在 MedImageInsight 中,介绍了由微软发表,第三方发布的医学图像嵌入模型,本文将以其中的 Text Encoder 为例,浅析 Embedding 模型的工作原理。
什么是 Embedding 模型
Embedding 模型是一种将高维数据(如文本、图像等)转换为低维向量表示的模型。通过这种转换,模型能够捕捉数据的语义信息,使得相似的数据在向量空间中距离更近。
以 lion-ai/MedImageInsights 中的 Text Encoder 为例(其使用的分词器只支持英文),输入 ["lumbar spine", "chest", "desktop"] ,将得到如下的向量表示:
# text_embeddings: {ndarray: (2, 1024)}
[
[ -0.03271601, 0.02388754, 0.02584449, ..., 0.00670768, 0.00604417, -0.01052989],
[ -0.03645158, -0.00188246, 0.00022278, ..., -0.02536389, -0.02322166, 0.02286733],
[ -0.0056968 , 0.06878266, 0.0043339 , ..., -0.02845573, 0.01347476, -0.04035829]
]每个输入文本被转换为一个 1024 维的向量。计算这些向量的余弦相似度,可以发现 lumbar spine 和 chest 的相似度较高,而 desktop 与前两者的相似度较低,这反映了它们在语义上的关系:
lumbar spine, chest 余弦相似度: 0.728603
lumbar spine, desktop 余弦相似度: 0.33807534
