在 浅析 Embedding 模型 中,我们分析了 MedImageInsight 的 Text Encoder,本文将继续基于 lion-ai/MedImageInsights 版本(以下简称 MI2),分析其 Image Encoder,以及 MI2 是如何对图像和文本的嵌入结果进行相似度预测的。
模型结构
MedImageInsight/ImageEncoder 中实现了 Convolutional Swin Transformer 和 DaViT 两个版本的 Encoder。
在 2024.09.27/config.yaml 配置中指定了使用 davit_v1:
IMAGE_ENCODER:
NAME: davit_v1
...
IMAGE_SIZE: [480, 480]
...
SPEC:
...
PATCH_SIZE: [7, 3, 3, 3]
PATCH_STRIDE: [4, 2, 2, 2]
PATCH_PADDING: [3, 1, 1, 1]
...
DIM_EMBED: [256, 512, 1024, 2048]
NUM_HEADS: [8, 16, 32, 64]
NUM_GROUPS: [8, 16, 32, 64]
DEPTHS: [1, 1, 9, 1]
WINDOW_SIZE: 12
...按照上述配置,MI2 Image Encoder 接受的输入图像大小为 480 x 480,经过与 DaViT 论文中提出的模型相同的四个 stage 的卷积和 transformer 模块,最终输出一个 2048 维的特征向量。
| Output Size | Layer Name | MI2 Image Encoder | |
|---|---|---|---|
| stage 1 | 120 x 120 | Patch Embedding | kernel 7, stride 4, pad 3, C1 = 256 |
| stage 1 | 120 x 120 | Dual Transformer Block |
$\begin{bmatrix}\text{win. sz. } 12\times12, P_w=144\\N_h^1=N_g^1=8\\C_h^1=C_g^1=32\end{bmatrix}\times1$ |
| stage 2 | 60 x 60 | Patch Embedding | kernel 3, stride 2, pad 1, C2 = 512 |
| stage 2 | 60 x 60 | Dual Transformer Block |
$\begin{bmatrix}\text{win. sz. } 12\times12, P_w=144\\N_h^2=N_g^2=16\\C_h^2=C_g^2=32\end{bmatrix}\times1$ |
| stage 3 | 30 x 30 | Patch Embedding | kernel 3, stride 2, pad 1, C3 = 1024 |
| stage 3 | 30 x 30 | Dual Transformer Block |
$\begin{bmatrix}\text{win. sz. } 12\times12, P_w=144\\N_h^3=N_g^3=32\\C_h^3=C_g^3=32\end{bmatrix}\times9$ |
| stage 4 | 15 x 15 | Patch Embedding | kernel 3, stride 2, pad 1, C4 = 2048 |
| stage 4 | 15 x 15 | Dual Transformer Block |
$\begin{bmatrix}\text{win. sz. } 12\times12, P_w=144\\N_h^4=N_g^4=64\\C_h^4=C_g^4=32\end{bmatrix}\times1$ |
对比论文中的三个尺寸模型配置如下:

MI2 Image Encoder 的模型结构为:
(image_encoder): DaViT(
(convs): ModuleList(
(0): ConvEmbed(
(proj): Conv2d(3, 256, kernel_size=(7, 7), stride=(4, 4), padding=(3, 3))
(norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
(1): ConvEmbed(
(proj): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
(2): ConvEmbed(
(proj): Conv2d(512, 1024, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(3): ConvEmbed(
(proj): Conv2d(1024, 2048, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
(blocks): ModuleList(
(0): MySequential(
(0): MySequential(
(spatial_block): SpatialBlock(...)
(channel_block): ChannelBlock(...)
)
)
(1): MySequential(
(0): MySequential(
(spatial_block): SpatialBlock(...)
(channel_block): ChannelBlock(...)
)
)
(2): MySequential(
(0): MySequential(
(spatial_block): SpatialBlock(...)
(channel_block): ChannelBlock(...)
)
(1): MySequential(
(spatial_block): SpatialBlock(...)
(channel_block): ChannelBlock(...)
)
(2): MySequential(
(spatial_block): SpatialBlock(...)
(channel_block): ChannelBlock(...)
)
(3): MySequential(
(spatial_block): SpatialBlock(...)
(channel_block): ChannelBlock(...)
)
(4): MySequential(
(spatial_block): SpatialBlock(...)
(channel_block): ChannelBlock(...)
)
(5): MySequential(
(spatial_block): SpatialBlock(...)
(channel_block): ChannelBlock(...)
)
(6): MySequential(
(spatial_block): SpatialBlock(...)
(channel_block): ChannelBlock(...)
)
(7): MySequential(
(spatial_block): SpatialBlock(...)
(channel_block): ChannelBlock(...)
)
(8): MySequential(
(spatial_block): SpatialBlock(...)
(channel_block): ChannelBlock(...)
)
)
(3): MySequential(
(0): MySequential(
(spatial_block): SpatialBlock(...)
(channel_block): ChannelBlock(...)
)
)
)
(norms): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(avgpool): AdaptiveAvgPool1d(output_size=1)
(head): Identity()
)DaViT 简介
DaViT(Dual Attention Vision Transformers)是一种结合了空间注意力(Spatial Window Multihead Self-attention)和通道注意力(Channel Group Self-attention)的视觉 Transformer 模型。它通过在每个 Transformer 块中同时应用空间注意力和通道注意力来增强特征表示能力,从而提高模型在图像分类、目标检测等任务上的性能。
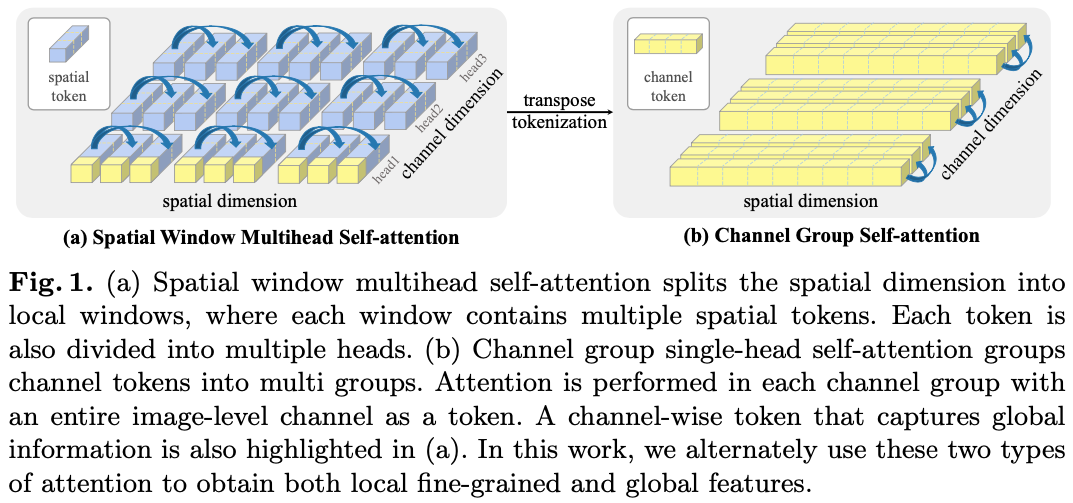
结合下图,可以更好的理解上面模型结构中的构块:
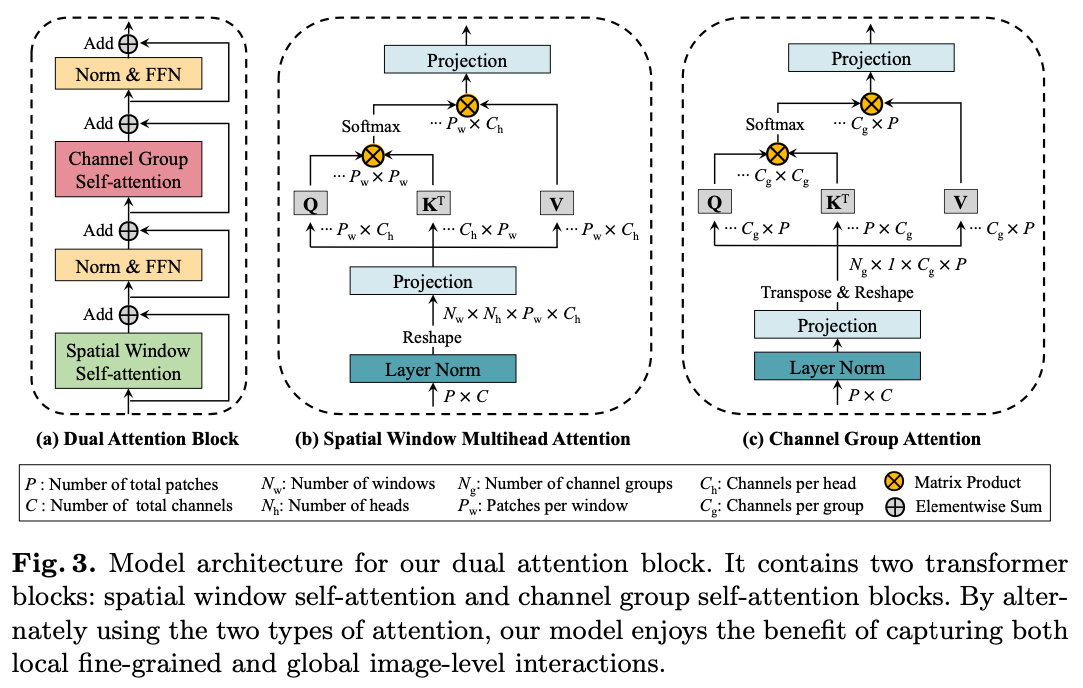
更详细的内容可阅读 DaViT: Dual Attention Vision Transformers 论文,或 DaViT:双注意力Vision Transformer。
模型权重
通过读取模型权重文件,可以观察各层的权重维度:
from safetensors.torch import load_file
pretrained = '2024.09.27/vision_model/medimageinsigt-v1.0.0.pt'
pretrained_dict = load_file(pretrained)
for key in pretrained_dict.keys():
print(f"{key:<70} {pretrained_dict.get(key).shape}")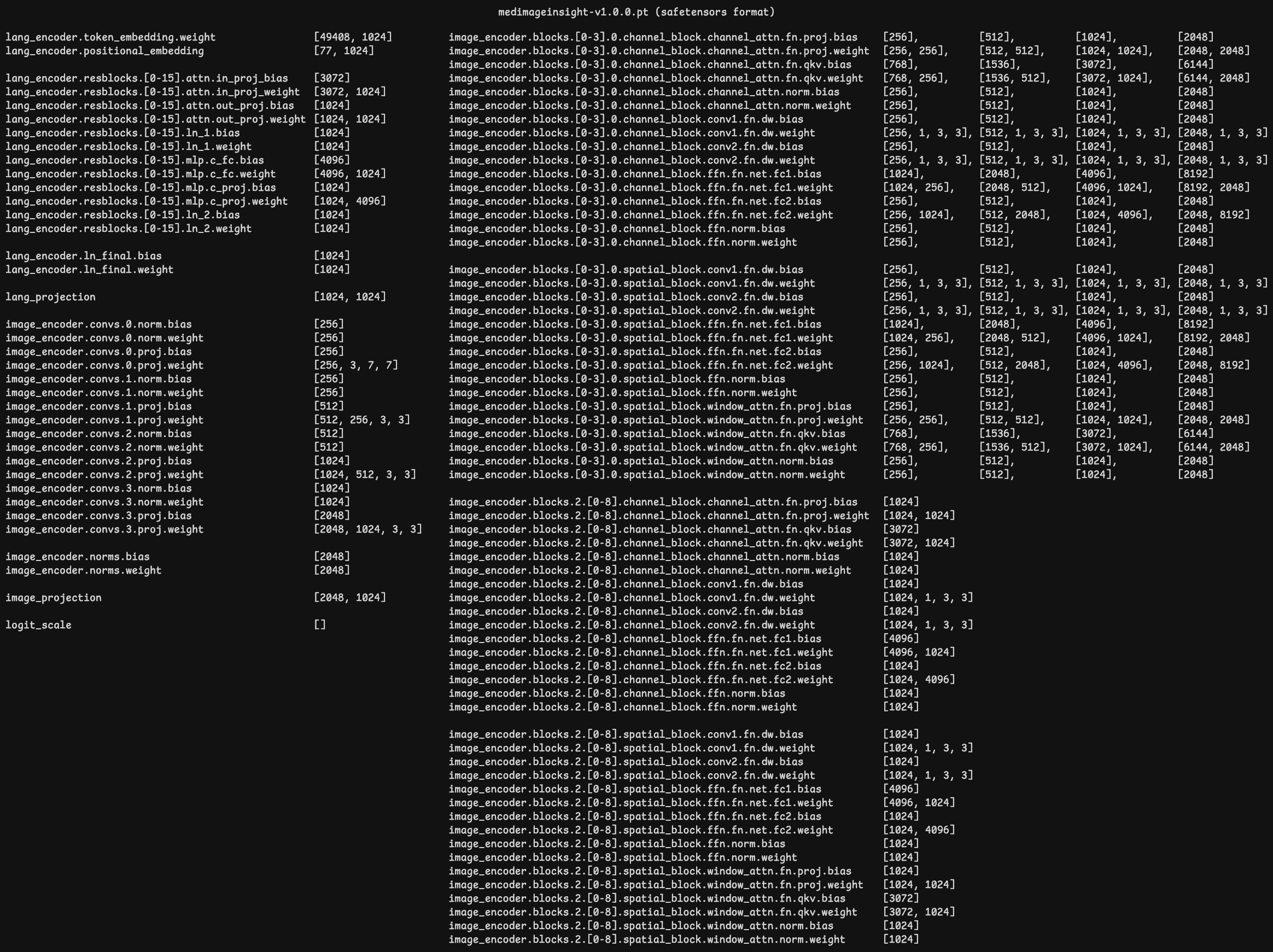
Encode 过程
以 https://openi.nlm.nih.gov/imgs/512/145/145/CXR145_IM-0290-1001.png 作为输入图片为例,encode 编码过程可大致分为三步:
- 预处理:将输入图像进行 resize、normalize 等预处理操作,使其符合模型输入要求。
- DaViT:将预处理后的图像输入 DaViT 模块,经过卷积和 transformer 模块的处理,得到一个 2048 维的特征向量。
- 对齐:将图像特征向量与文本特征向量通过投影矩阵进行对齐,使得它们在同一特征空间中进行相似度计算。
预处理
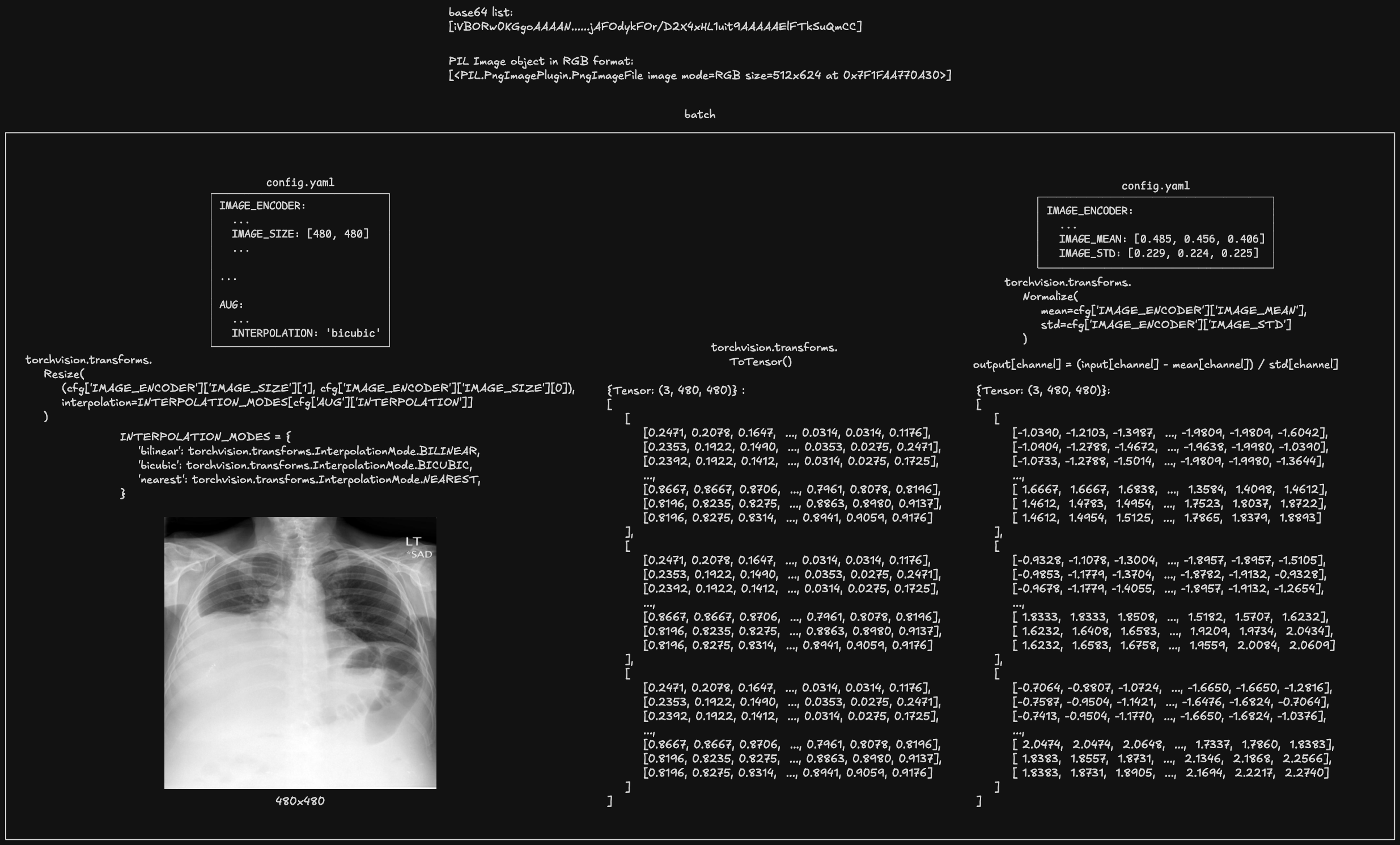
图像以 Base64 编码的字符串形式批量传递,首先通过 base64.b64decode 解码为二进制数据,然后使用 PIL.Image.open 将其转换为 PIL Image 对象。接着,图像被 resize 到 480 x 480 的大小,并进行转张量及 normalize 操作,使其符合模型输入要求。
此阶段输出的张量形状为 [1, 3, 480, 480],其中 1 是批次大小,3 是图像的通道数(RGB),480 x 480 是图像尺寸。
DaViT
预处理后的图像被输入 DaViT 模块,首先经过四个 stage 进行特征提取,每个 stage 包含一个卷积层和一个 Dual Transformer Block(stage 3 有九个)。卷积层通过不同的 kernel size、stride 和 padding 将图像逐渐 downsample,同时增加特征维度。Dual Transformer Block 则通过空间注意力和通道注意力机制进一步增强特征表示能力。
最终,经过全局平均池化和归一化处理,得到一个 2048 维的图像特征向量。
stage 1

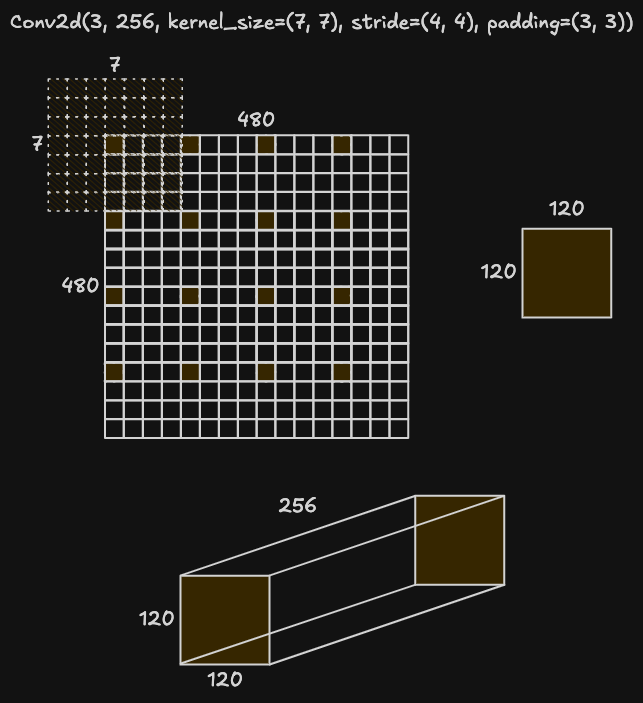
Stage 1 的卷积层 ConvEmbed 结构及权重矩阵维度如下:
(0): ConvEmbed(
(proj): Conv2d(3, 256, kernel_size=(7, 7), stride=(4, 4), padding=(3, 3))
(norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)image_encoder.convs.0.norm.bias [256]
image_encoder.convs.0.norm.weight [256]
image_encoder.convs.0.proj.bias [256]
image_encoder.convs.0.proj.weight [256, 3, 7, 7]前向传播时,ConvEmbed 的 forward 方法接受两个参数:代表图像特征的张量,以及图像尺寸。图像特征张量可以是 [batch, channels, height, width] 维度(如 stage 1 图中所示),也可以是 [batch, tokens, channels](后续 stage 中的情况),forward 方法会先将其统一至 [batch, channels, height, width](b c h w)形式,卷积投影后重排为 [batch, tokens, channels](b (h w) c),返回嵌入后的特征和更新后的尺寸。
def forward(self, x, size):
H, W = size
if len(x.size()) == 3:
if self.norm and self.pre_norm:
x = self.norm(x)
x = rearrange(
x, 'b (h w) c -> b c h w',
h=H, w=W
)
x = self.proj(x)
_, _, H, W = x.shape
x = rearrange(x, 'b c h w -> b (h w) c')
if self.norm and not self.pre_norm:
x = self.norm(x)
return x, (H, W)Conv2d 是一个多通道的二维卷积:
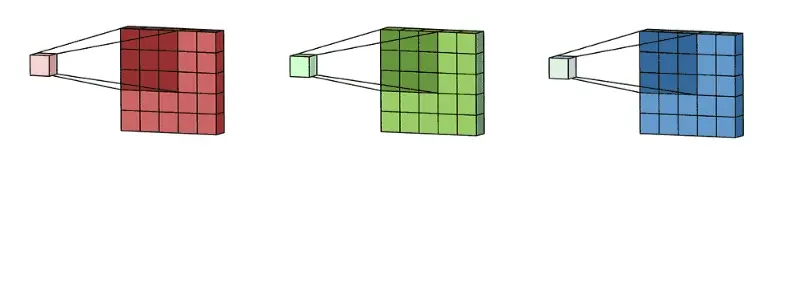
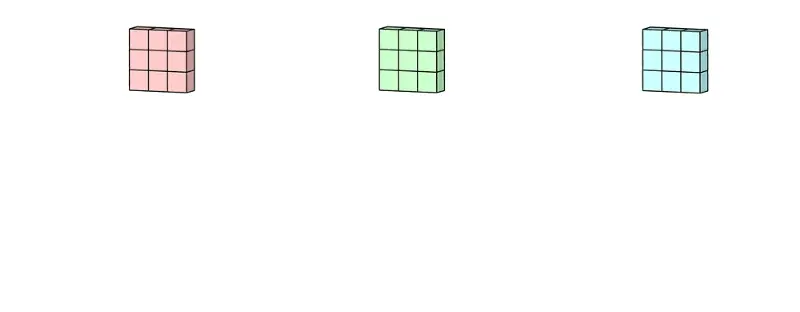
可将输入 $(N, C_{\text{in}}, H, W)$ 转换为 $(N, C_{\text{out}}, H_{\text{out}}, W_{\text{out}})$,具体公式如下:
$$
\text{out}(N_i, C_{\text{out}_j}) = \text{bias}(C_{\text{out}_j}) +
\sum_{k = 0}^{C_{\text{in}} - 1} \text{weight}(C_{\text{out}_j}, k) \star \text{input}(N_i, k)
$$
其中 $\star$ 相当于单通道二维卷积,$N$ 是批次大小(本例中只有一个批次),$C$ 表示通道数(stage 1 中 $C_{in}=3$,$C_{out}=256$),$H$ 是图像像素高度,$W$ 是宽度。
其他 stage
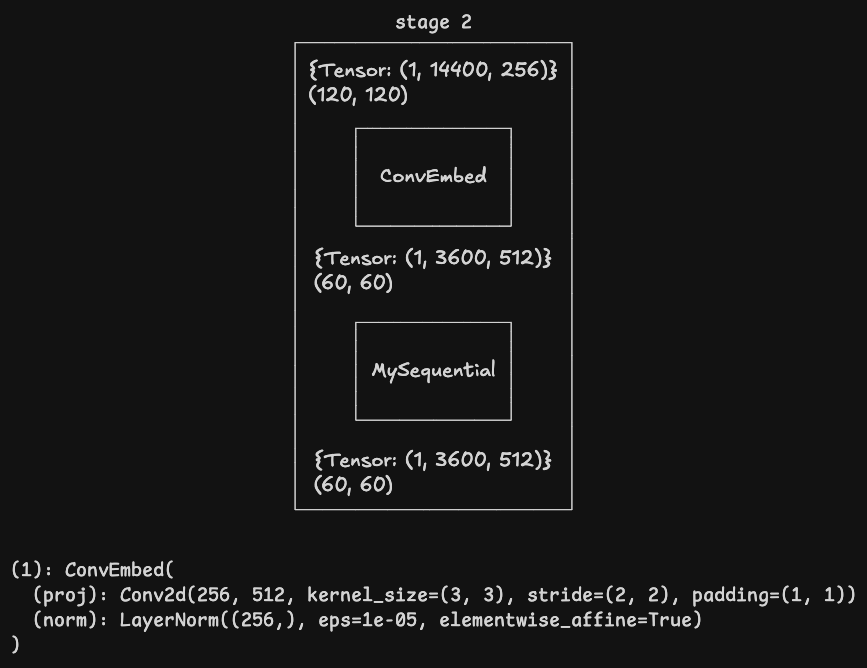
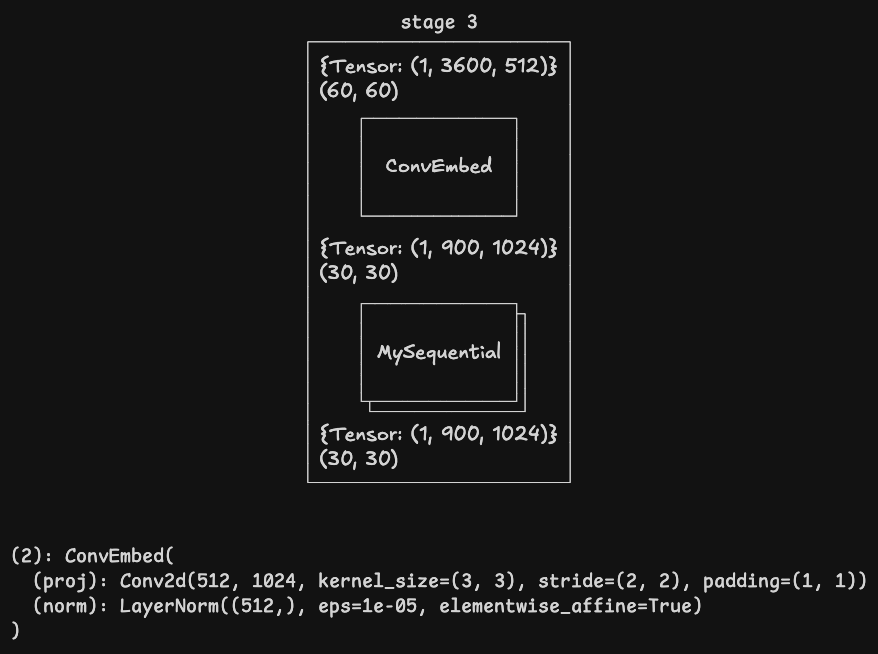
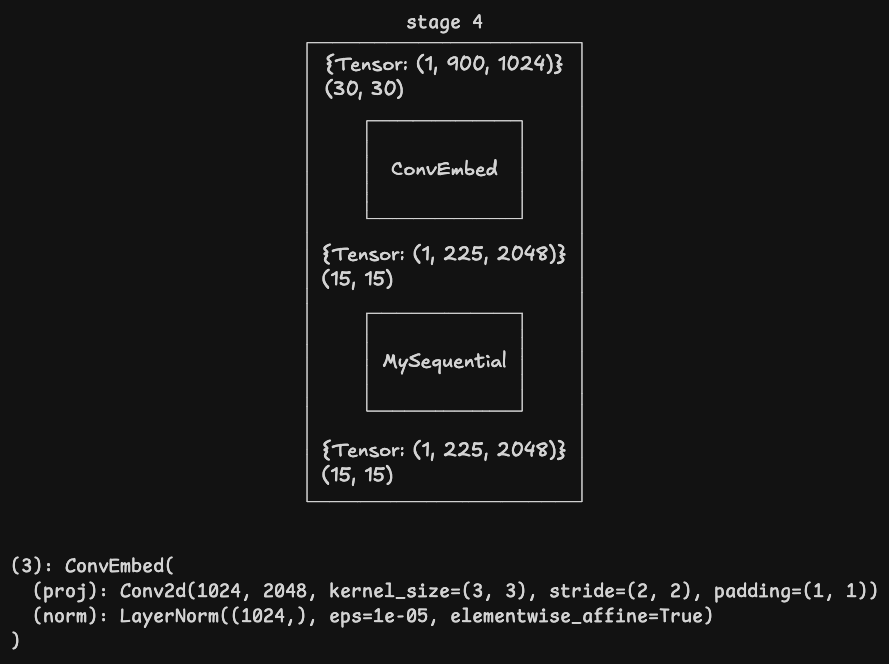
经过 stage 4 后输出的张量形状为 [1, 255, 2048],其中 1 是批次大小,255 是图像特征 15 x 15 阶矩阵的按行连接,2048 是通道数。
平均池化及归一化
对每个通道的图像特征做平均池化及归一化,得到一个 2048 维的图像特征向量。
x = self.avgpool(x.transpose(1, 2))
x = torch.flatten(x, 1)
x = self.norms(x)(avgpool): AdaptiveAvgPool1d(output_size=1)
(norms): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)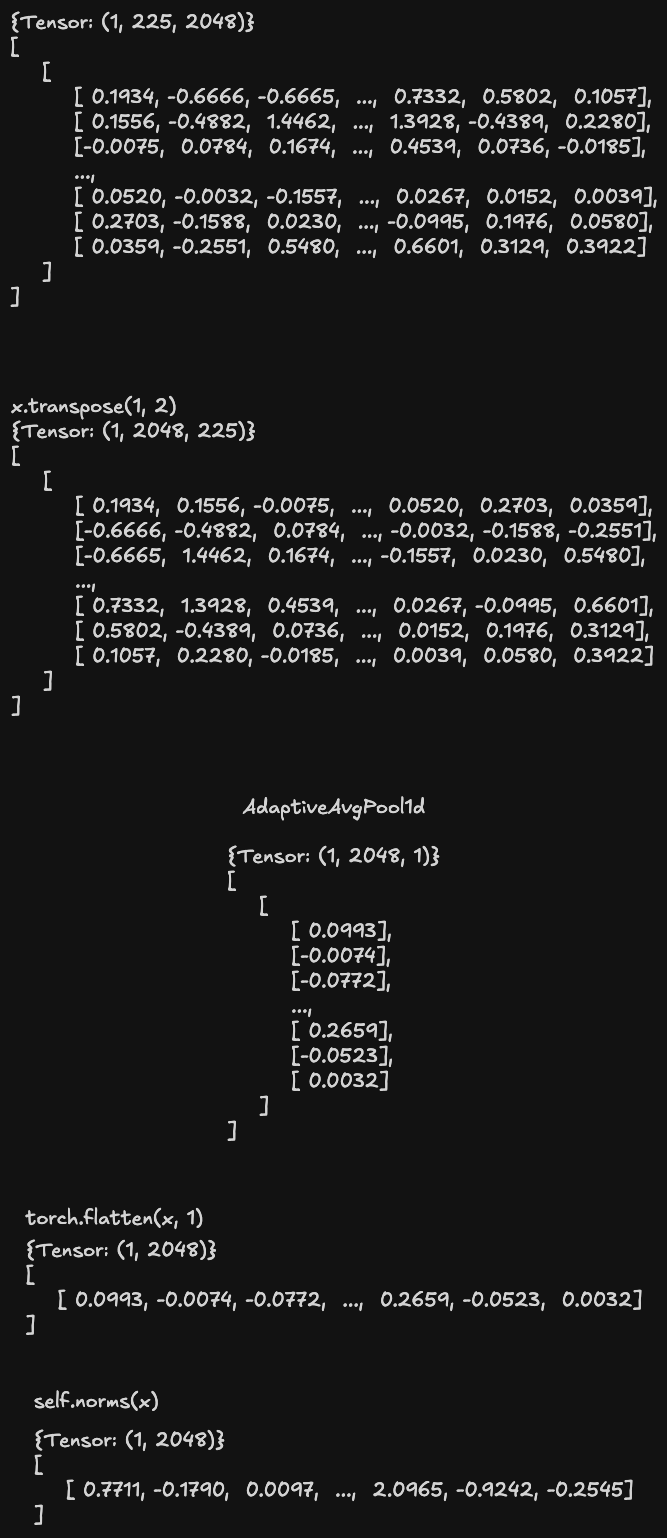
至此,已基本完成图像的向量嵌入。
对齐
为了与文本的嵌入向量进行相似度比较,还需要对齐图像和文本的嵌入向量,以获得相同向量空间的投影,并再次归一化。
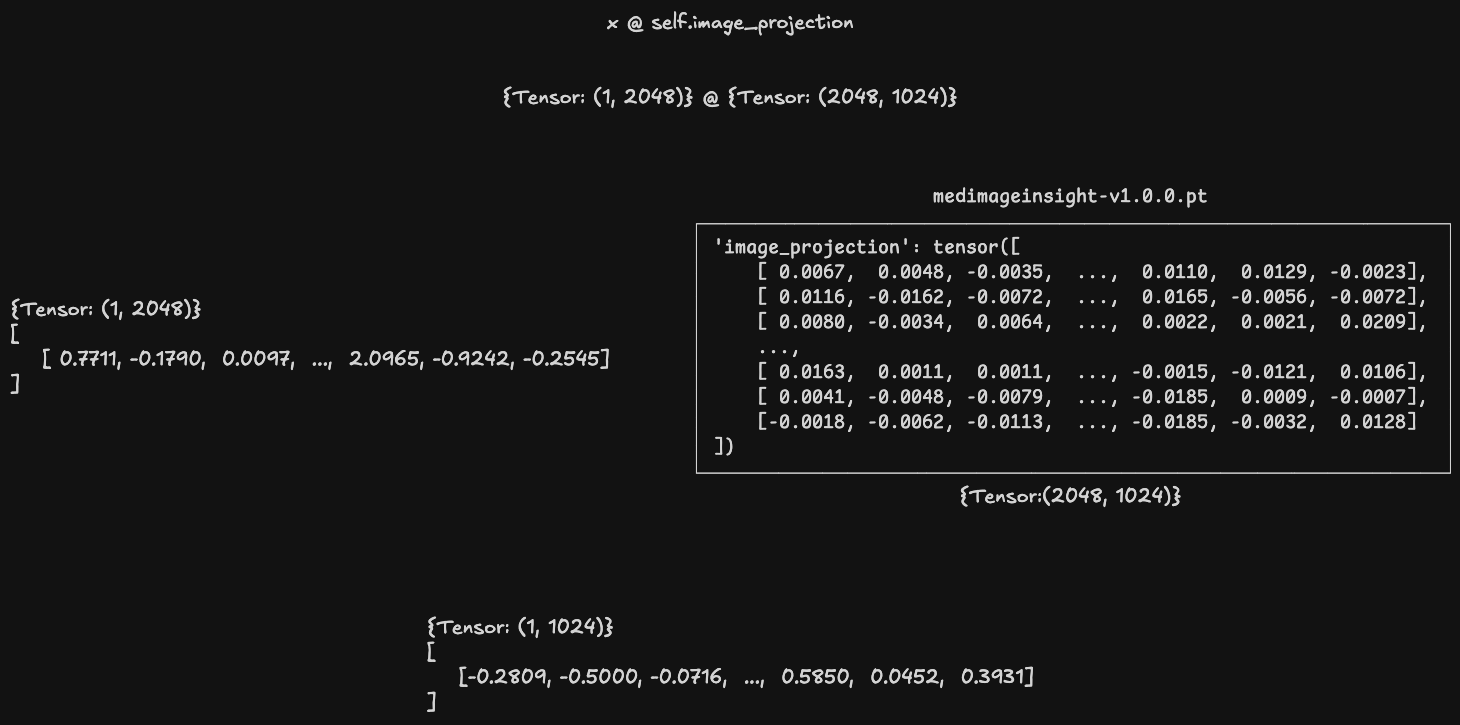

Predict
MI2 在预测图像和文本相似度时,调用 run_inference_batch 方法,计算每对图像和文本向量的余弦相似度,再用一个预训练的缩放参数放大相似度值,增强区分性:
# Run inference
with torch.no_grad():
outputs = self.model(image=images, text=text_tokens)
logits_per_image = outputs[0] @ outputs[1].t() * outputs[2]
if multilabel:
# Use sigmoid for independent probabilities per label
probs = torch.sigmoid(logits_per_image)
else:
# Use softmax for single-label classification
probs = logits_per_image.softmax(dim=1)其中 outputs 是图像向量矩阵、文本向量矩阵和缩放参数常量的集合:
def forward(self, image, text):
features_image = self.encode_image(image)
features_text = self.encode_text(text)
# cosine similarity as logits
T = self.logit_scale.exp()
return features_image, features_text, T余弦相似度计算方式为:
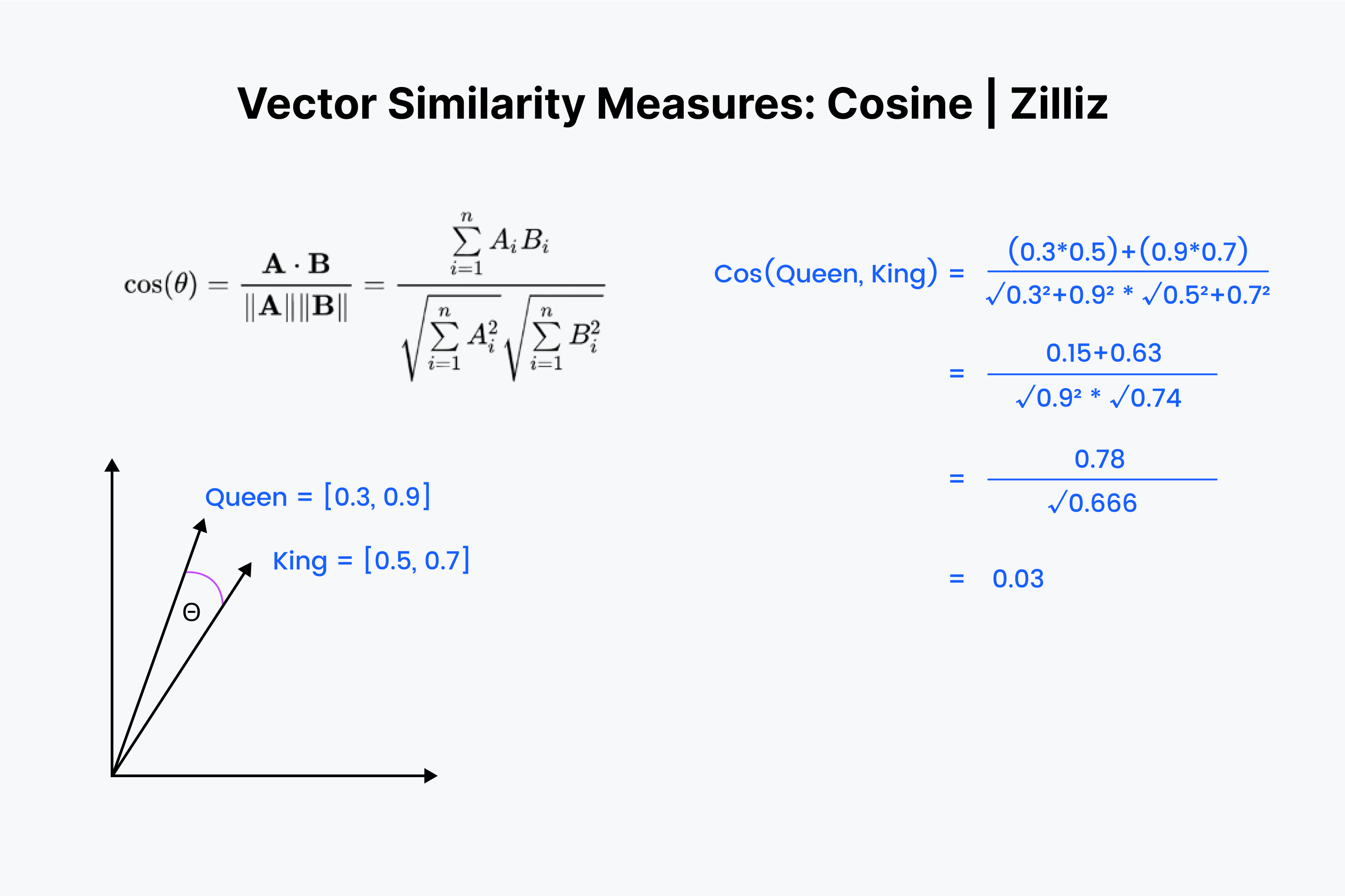
因为 MI2 的 Image Encoder 和 Text Encoder 最后都进行了归一化,此时计算余弦相似度与计算内积等同: