作者:@weiliang-ms
1. Memory Manager介绍说明
Memory Manager(译为内存管理器)是 kubelet 内部的一个组件,旨在为 Guaranteed QoS 类型 pod 提供保证内存(和大页内存)分配功能,该特性提供了几种分配策略:
- 单 NUMA 策略:用于高性能和性能敏感的应用程序
- 多 NUMA 策略:补充完善单 NUMA 策略无法管理的情况
也就是说,只要 pod 所需的内存量超过单个 NUMA 节点的容量,就会使用多 NUMA 策略跨多个 NUMA 节点提供保证的内存。
在这两种场景中,内存管理器都使用提示生成协议为 pod 生成最合适的 NUMA 关联,并将这些关联提示提供给中央管理器(Topology Manager)。此外,内存管理器确保 pod 请求的内存从最小数量的 NUMA 节点分配。
从技术上讲,单 NUMA 策略是多 NUMA 策略的一种特殊情况,因此 kubernetes 开发团队没有为它们开发单独的实现。
1.1 什么是NUMA?
早期的计算机,内存控制器还没有整合进 CPU,所有的内存访问都需要经过北桥芯片来完成。如下图所示,CPU 通过前端总线(FSB,Front Side Bus)连接到北桥芯片,然后北桥芯片连接到内存——内存控制器集成在北桥芯片里面。
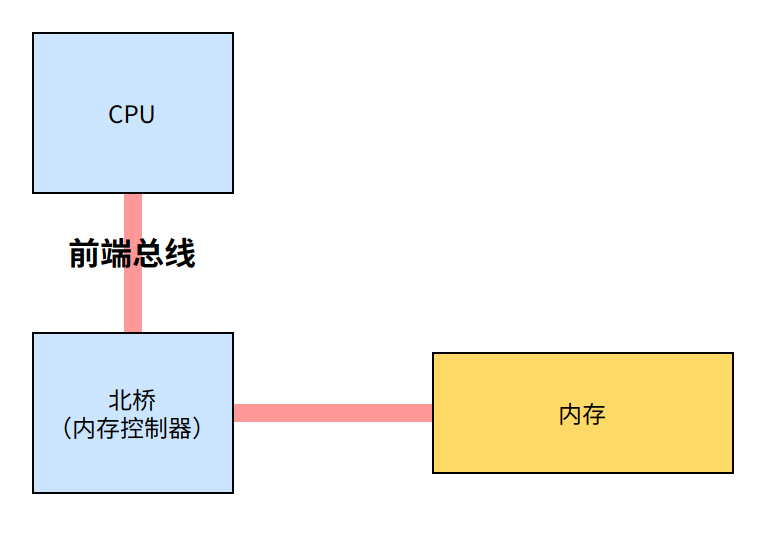
上面这种架构被称为 UMA(Uniform Memory Access, 一致性内存访问 ):总线模型保证了 CPU 的所有内存访问都是一致的,不必考虑不同内存地址之间的差异。
在 UMA 架构下,CPU 和内存之间的通信全部都要通过前端总线。而提高性能的方式,就是不断地提高 CPU、前端总线和内存的工作频率。
由于物理条件的限制,不断提高工作频率的方式接近瓶颈。CPU 性能的提升开始从提高主频转向增加 CPU 数量(多核、多 CPU)。越来越多的 CPU 对前端总线的争用,使前端总线成为了瓶颈。为了消除 UMA 架构的瓶颈,NUMA(Non-Uniform Memory Access, 非一致性内存访问)架构诞生了:
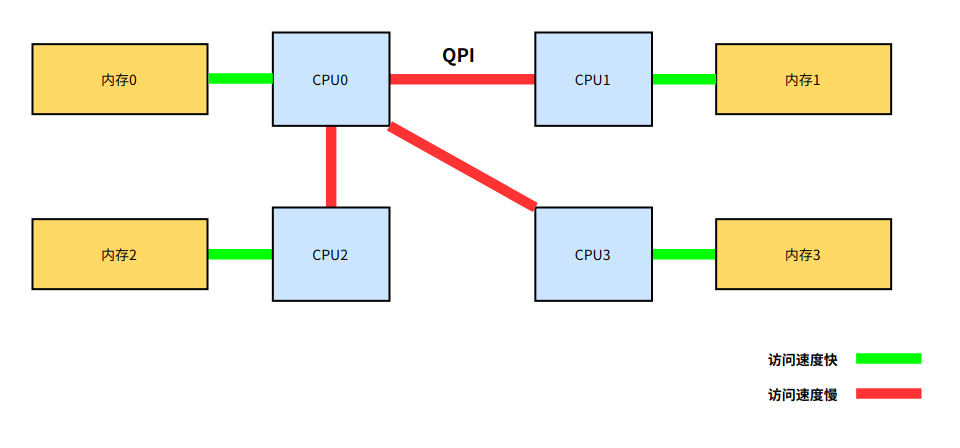
- CPU 厂商把内存控制器集成到 CPU 内部,一般一个 CPU socket 会有一个独立的内存控制器。
- 每个 CPU scoket 独立连接到一部分内存,这部分 CPU 直连的内存称为“本地内存”。
- CPU 之间通过 QPI(Quick Path Interconnect) 总线进行连接。CPU 可以通过 QPI 总线访问不和自己直连的“远程内存”。
和 UMA 架构不同,在 NUMA 架构下,内存的访问出现了本地和远程的区别:访问远程内存的延时会明显高于访问本地内存。
1.2 什么是大页内存?
大页内存(HugePages),有时也叫“大内存页”、“内存大页”、“标准大页”。计算机内存以页的形式分配给进程。通常这些页相当小,这意味着消耗大量内存的进程也将消耗大量的页。对于那些内存操作非常频繁的业务来说,大页内存可以有效的提高性能。简而言之,通过启用大页内存,系统只需要处理较少的页面映射表,从而减少访问/维护它们的开销!大页内存在数据库服务器这样的系统上特别有用。像 MySQL 和 PostgreSQL 这样的进程可以使用大页内存,以减少对 RAM 缓存的压力。
1.3 什么是Guaranteed QoS pod?
Kubernetes 通过 服务质量类(Quality of Service class,QoS class) 定义了三种 pod 类型, Kubernetes 在 Node 资源不足时使用 QoS 类来就驱逐 Pod 作出决定:
- Guaranteed:pod 中 每个容器 limits.cpu == requests.cpu && limits.memory== requests.memory. Guaranteed 类型 Pod 具有最严格的资源限制,并且最不可能面临驱逐。
- Burstable: Pod 中至少一个容器有内存或 CPU 的 request 或 limit 且非 Guaranteed。
- BestEffort:Pod 不满足 Guaranteed 或 Burstable 的判据条件,即Pod 中的所有容器没有设置内存 limit 或内存 request,也没有设置 CPU limit 或 CPU request 。
三种 pod 优先级:Guaranteed > Burstable > BestEffort
2. Memory Manager开发动机
- 为容器(同一 pod 内的容器)提供最小数量的 NUMA 节点上有保证的内存(和大页内存)分配。
- 保证整个容器组(同一 pod 内的容器)的内存和大页面与相同 NUMA 节点的关联。
内存管理器的设计应用对于性能敏感的程序、数据库、虚拟化影响巨大:
由于数据库(例如,Oracle, PostgreSQL和MySQL)需要相对大量的内存和大页内存,来相对有效地访问大量数据。而为了减少由跨 NUMA 内存访问和共享引起的延迟,所有资源(CPU内核、内存、大页内存和I/O设备)都应该对齐到同一个 NUMA 节点,这将极大地提高稳定性和性能。
并且内存数据库(Redis等)具有更大的内存需求,可以扩展到多个 NUMA 节点。这就产生了跨多个 NUMA 节点维持和管理内存的需求。
3. Memory Manager架构设计
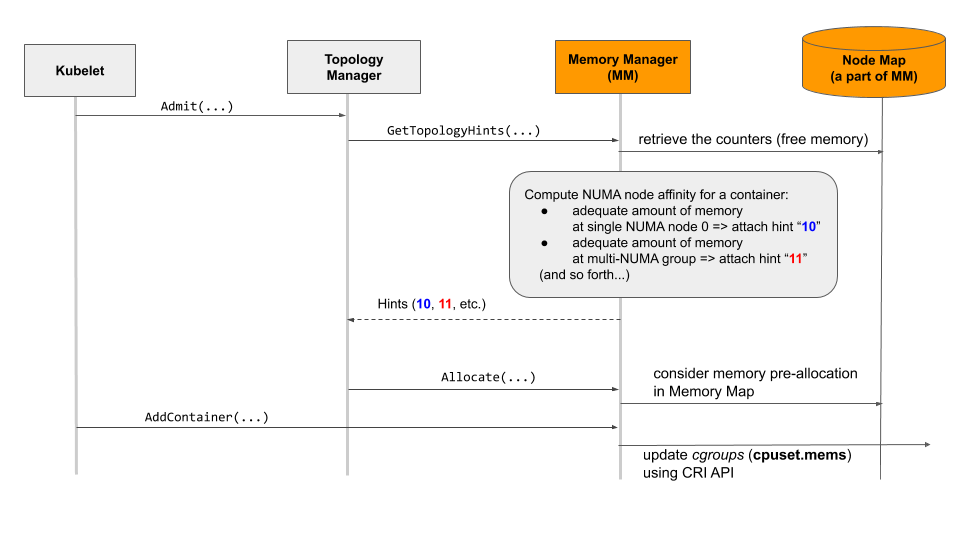
一旦 kubelet 请求 Guaranteed QoS 类型 pod 许可,如上图所示,拓扑管理器(Topology Manager)就会向内存管理器 (Memory Manager) 查询 pod 中所有容器的内存和大页内存的首选 NUMA 亲和关系。
对于 pod 中的每个容器,内存管理器使用其内部数据库(即Node Map)计算关联。Node Map 是一个对象,它负责跟踪 Guaranteed QoS 类 Pod 中所有容器的内存(和大页内存)的使用情况。一旦内存管理器完成计算,它将结果返回给拓扑管理器,以便拓扑管理器可以计算出哪个 NUMA 节点或一组 NUMA 节点最适合容器的内存固定。对 pod 中的所有容器执行总体计算,如果没有容器被拒绝,则 kubelet 最终接收并部署该 pod。
在 pod 接收阶段,内存管理器调用 Allocate() 方法并更新其 Node Map 对象。随后内存管理器调用 AddContainer() 方法并强制分配容器的内存和大页内存,并限制到对应 NUMA 节点或 NUMA 节点组。最终通过CRI 接口更新控制组配置项(cpuset.mems项)。
内存管理器为(且仅为) Guaranteed QoS类中的pod提供有保证的内存分配。
3.1 多NUMA节点保证内存分配原理
主要思想是将一组 NUMA 节点视为一个独立的单元,并由内存管理器管理这些独立的单元。
NUMA 节点组不能相交。下面的图举例说明了一组不相交的 NUMA 组。图中的组是不相交的,即:[0],[1,2],[3]。必须遵守该规则,因为重叠的组基本上不能确保在多个 NUMA 节点上有保证的内存分配。
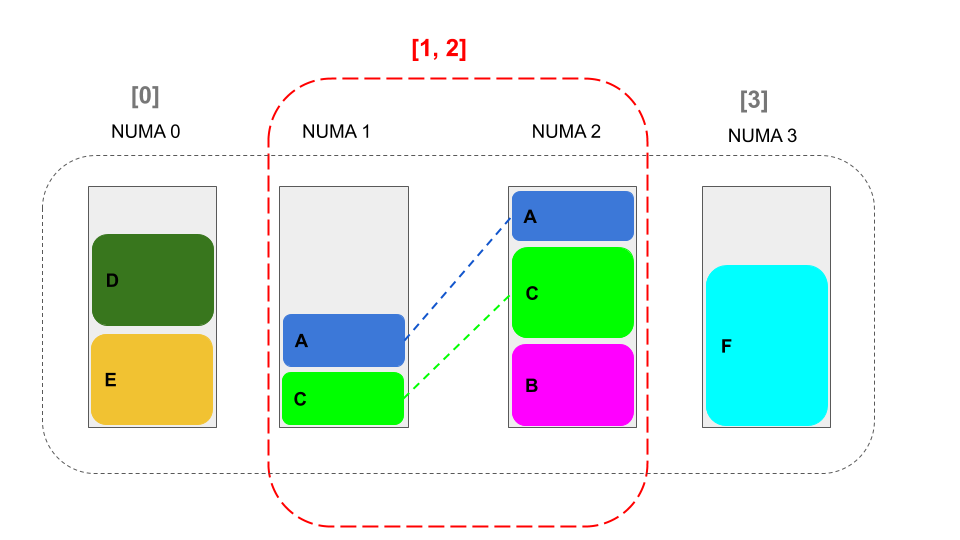
例如,以下组重叠,[0,1],[1,2]和[3],因为它们有一个以1为索引的公共 NUMA 节点。换句话说,如果组重叠(比如:[0,1]和[1,2]),则[1,2]组的内存资源可能会优先被另一组([0,1])消耗,[1,2]组可用内存资源会被抢占。
3.2 节点映射(Node Map)
内存管理器有一个内部数据库,即节点映射(Node Map),它包含内存映射(Memory Map)。该数据库用于记录在 Guaranteed QoS 类中为已部署的容器保留的内存。节点映射对象记录 Node 对象中不相交的 NUMA-node组的动态配置。注意,实际上内存映射提供了跟踪内存的计数器。因此,不应该将映射理解为允许保留内存范围或连续内存块的映射。
在部署容器时,还使用映射来计算NUMA关联。内存管理器支持传统内存和各种可能大小的大页内存(例如2 MiB或1 GiB),节点向内存管理器提供三种类型的内存,即:常规内存、hugepages-1Gi和hugepages-2Mi。
在启动时,内存管理器为每个 NUMA 节点和各自的内存类型初始化一个 Memory Table 集合,从而生成准备使用的内存映射对象。
// MemoryTable 包含内存信息
type MemoryTable struct {
TotalMemSize uint64 `json:"total"`
SystemReserved uint64 `json:"systemReserved"`
Allocatable uint64 `json:"allocatable"`
Reserved uint64 `json:"reserved"`
Free uint64 `json:"free"`
}
// NodeState 包含 NUMA 节点关联信息
type NodeState struct {
// NumberOfAssignments contains a number memory assignments from this node
// When the container requires memory and hugepages it will increase number of assignments by two
NumberOfAssignments int `json:"numberOfAssignments"`
// MemoryTable 包含 NUMA 节点内存关联信息
MemoryMap map[v1.ResourceName]*MemoryTable `json:"memoryMap"`
// NodeGroups contains NUMA nodes that current NUMA node in group with them
// It means that we have container that pinned to the current NUMA node and all group nodes
Nodes []int `json:"nodes"`
}
// NodeMap 包含 每个 NUMA 节点的内存信息.
type NodeMap map[int]*NodeState3.3 内存映射(Memory Map)
内存映射用于跟踪每个 NUMA 节点的内存使用情况。内存映射包含几个计数器,用于跟踪内存使用情况。存在以下等式:
Allocatable = TotalMemSize - SystemReserved
Free + Reserved = Allocatable
Free = Allocatable - Reserved
Reserved = Allocatable - Free- TotalMemSize 的值由 cadvisor 为每种内存类型(常规内存、hugepages-1Gi等)提供给内存管理器。TotalMemSize 的值是恒定的,表示 NUMA 节点上可用的特定类型内存的总(最大)容量。
- SystemReserved 由 systemReserved 配置项设置,表示预留给系统服务的资源大小(如kubelet、其他系统服务)
- Reserved 表示 Guaranteed QoS 类型 pod 中为容器预留的保证内存总量
3.3.1 启动阶段内存映射
下图展示了节点启动后不久的内存映射(常规内存):
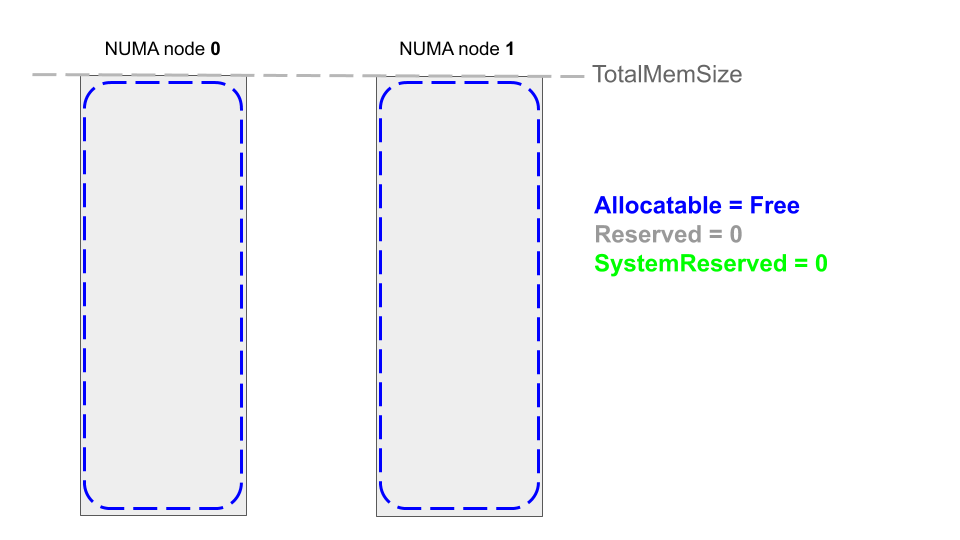
SystemReserved 的值是由 kubelet 启动参数预先配置。SystemReserved 在运行时保持不变,因此Allocatable在运行时也是不变的。
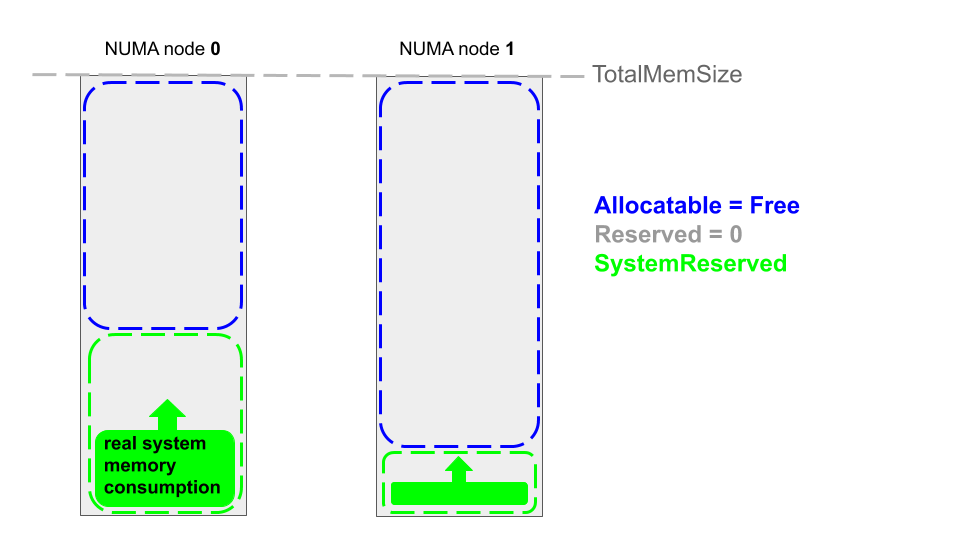
SystemReserved 表示系统预留的内存大小,用于系统,即内核、操作系统守护进程和核心节点组件,如 kubelet (kubelet守护进程)。
3.3.2 运行阶段内存映射
下图中,容器A和容器B实际消耗的内存(红色色块、紫色色块)少于内存管理器保留的(保证内存)内存大小(红色虚线框、紫色虚线框),所以对于两个容器来说,它们的内存消耗都低于它们的内存限制(limits.memroy),并且容器正常运行。
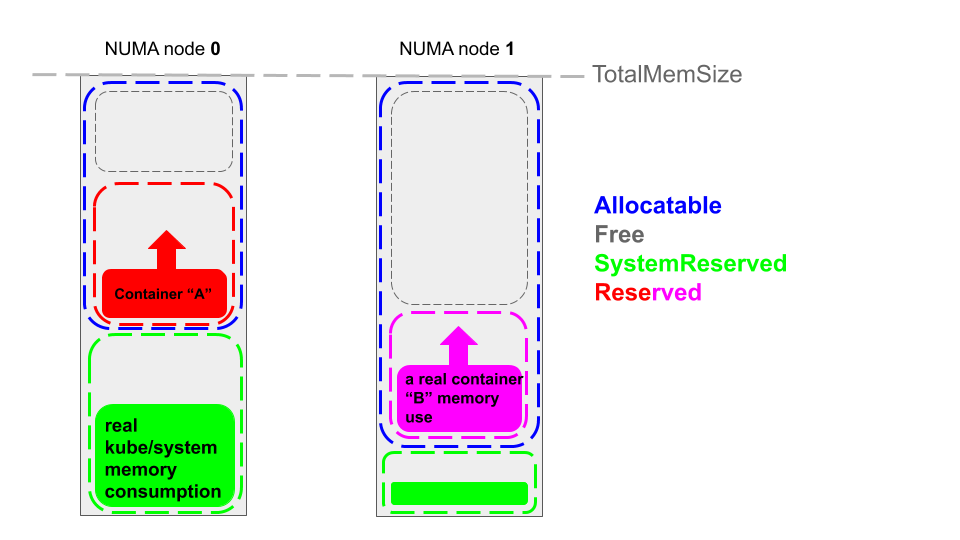
当 kubernetes 节点发生 OOM 时(cgroups内存限制、hard-eviction-treshold 等),由 kubelet、系统内核(linux oom killer)进行处理,而非由内存管理器处理。
3.4 工作方式
下面展示内存管理器如何管理不同 QoS 类(Guaranteed, bestefort /Burstable)中的 pod,以及内存管理器如何动态管理(创建或删除) NUMA 节点的非相交组。
3.4.1 多NUMA节点
创建 pod1 ,其中 pod1 内存配额为15G,且 requests.memory == limits.memory (即Guaranteed QoS 类型pod)
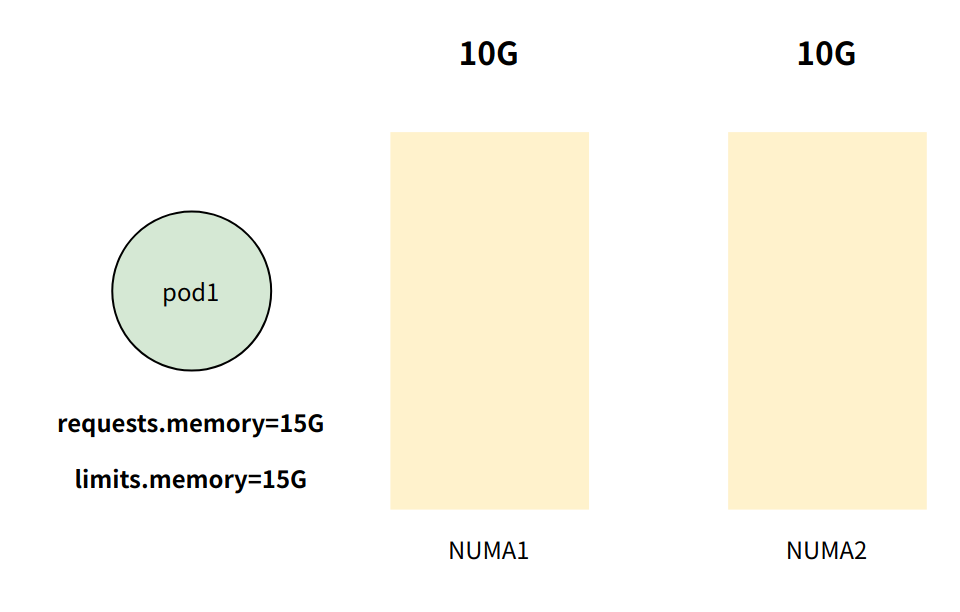
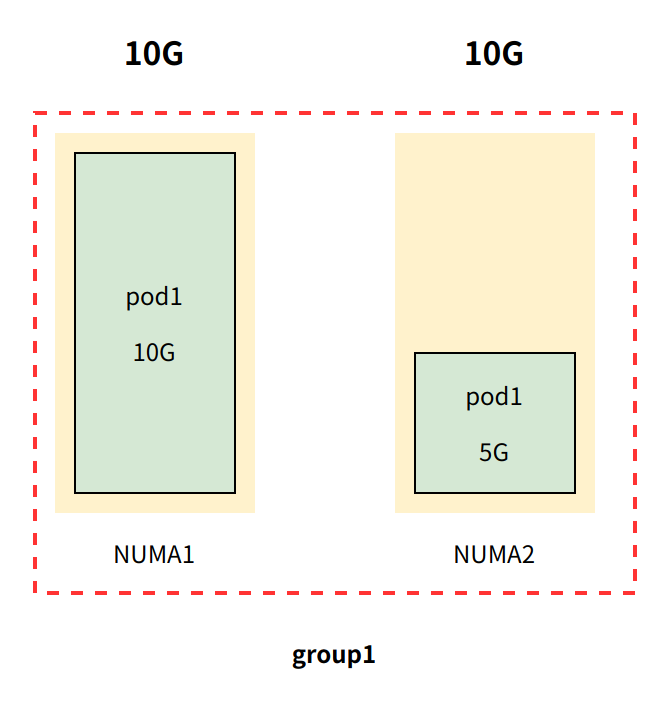
内存管理器随后创建 名为 group1 的组,group1 包含 NUMA 节点与 pod1,同时更新 pod1 控制组cpuset.mems 参数[[0,1], 15G]
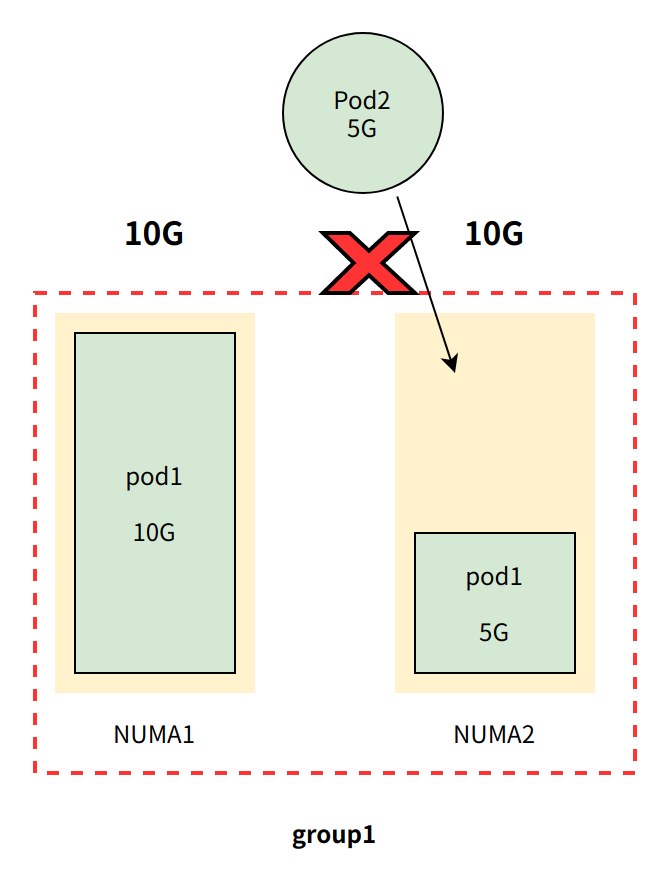
创建 pod2 ,其中 pod2 内存配额为5G,且 requests.memory == limits.memory (即Guaranteed QoS 类型pod)
尽管 group1剩余内存(5G)满足 Pod2 内存需求(5G),但由于 group1 是多 NUMA 节点,集群节点中存在能满足 pod2 内存需求的单 NUMA 节点(假设存在), 所以 pod2 准入请求将被拒绝。
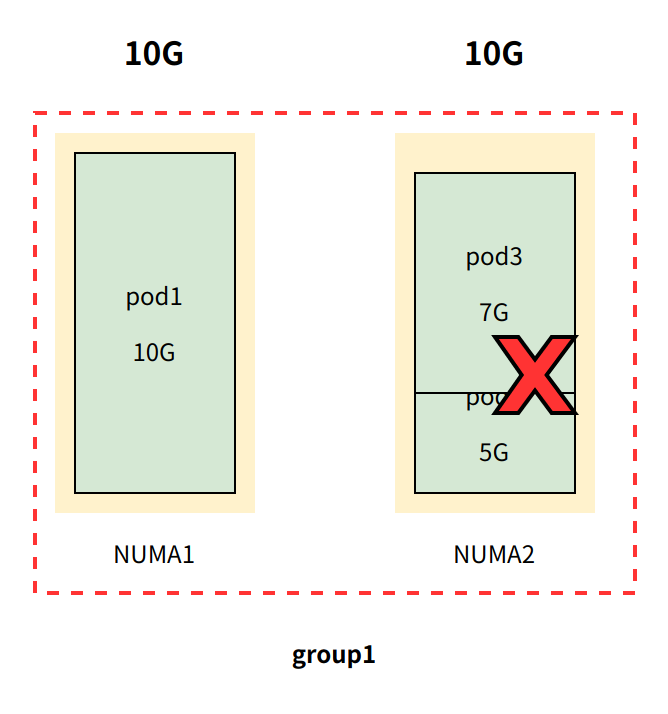
当 pod3 (非Guaranteed QoS类型)尝试加入 group1 时,将被放行 。这是为什么呢?
因为内存管理器只管理 Guaranteed QoS类型 Pod,对于非Guaranteed QoS类型Pod一律放行准入。
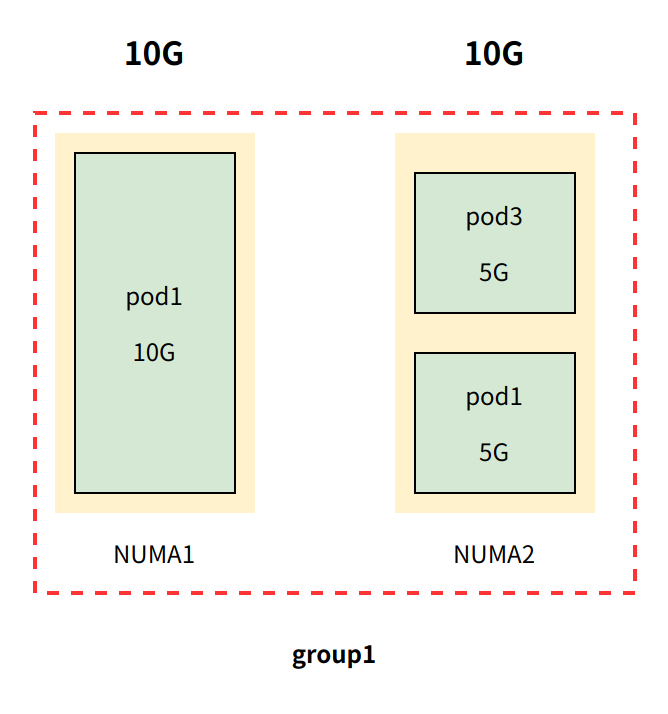
由于 pod3 是非Guaranteed QoS类型 pod , pod3 内存使用有可能会超过 5G 时,当出现这种情况时将会将触发 OOM。这种 OOM 情况有两种处理机制:
kubelet 触发 pod 驱逐机制,进而释放出更多可用内存
触发linux OOM killer,优先 kill 低优先级进程(如:BestEffort/QoS、Burstable/QoS类型 pod)
两种机制优先级:kubelet > linux OOM killer
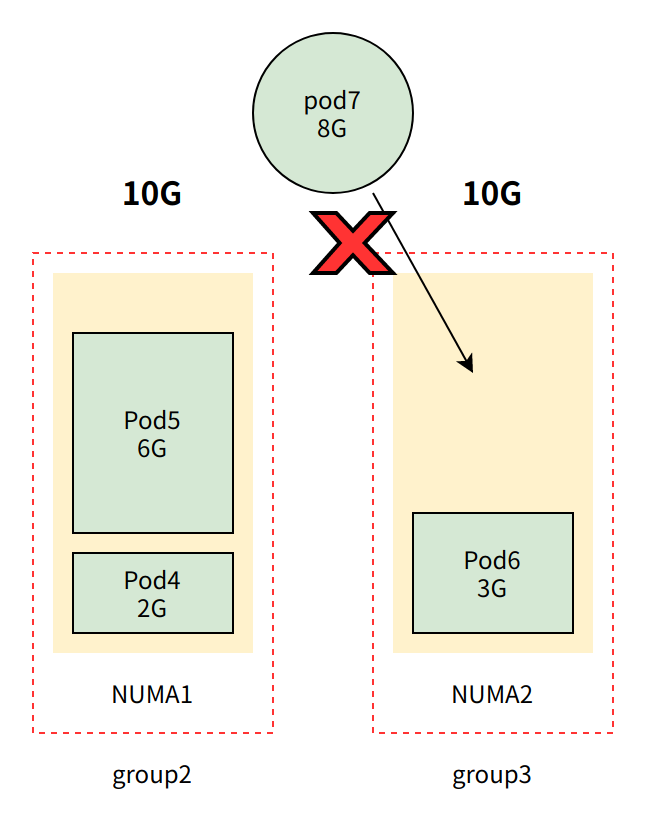
3.4.2 单NUMA节点
创建 pod4 ,其中 pod4 内存配额为2G,且 requests.memory == limits.memory (即Guaranteed QoS 类型pod)
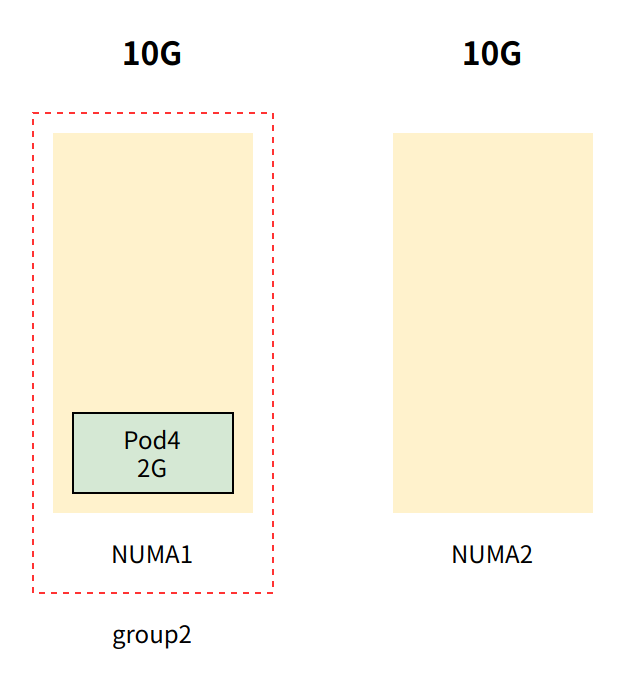
内存管理器随后创建 名为 group2 的组,group2 包含 NUMA 节点与 pod4
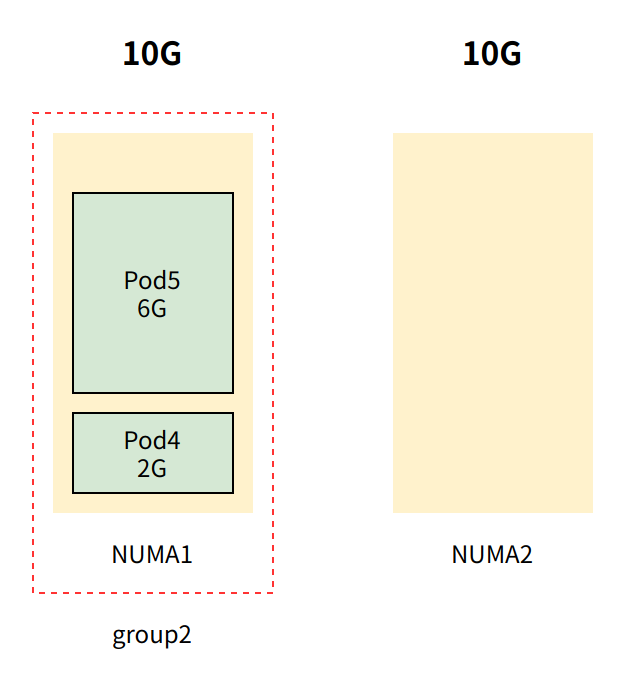
创建 pod5 ,其中 pod5内存配额为6G,且 requests.memory == limits.memory (即Guaranteed QoS 类型pod)
由于group2仍有8G可用内存,pod5将被加入到group2
创建 pod6 ,其中 pod6内存配额为3G,且 requests.memory == limits.memory (即Guaranteed QoS 类型pod),由于group2仅有2G可用内存,pod6将被加入到group3
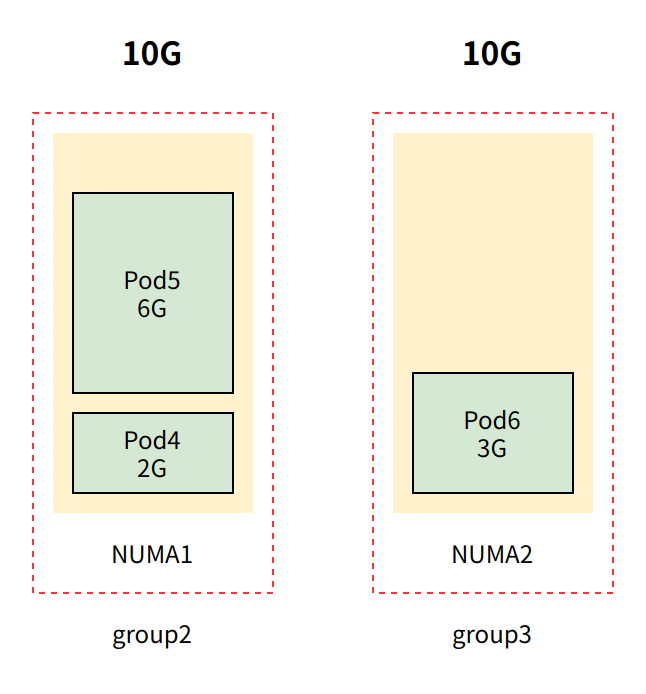
创建 pod7 ,其中 pod6内存配额为8G,且 requests.memory == limits.memory (即Guaranteed QoS 类型pod),由于group3仅有7G可用内存,pod7准入请求将被拒绝。(尽管group2 + group3 剩余容量之和满pod7,但无法跨group)