chest, desktop 余弦相似度: 0.38285893lion-ai/MedImageInsights 中的 Text Encoder 是怎么把文本转换为向量的
简单来说:
- 文本先经过分词器处理成 token 序列;
- 之后输入到 Text Encoder 模型中,通过其架构和权重进行前向传播,将 token 序列转换为向量表示;
- 最后进行投影(为了将文本编码器和图像编码器的输出投影到同一个嵌入空间)和向量归一化。
下面以输入 ["lumbar spine", "chest"] 为例,推演文本转换成向量的过程。
分词器(Tokenizer)
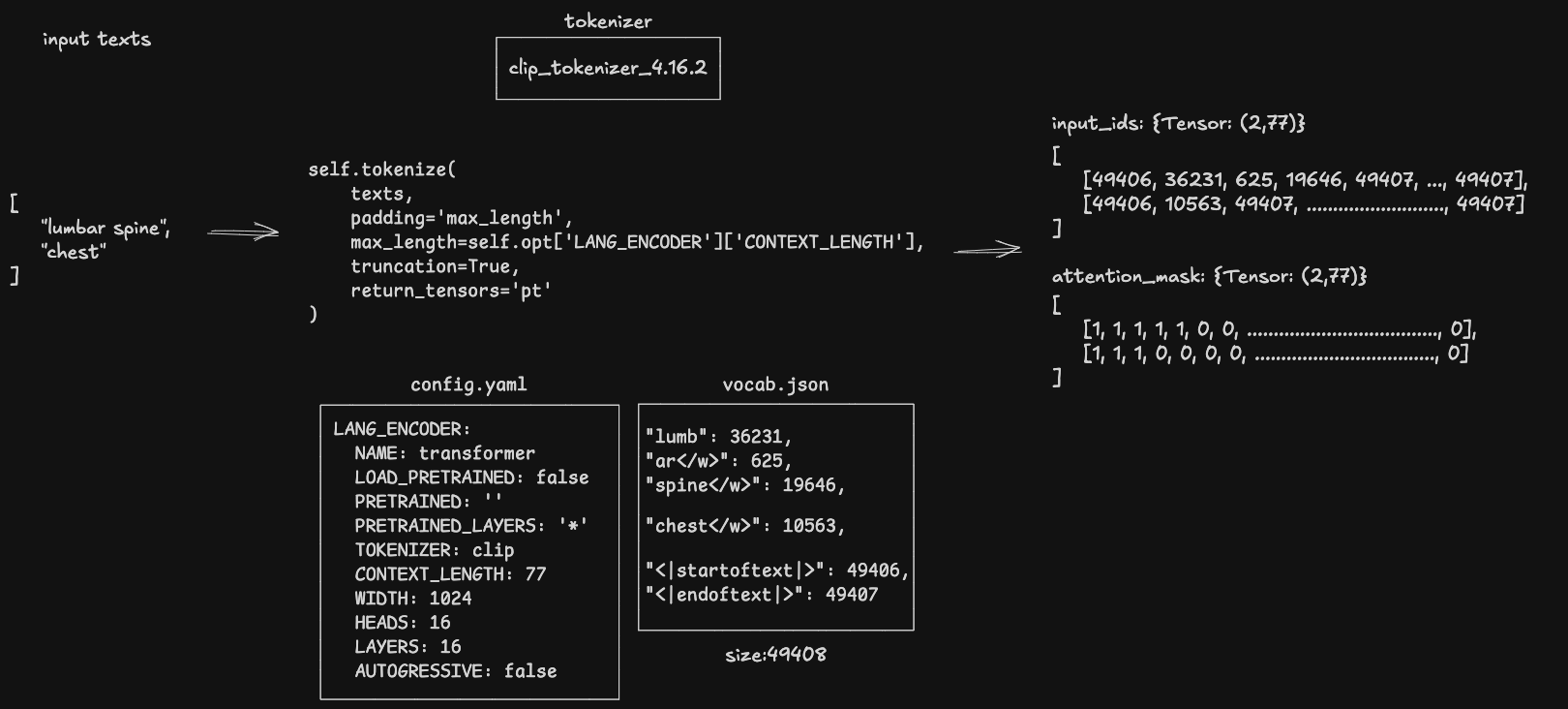
load_model 时,设置分词器路径为 '2024.09.27/language_model/clip_tokenizer_4.16.2':
# Set paths
self.opt['LANG_ENCODER']['PRETRAINED_TOKENIZER'] = os.path.join(
self.model_dir,
'language_model',
'clip_tokenizer_4.16.2'
)build_tokenizer 中,使用 CLIPTokenizer 加载分词器:
pretrained_tokenizer = config_encoder.get(
'PRETRAINED_TOKENIZER', 'openai/clip-vit-base-patch32'
)
tokenizer = CLIPTokenizer.from_pretrained(pretrained_tokenizer)encode 中,调用分词器对文本进行分词:
text_tokens = self.tokenize(
texts,
padding='max_length',
max_length=self.max_length,
truncation=True,
return_tensors='pt'
)得到的 token ID 可在 vocab.json 中查找对应的词汇。
模型架构(Model Architecture)
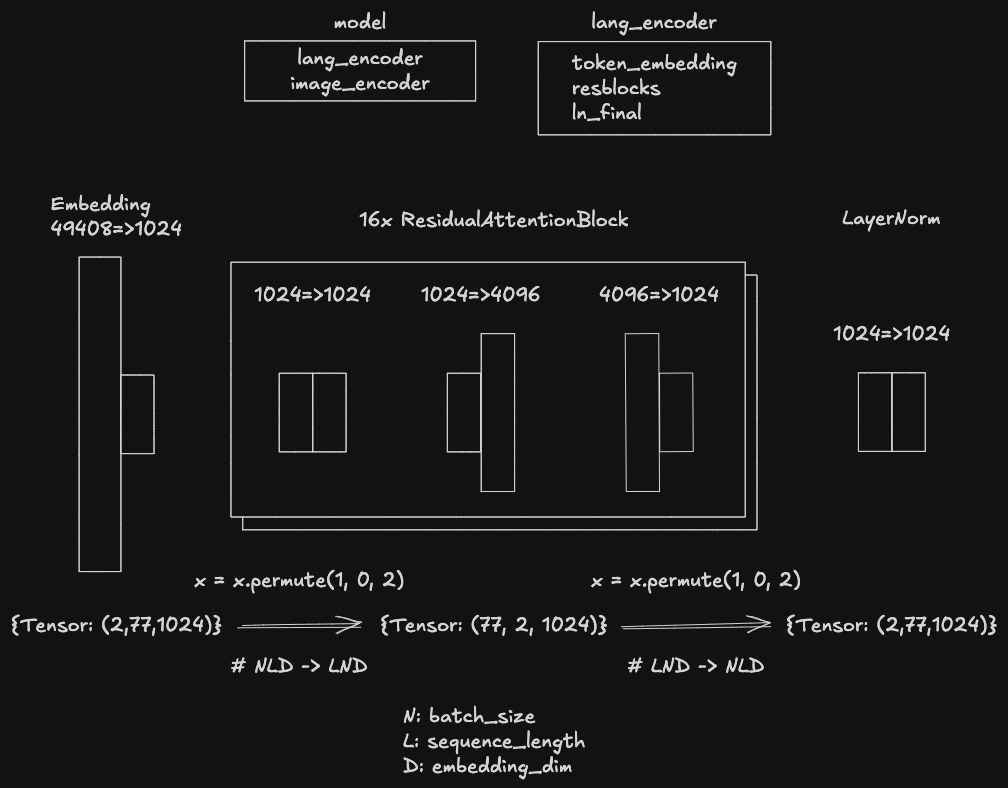
build_unicl_model 处可以观察到模型的架构(image_encoder 部分省略):
UniCLModel(
(lang_encoder): Transformer(
(token_embedding): Embedding(49408, 1024)
(resblocks): ModuleList(
(0-15): 16 x ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=1024, out_features=1024, bias=True)
)
(ln_1): LayerNorm()
(mlp): Sequential(
(c_fc): Linear(in_features=1024, out_features=4096, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=4096, out_features=1024, bias=True)
)
(ln_2): LayerNorm()
(drop_path): Identity()
)
)
(ln_final): LayerNorm()
)
(image_encoder): DaViT(
(convs): ModuleList(
(0): ConvEmbed(...)
(1): ConvEmbed(...)
(2): ConvEmbed(...)
(3): ConvEmbed(...)
)
(blocks): ModuleList(
(0): MySequential(
(0): MySequential(...)
)
(1): MySequential(
(0): MySequential(...)
)
(2): MySequential(
(0): MySequential(...)
(1): MySequential(...)
(2): MySequential(...)
(3): MySequential(...)
(4): MySequential(...)
(5): MySequential(...)
(6): MySequential(...)
(7): MySequential(...)
(8): MySequential(...)
)
(3): MySequential(
(0): MySequential(...)
)
)
(norms): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(avgpool): AdaptiveAvgPool1d(output_size=1)
(head): Identity()
)
)
模型权重(Model Weights)
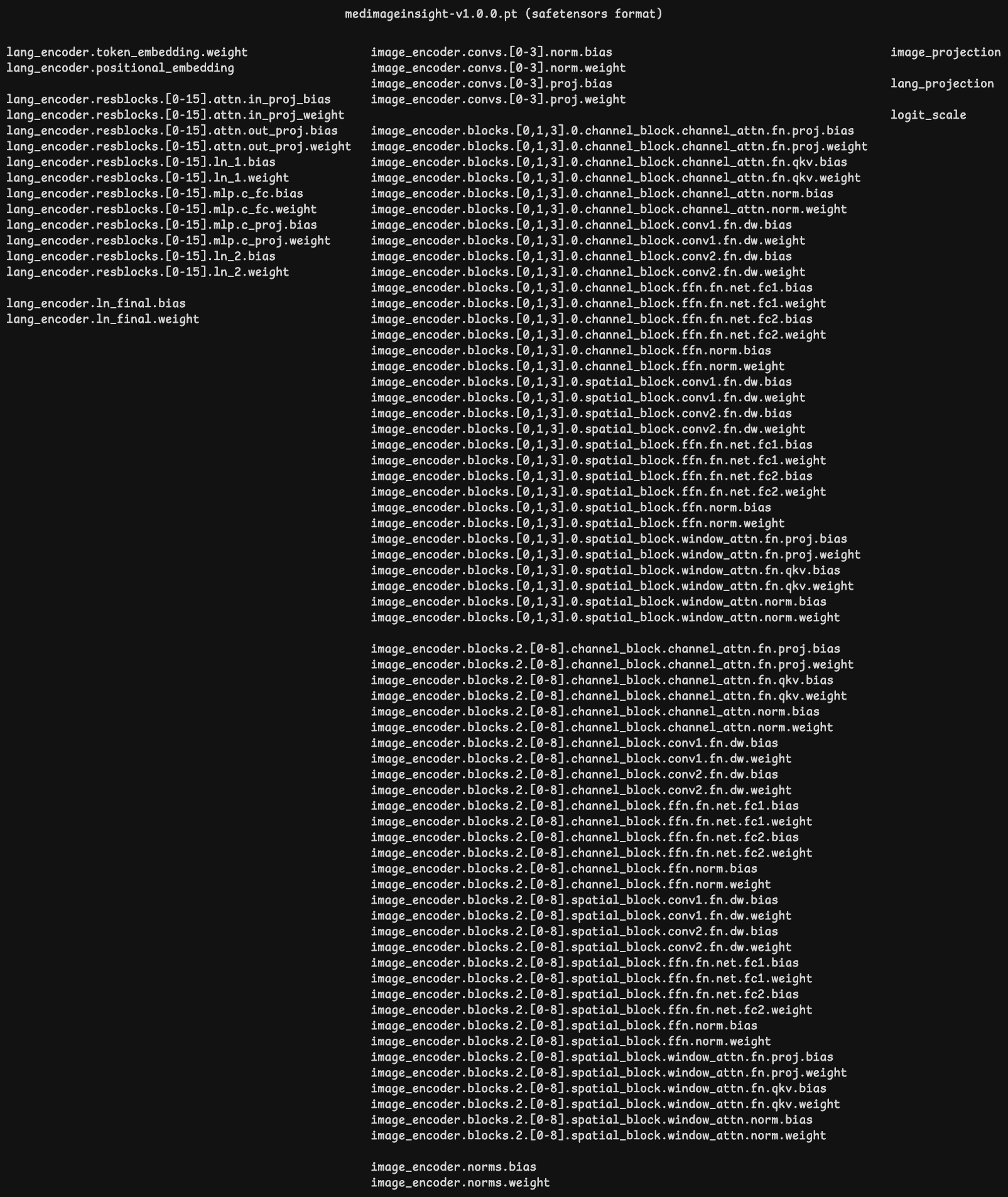
尽管 lion-ai 发布的模型权重文件 2024.09.27/vision_model/medimageinsigt-v1.0.0.pt 扩展名是 pt,但实际是 Safetensors 格式,在 from_pretrained 中读取:
from safetensors.torch import load_file
## Load SafeTensors Version of Pretrained Model
pretrained_dict = load_file(pretrained)其中包含张量如下,与上面模型架构一一对应:
Transformer
继续上面文本嵌入向量的过程。在经过分词器处理后,得到的 token ID 序列会经过 Text Encoder 模型的 Transformer 结构进行前向传播。该 Transformer 主要包括三部分:
- Embedding 层:将 token ID 转换为初始的向量表示。
- 多层 ResidualAttentionBlock:通过自注意力机制和前馈网络,捕捉序列中的上下文信息。
- LayerNorm 层:对输出进行归一化处理,稳定训练过程。
Embedding
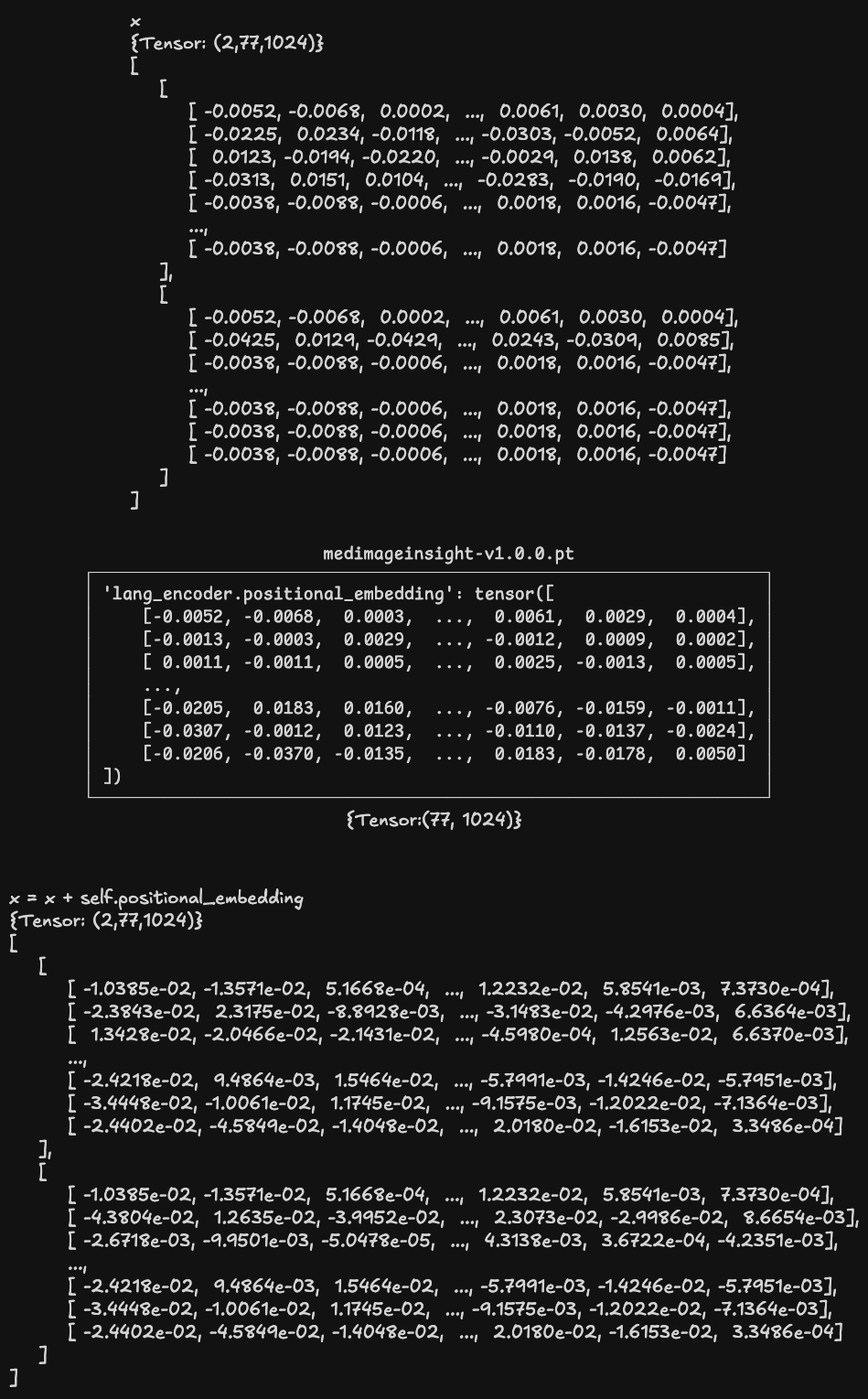
forward 方法使用 token ID 序列从模型权重文件中的 lang_encoder.token_embedding.weight 中查找对应的嵌入向量:

之后与位置嵌入矩阵相加:
由于 Transformer.forward() 对于输入张量的形状要求是:
Shape:
- src: (S,E) for unbatched input, (S,N,E) if batch_first=False or (N, S, E) if batch_first=True.
where S is the source sequence length, T is the target sequence length, N is the batch size, E is the feature number
故将三维张量由 (N, L, D) 重新排列为 (L, N, D),供后续的多层 ResidualAttentionBlock 处理。
- N: 批量大小(Batch Size)
- L: 序列长度(Sequence Length)
- D: 嵌入维度(Embedding Dimension)

ResidualAttentionBlock
resblocks 由 16 个 ResidualAttentionBlock 组成,每个块包括以下组件:
- MultiheadAttention:多头注意力层,允许模型关注输入序列的不同部分。
- LayerNorm:对输入进行归一化,稳定训练过程。
- MLP(多层感知机,前馈神经网络):包含两个线性层和一个激活函数(QuickGELU),用于进一步处理注意力输出。
- LayerNorm:再次对输出进行归一化。
- Drop Path:根据参数决定使用 DropPath(随机丢弃路径)或 Identity(无操作)。
经过多层 ResidualAttentionBlock 处理后,张量形状仍为 (L, N, D):
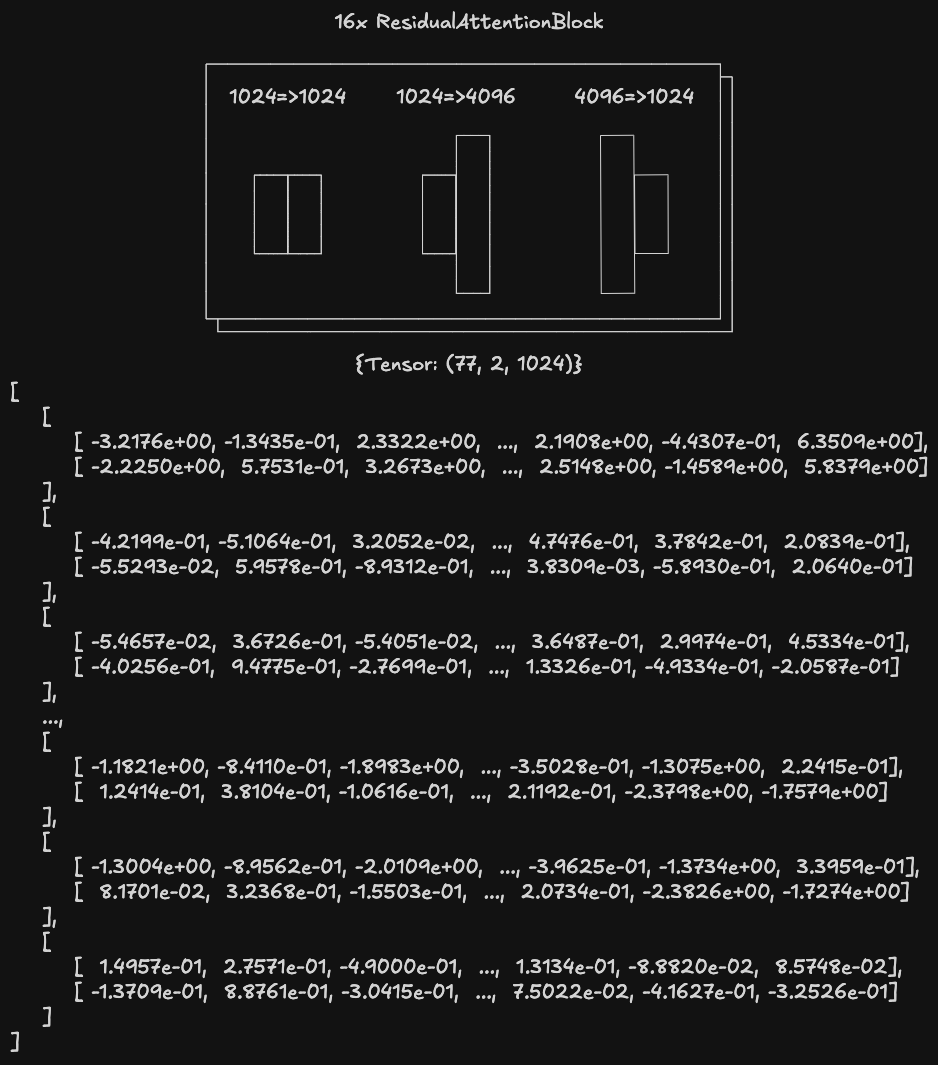
将其重新排列成 (N, L, D):

LayerNorm
最后归一化处理:

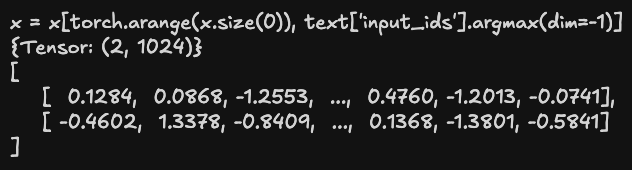
此时张量的形状是 (2, 77, 1024),按批次提取 token ID 序列中第一个最大值(即 EOF,49407)位置索引的向量,得到 (2, 1024) 形状的张量,即为输入文本嵌入后的结果:
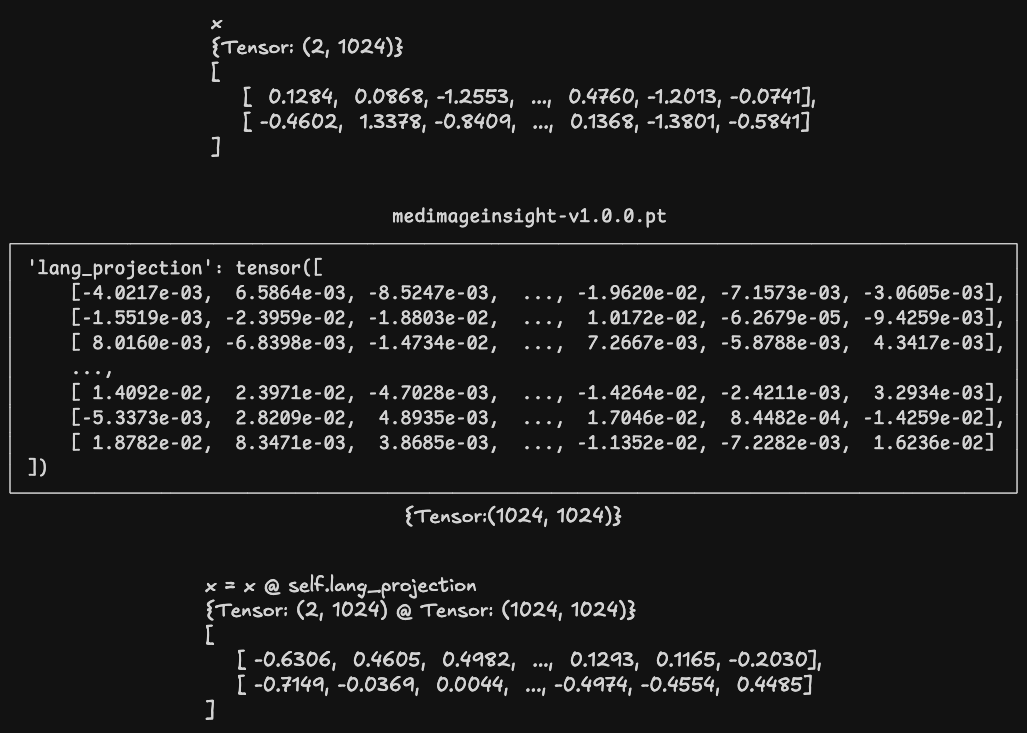
投影(Projection)
在完成上面的计算后,MedImageInsight 还需要进行一次投影操作,用以将 Image Encoder 和 Text Encoder 的编码结果投影到同一个嵌入空间,以便能够判断文字和图片的语义相似度。
向量归一化(Vector Normalization)
encode_text 将投影后的向量再次归一化后返回,得到最终结果:

