴趣的内容。注意,这仍然会受到top_p和temperature等参数的影响。
第7章 高级文本生成技术与工具
7.1 模型输入/输出:基于LangChain加载量化模型
通常建议选择至少4位量化的模型,此类方案能够在压缩效率与准确率之间达到最佳平衡。尽管存在3位甚至2位的量化模型,但其性能损失较为明显,这种情况下更推荐选用高精度的更小的模型。
7.2 链:扩展LLM的能力
7.2.1 链式架构的关键节点:提示词模板
7.3 记忆:构建LLM的对话回溯能力
7.3.3 对话摘要
我们通常需要在响应速度、记忆容量和准确率之间寻求平衡。
7.4 智能体:构建LLM系统
目前我们构建的系统均按照预设流程执行操作。LLM最具突破性的发展方向在于其自主决策能力。这类能够自主规划行动及其序列的系统被称为智能体(agent),其核心在于利用语言模型自主制定行动决策。
智能体系统的核心驱动力源自名为ReAct(reasoning and acting,推理与行动)的创新框架。
7.4.1 智能体的核心机制:递进式推理
该机制的核心在于智能体对思考(决策依据)、行动(操作指令)及观察(执行结果)的完整记录。这种思考、行动与观察的循环往复,最终生成智能体的输出。
第8章 语义搜索与RAG
8.1 语义搜索与RAG技术全景
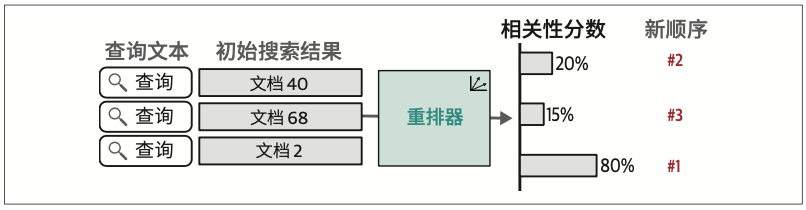
当前主流技术可分为三大类:稠密检索(dense retrieval)、重排序(reranking)与RAG。
8.2 语言模型驱动的语义搜索实践
8.2.1 稠密检索
理解稠密检索的局限性及其解决方案具有重要意义。例如,当文本中完全不存在答案时会发生什么?系统仍会返回结果及其相似度距离。
稠密检索的另一短板在于无法精准匹配特定短语,这类场景更适合关键词匹配技术。这正是建议采用混合搜索(结合语义搜索与关键词搜索)而非单纯依赖稠密检索的重要原因。
当将稠密检索系统应用于其训练数据之外的领域时,其性能也会显著下降。
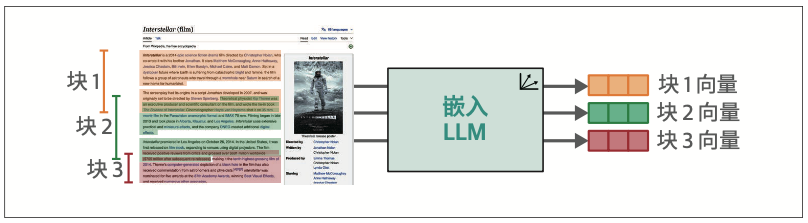
稠密检索系统的关键设计参数:如何实现长文本的最优分块处理?为何必须进行分块处理?
- 将文档分割为多个块并对各块进行嵌入处理,随后将这些块聚合为单个向量。常用聚合方式是对各向量取平均值,但此方式存在信息高度压缩的缺陷,导致文档中的大量细节丢失。
针对长文本的最佳分块方式,要根据系统需处理的文本类型和查询特征进行选择。
- 以段落为单位进行分块是更优的选择。当文本段落较短时,这种方法效果良好;若段落较长,则建议每3~8个句子划分为一个块。
- 某些文本块的含义高度依赖上下文,可通过以下方式增强上下文相关性。
- 在块中附加文档标题。
- 引入一部分上下文内容。通过构建重叠块结构(即相邻块包含部分重复文本),可有效地保留上下文信息。图8-10所示即为这种方式的典型应用。
随着稠密检索技术的持续演进,更多创新的分块策略正在涌现——部分方案已开始利用LLM实现动态智能分块,以生成语义连贯的文本单元。
8.2.2 重排序
欲深入了解LLM在搜索领域的发展脉络,强烈推荐阅读“Pretrained Transformers for Text Ranking: BERT and Beyond”,该论文系统梳理了截至2021年的相关技术演进。
8.2.3 检索评估指标体系
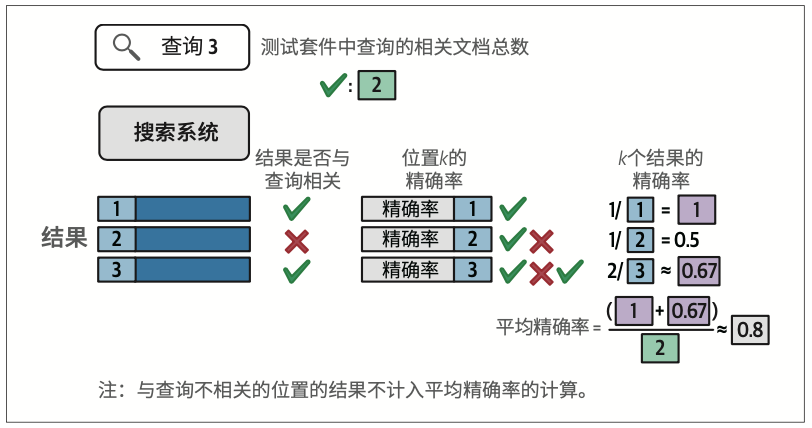
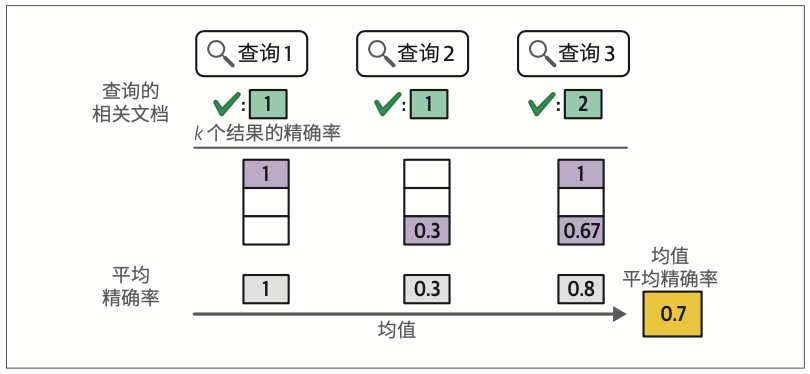
语义搜索系统的评估沿用信息检索(information retrieval,IR)领域的经典指标。我们重点解析其中最具代表性的指标之一:均值平均精确率(mean average precision,mAP)。
完整的搜索系统评估框架包含三大要素:文档库、查询集合,以及表明查询与文档对应关系的相关性判断。
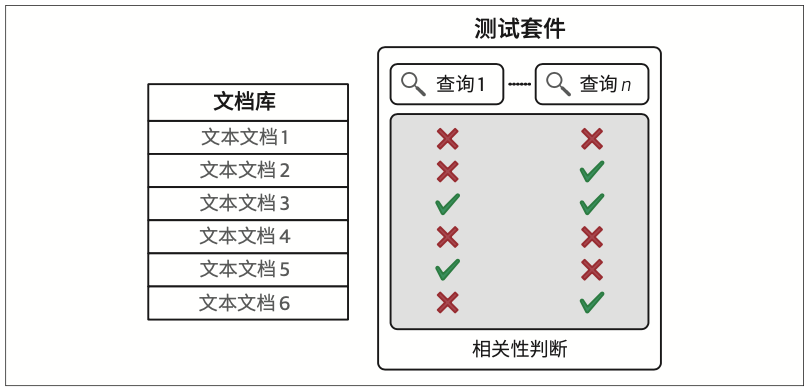
除均值平均精确率外,搜索系统还常使用归一化折损累积增益(normalized discounted cumulative gain,nDCG)作为评估指标。该指标具有更精细的考量维度,因为在测试套件和评分机制中,文档的相关性并非二元的(只有相关与不相关),而是允许标注不同等级的相关程度。
8.3 RAG
8.3.3 示例:使用本地模型的RAG
BAAI/bge-small-en-v1.5模型。截至撰写本书时,该模型在MTEB排行榜的嵌入模型类别中名列前茅,同时模型体积较小。
8.3.4 高级RAG技术
当RAG系统作为聊天机器人时,若用户提问冗长或需要关联对话上下文,基础RAG在信息检索环节可能表现欠佳。此时,使用LLM将原始查询转化为更利于检索的简洁形式是一种有效的策略。
需特别说明的是,并非所有LLM都具备本节讨论的RAG功能。截至本书撰写时,仅有少数头部托管模型尝试支持此类特性。值得关注的是,Cohere推出的Command R+在此类任务中表现卓越,且其开放权重版本也可供使用。
8.3.5 RAG效果评估
论文“Evaluating Verifiability in Generative Search Engines”(2023),该研究通过人工评估对比了多种生成式搜索系统,其评估框架包含四个核心维度。
流畅性(fluency)
生成文本的语言流畅度与逻辑连贯性。
感知效用(perceived utility)
回答内容的信息价值与实用价值。
引用召回率(citation recall)
外部事实陈述中获得完整引证支持的比例。
引用精确率(citation precision)
引用内容对相关论断的支持的有效性。
通过LLM-as-a-judge范式实现自动化评估,即使用高性能LLM对生成结果进行多维度评分。Ragas便是实现此类评估的开源工具库,它还包含以下两个评估指标。
忠实度(faithfulness)
答案与所提供上下文的一致性程度。
答案相关性(answer relevance)
答案与提问主题的契合度。
第9章 多模态LLM
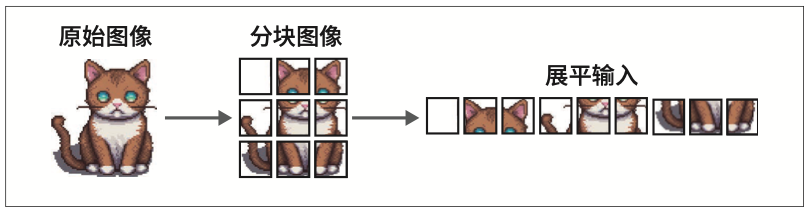
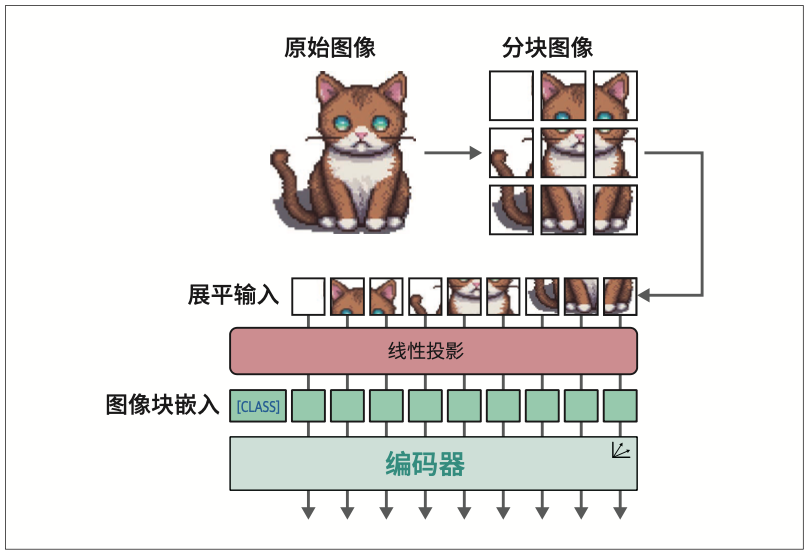
9.1 视觉Transformer
视觉Transformer(Vision Transformer,ViT),在图像识别任务中展现出超越传统卷积神经网络(convolutional neural network,CNN)的性能。
9.2 多模态嵌入模型
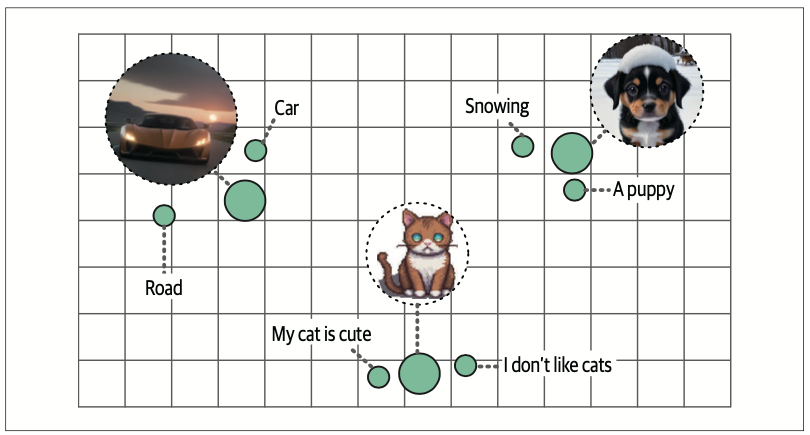
在众多多模态嵌入模型中,对比语言-图像预训练(Contrastive Language-Image Pre-training,CLIP)模型以其卓越的性能和广泛的适用性成为当前最主流的解决方案。
9.2.2 CLIP的跨模态嵌入生成机制
余弦相似度是向量间夹角的余弦值,其计算方式为嵌入向量的点积除以各自长度的乘积。
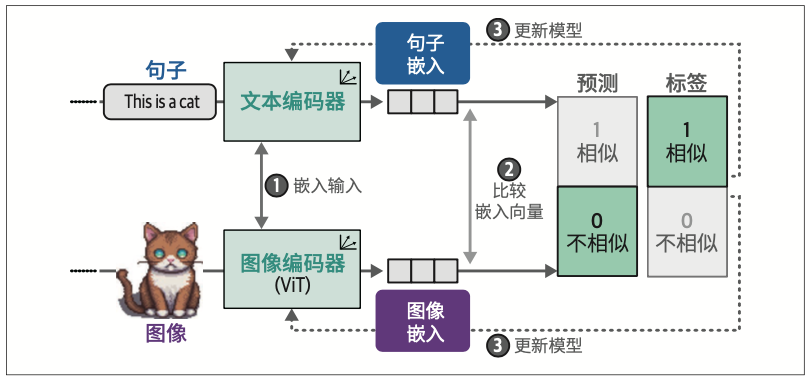
为确保表示的准确性,训练过程中还需引入无关图像和文本描述作为负例。建模相似度的核心不仅在于捕捉事物的共性,更要建立区分异质样本的能力。
9.3 让文本生成模型具备多模态能力
9.3.1 BLIP-2:跨越模态鸿沟
BLIP-2的突破在于,通过构建名为查询式Transformer(Querying Transformer,Q-Former)的智能桥梁,巧妙连接预训练视觉编码器与预训练LLM,而非重新构建整个系统架构。这种设计既保留了已有模型的优势,又实现了跨模态的信息传递。
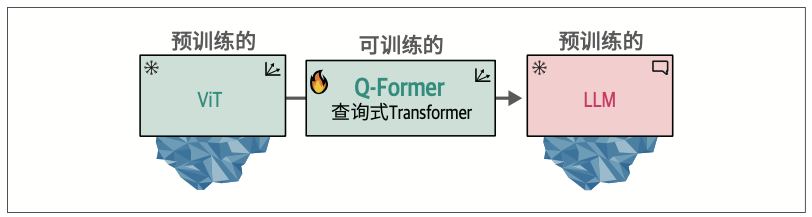
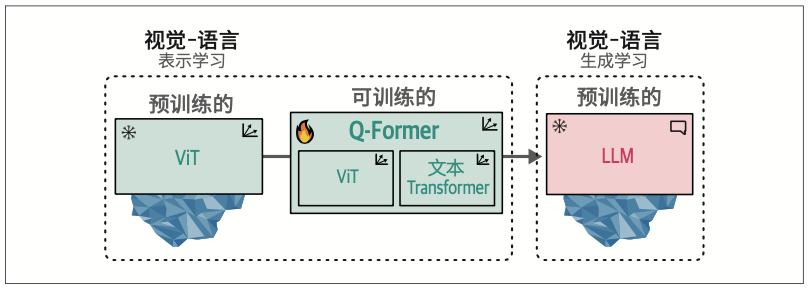
图像首先被输入至冻结的ViT进行视觉特征提取。这些视觉嵌入随后作为Q-Former模块中ViT的输入,同时对应的描述文本则被输入至Q-Former的文本Transformer模块进行处理。
9.3.4 用例2:基于聊天的多模态提示词
可以借助ipywidgets构建交互式聊天机器人,让整个流程更加顺畅。ipywidgets作为Jupyter Notebook的扩展模块,支持创建交互式按钮、文本输入框等交互元素
第三部分 训练和微调语言模型
第10章 构建文本嵌入模型
10.2 什么是对比学习
对比学习是训练和微调文本嵌入模型的一种主要技术。对比学习的目标是训练嵌入模型,使相似文档在向量空间中距离更近,而不相似文档相距更远。
对比学习的基本理念是,向模型输入相似的和不相似的文档对作为示例,这是学习文档之间的相似性或差异性并构建相关模型的最佳方式。
通过“为什么是P而不是Q”理解“为什么是P”。
在自然语言处理领域,一个最早且最流行的对比学习的例子是我们在第1章和第2章中讨论过的word2vec。该模型通过在句子中训练单个词来学习词的表示。在一个句子中,靠近目标词的词被构建成正例对,而随机采样的词被构建成负例对(不相似的对)。换句话说,它通过将目标词的相邻词与非相邻词进行对比来训练模型。虽然并不广为人知,但这是自然语言处理领域利用神经网络进行对比学习的首批重大突破之一。
10.3 SBERT
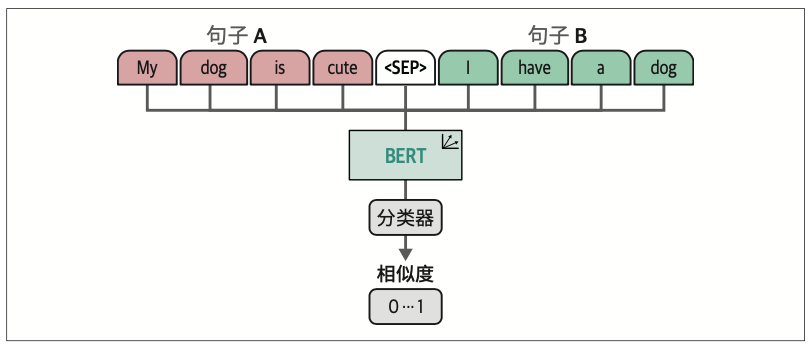
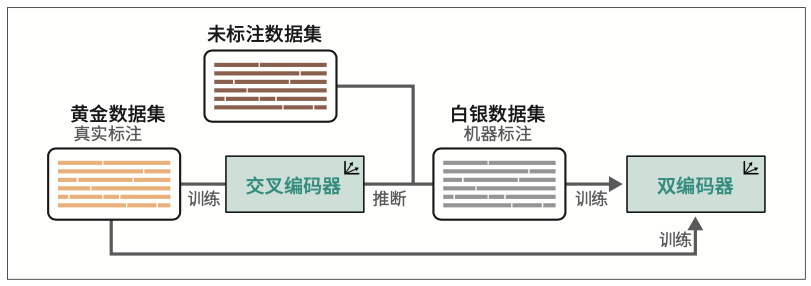
尽管对比学习有多种形式,但在自然语言处理领域,推广这种技术的一个框架是sentence-transformers。该框架解决了原始BERT实现在创建句子嵌入时的一个主要问题,即计算开销。在sentence-transformers诞生前,句子嵌入通常使用交叉编码器(cross-encoder)架构,并结合BERT模型来实现。
交叉编码器允许两个句子同时通过Transformer网络进行处理,以预测两个句子的相似度。它通过在原始架构上添加分类头来实现这一点,该分类头可以输出相似度分数。然而,当你想在一个包含10000个句子的集合中找到相似度最高的配对时,计算量会迅速增加。
交叉编码器通常不会生成嵌入向量,而是输出输入句子之间的相似度分数。
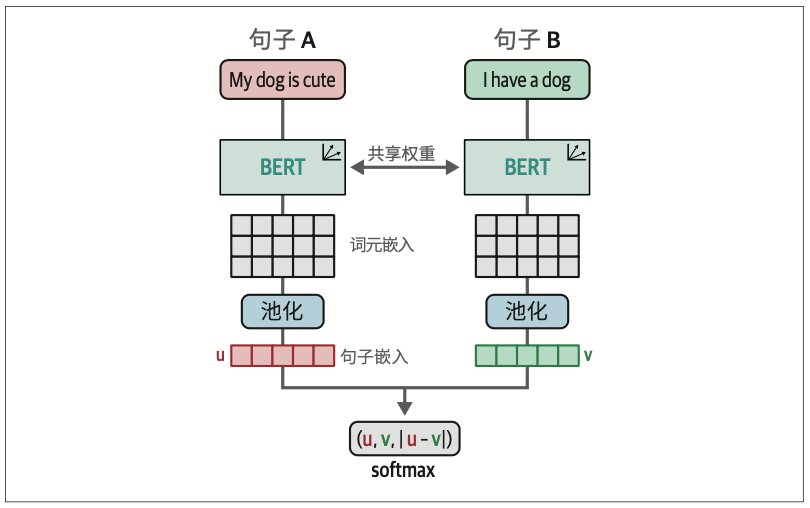
这种架构也被称为双编码器(bi-encoder)或SBERT(sentence-BERT)。虽然双编码器的运算速度相当快并能创建精准的句子表示,但交叉编码器通常比双编码器具有更好的性能,并且无须生成嵌入向量。
10.4 构建嵌入模型
构建嵌入模型的方法有很多,我们通常采用对比学习。这对许多嵌入模型来说至关重要,因为通过对比学习,模型能够高效地学习语义表示。
10.4.1 生成对比样本
自然语言推理(NLI)
NLI任务的目标是研究给定前提是否蕴含假设(蕴含)、是否与假设矛盾(矛盾)或者两者都不成立(中性)。
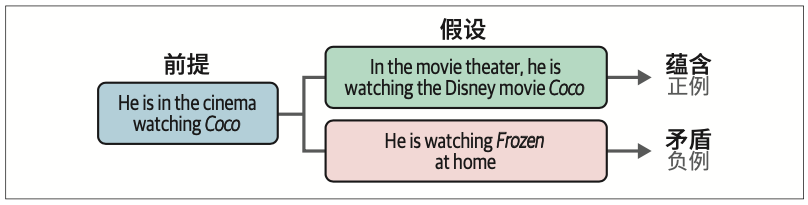
如果仔细观察“蕴含”和“矛盾”这两个概念,你会发现它们描述的是两个输入之间的相似度。因此,我们可以使用NLI数据集来生成对比学习所需的负例(矛盾)和正例(蕴含)。
通用语言理解评估基准(General Language Understanding Evaluation benchmark,简称GLUE基准)
GLUE基准的任务之一是多类型自然语言推理(MNLI)语料库,它包含392702个有推理关系标注(矛盾、中性、蕴含)的句子对。
10.4.2 训练模型
语义文本相似度基准(Semantic Textual Similarity Benchmark,STSB)
10.4.3 深入评估
大规模文本嵌入基准(Massive Text Embedding Benchmark,MTEB)
为了公开比较前沿嵌入模型的性能,业界建立了MTEB排行榜,展示了各嵌入模型在相关任务上的得分。
10.4.4 损失函数
可供选择的损失函数种类繁多,我们通常不建议使用softmax,因为其他损失函数可能更高效。
与问题非常相关但不是正确答案的负例。这样的负例被称为难负例(hard negative)。
10.5 微调嵌入模型
10.5.1 监督学习
训练或微调模型的主要难点在于找到合适的数据。对于这些模型,我们不仅需要庞大的数据集,数据本身的质量也必须很高。开发正例对通常比较直接,但增加难负例对会显著加大创建高质量数据的难度。
10.6 无监督学习
TSDAE(Transformer-based Sequential Denoising Auto-Encoder,基于Transformer的序列去噪自编码器)
10.6.1 TSDAE
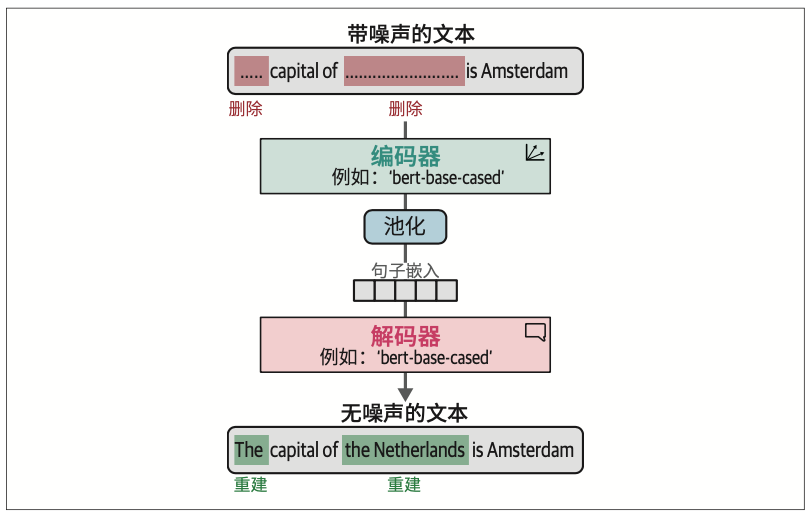
TSDAE的基本思想是通过删除输入句子中一定比例的词来为其添加噪声。这个“受损”的句子被输入编码器中,编码器的上方有一个池化层,将其映射为句子嵌入。基于这个句子嵌入,解码器尝试重建原始句子,但不包含人为添加的噪声。这里的核心概念是:句子嵌入越准确,重建的句子就越准确。
这种方法与掩码语言建模非常相似。在掩码语言建模中,我们试图重建和学习某些被掩码的词。这里,我们不是重建被掩码的词,而是尝试重建整个句子。
训练完成后,我们可以使用编码器从文本生成嵌入向量,因为解码器仅用于判断嵌入向量是否能准确地重建原始句子。
10.6.2 使用TSDAE进行领域适配
当我们只有很少或完全没有标注数据时,通常使用无监督学习的方法来创建文本嵌入模型。然而,无监督学习技术的表现通常不如监督学习技术,而且难以学习特定领域的概念。
这时领域适配(domain adaptation)就派上用场了。它的目标是将现有的嵌入模型更新到一个包含不同于源领域主题的特定文本领域。
领域适配的一种方法称为自适应预训练。首先,使用无监督学习技术(如前面讨论的TSDAE或掩码语言建模)对特定领域的语料库进行预训练。然后,如图10-15所示,使用域内或域外的训练数据集对该模型进行微调。虽然目标领域的数据是首选,但由于我们从目标领域的无监督训练开始,域外数据也同样有效。
第11章 为分类任务微调表示模型
11.1.2 冻结层
尽管我们通常会优先考虑训练尽可能多的层,但在计算资源受限的情况下,仅训练部分层仍能取得可接受的效果。
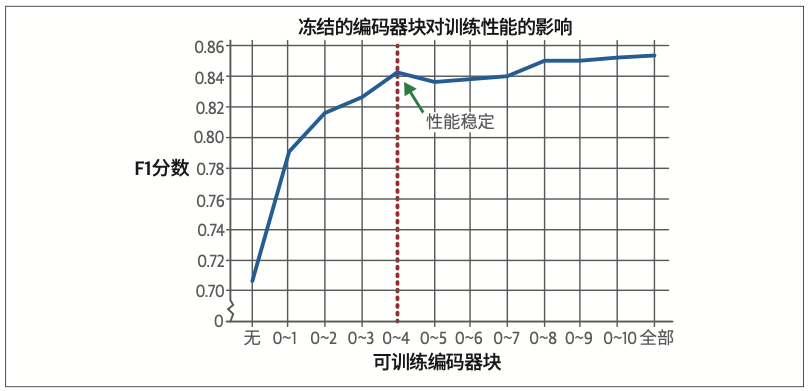
随着训练轮次的增加,冻结与不冻结策略在训练耗时和资源消耗方面的差异将越发显著。因此建议尝试不同的冻结配置方案,在性能与效率之间找到最优平衡点。
11.2 少样本分类
少样本分类作为监督学习分类的一种特殊技术,能使分类器仅通过少量标注样本即可学习并识别不同的目标标签。对于缺乏现成的标注数据的分类任务而言,这种技术尤为实用。这种技术的核心思想是通过为每个类别精心标注少量高质量的数据点来完成模型训练。
11.2.1 SetFit:少样本场景下的高效微调方案
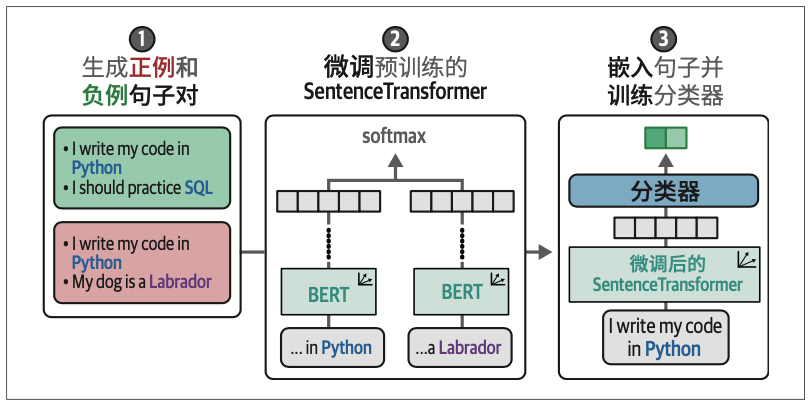
SetFit的具体实现包含三个核心阶段:首先,通过类内和类间选择生成句子对;其次,利用这些句子对微调预训练的SentenceTransformer模型;最后,采用微调后的模型生成句子嵌入,并基于此训练分类器。
11.2.2 少样本分类的微调
SetFit不仅能胜任少样本分类任务,还适用于完全无标注的零样本分类场景。SetFit的工作原理是,通过标注名称生成合成样本来模拟分类任务,随后在这些样本上训练SetFit模型。例如,当目标标签为happy和sad时,系统可能自动生成类似The example is happy和This example is sad的合成句子。
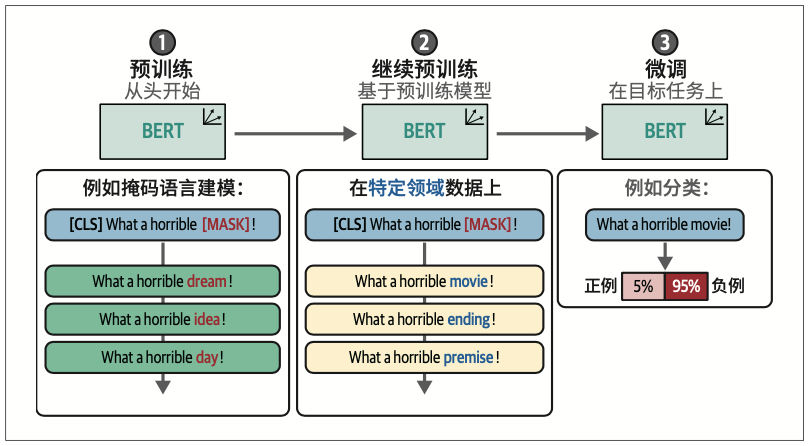
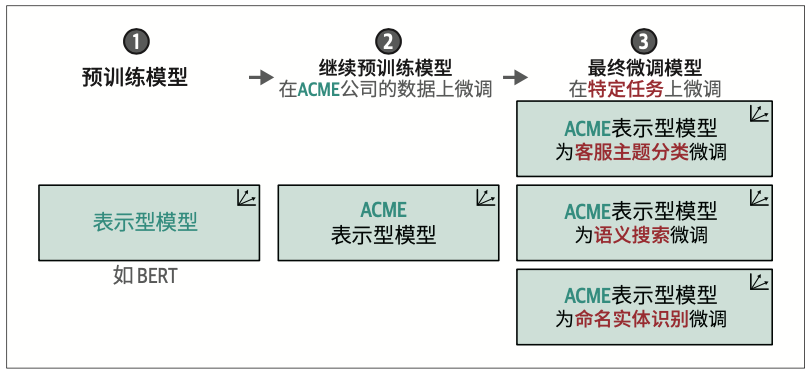
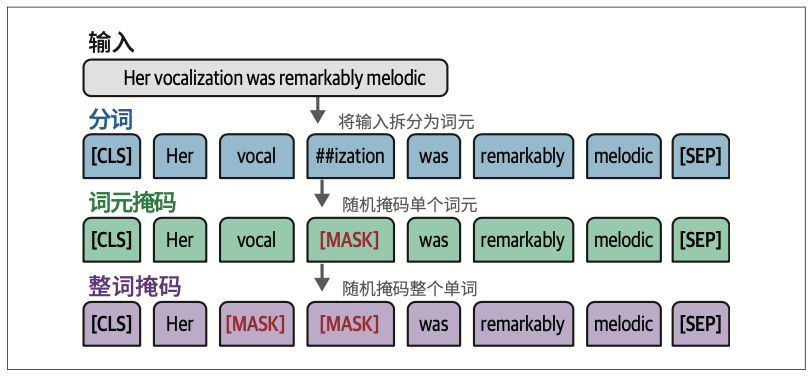
11.3 基于掩码语言建模的继续预训练
11.4 命名实体识别
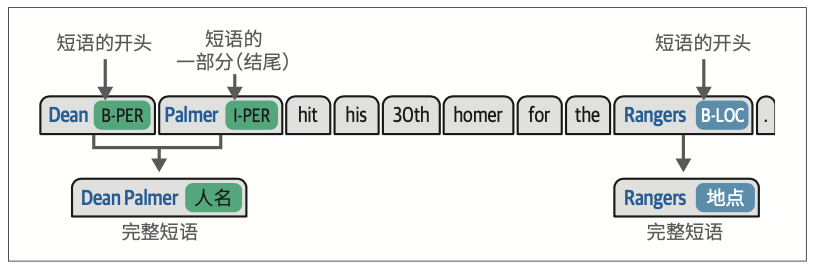
11.4.1 数据准备
第12章 微调生成模型
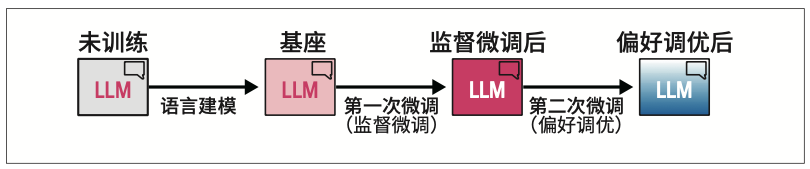
12.1 LLM训练三步走:预训练、监督微调和偏好调优

12.2 监督微调
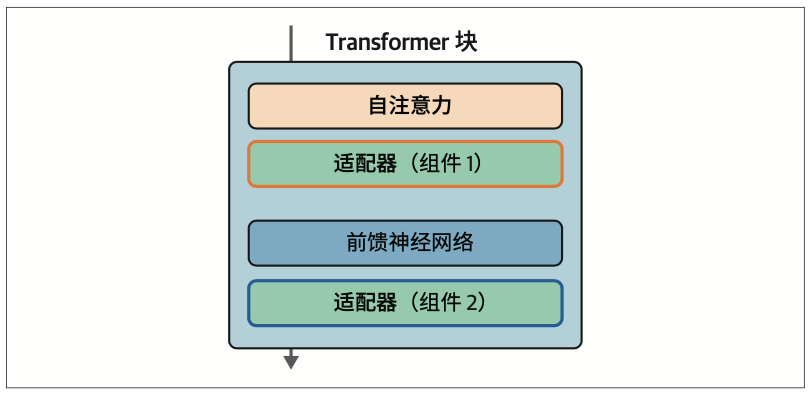
12.2.2 参数高效微调
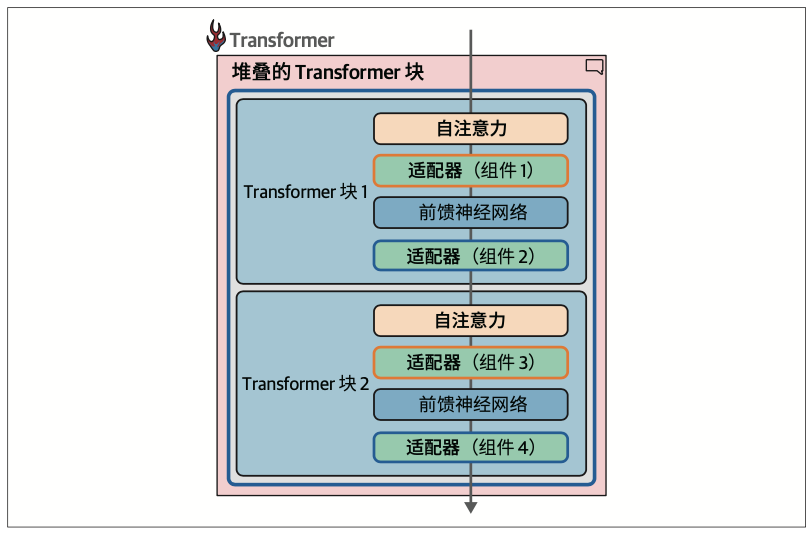
适配器(adapter)是许多基于PEFT的技术的核心组件。使用适配器的方案是,在Transformer内部引入一组额外的模块化组件,通过微调这些组件来提升模型在特定任务上的性能,而无须微调模型的所有权重。这节省了大量时间和计算资源。
每个适配器可以专注于不同的任务,例如适配器1可以专门用于医疗文本分类,而适配器2可以专门用于命名实体识别。你可以从AdapterHub下载领域专用的适配器。
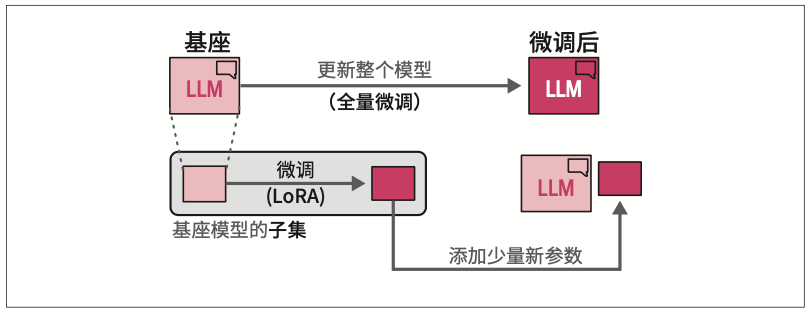
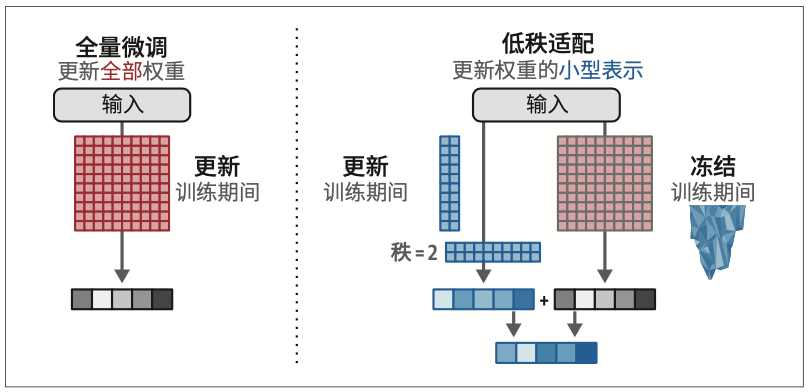
作为适配器的替代方案,低秩适配(low-rank adaptation,LoRA)被引入。当前,LoRA是一种应用广泛且有效的参数高效微调技术。与适配器类似,LoRA也只需要更新少量参数。如图12-11所示,它创建了基座模型的一个小型子集来进行微调,而没有向模型添加新层。

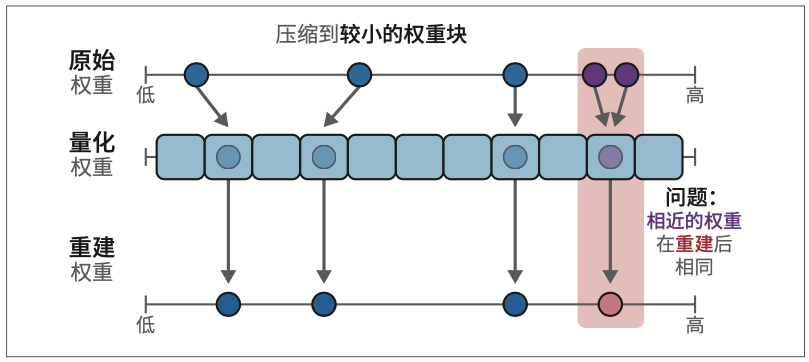
QLoRA使用分块量化的方法将某些高精度值块映射为低精度值。
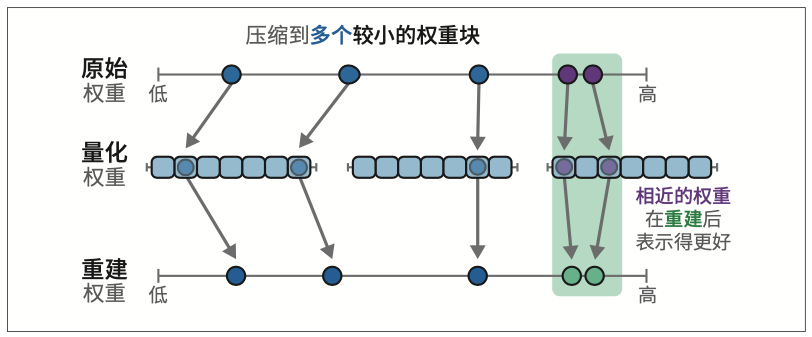
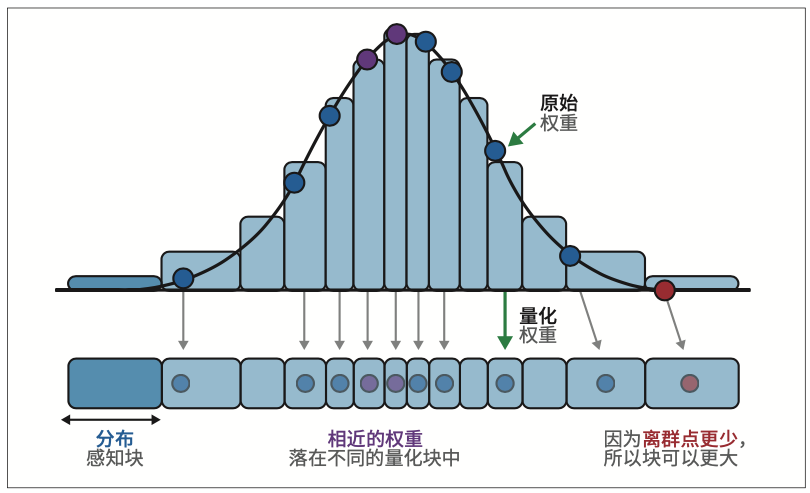
博客文章“A Visual Guide to Quantization”是关于量化的完整指南,且高度可视化。
12.3 使用QLoRA进行指令微调
12.3.3 LoRA配置
r
压缩矩阵的秩
lora_alpha
控制添加到原始权重的变化量。本质上,它平衡了原始模型的知识与新任务的知识。经验法则是将该参数的值设置为r值的两倍。
12.3.4 训练配置
只要有可用的数据(包含适当的查询-回复对),QLoRA就是一个非常有效的技术,可以把现有的对话模型微调得更适合具体用例。
12.4 评估生成模型
12.4.1 词级指标
评估生成模型的一类常见指标是词级指标。词级评估的经典技术在词元(集合)层面比较参考数据集与生成的词元。常见的词级指标包括困惑度(perplexity)、ROUGE、BLEU和BERTScore。
12.4.2 基准测试
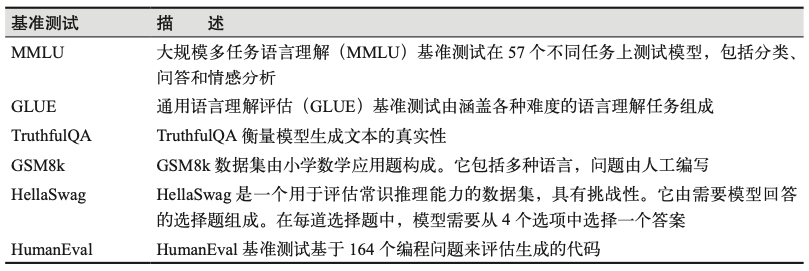
要评估生成模型在语言生成和理解任务上的表现,一种常见方法是使用广为人知的公共基准测试,如MMLU、GLUE、TruthfulQA、GSM8k和HellaSwag。
12.4.5 人工评估
尽管基准测试至关重要,但评估的金标准通常被认为是人工评估。
Chatbot Arena是基于人工评估技术的绝佳示例。在这个排行榜中有两个匿名的LLM与你互动。你提出的任何问题或提示词都会同时发送给这两个模型,然后你会收到它们的输出。之后,你可以决定更喜欢哪个输出。这个过程使得社区成员在不知道具体是哪些模型的情况下,对他们偏好的模型进行投票。只有在你投票之后,你才能看到是哪个模型生成了哪段文本。
当一个指标成为目标时,它就不再是一个好的指标。
——古德哈特定律
12.6 使用奖励模型实现偏好评估自动化
要实现偏好评估自动化,我们需要在偏好调优步骤之前增加一个步骤,即训练一个奖励模型
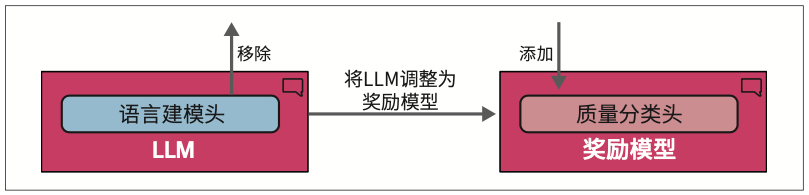
要创建奖励模型,我们可以复制经过指令微调的模型,并稍作修改,使其不再生成文本,而是输出一个单一的分数。
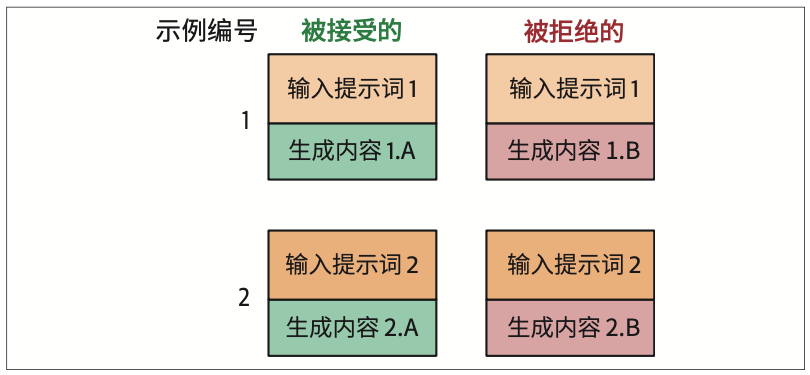
12.6.2 训练奖励模型
我们不能直接使用奖励模型。奖励模型需要先经过训练才能正确地对生成内容进行评分。因此,我们需要获取一个模型可以学习的偏好数据集。
近端策略优化(proximal policy optimization,PPO)。PPO是一种流行的强化学习技术,通过确保LLM不会过度偏离预期奖励来优化经过指令微调的LLM。
12.6.3 训练无奖励模型
直接偏好优化(direct preference optimization,DPO)是PPO的一种替代方案,它摒弃了基于强化学习的训练过程。DPO不再使用奖励模型来评判生成内容的质量,而是让LLM自己来完成这项工作。
12.7 使用DPO进行偏好调优
12.7.4 训练
SFT和DPO相结合是一个很好的方法,可以先对模型进行微调以实现基本对话功能,然后根据人类偏好来调整其回答。但是,这也需要付出代价,因为我们需要执行两轮训练,并且可能需要在两个过程中调整参数。
优势比偏好优化(odds ratio preference optimization,ORPO),它将SFT和DPO合并为一个训练过程。ORPO不需要执行两轮训练,在允许使用QLoRA的同时,进一步简化了训练过程。