- 原文地址:https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/
- 作者:Jay Alammar
注意: 下面的动画是视频。轻触或(使用鼠标)悬停在它们上,可获得播放控件,以便在需要时暂停。
序列到序列(Sequence-to-sequence)模型是一种深度学习模型,在诸如机器翻译、文本摘要和图像标题生成等任务中取得了许多成功。Google Translate 在 2016 年底开始在生产环境中 使用 这种模型。这些模型在两篇开创性论文(Sutskever et al., 2014, Cho et al., 2014)中进行了说明。
然而我发现,充分理解并实现模型需要逐步揭示一系列相互依存的概念。我认为这些概念以视觉方式表达会更加易于理解。这就是我在本文试图做的。阅读本文需要对深度学习有一定的了解。我希望本文可以成为您阅读上面提到的论文(和本文之后引用的注意力论文)的得力助手。
序列到序列模型是一种将一系列项目(如单词、字母、图像的特征等)输入并输出一系列其他项目的模型。一个训练过的模型将以如下方式工作:
在神经机器翻译中,序列是一系列单词,逐个处理后,输出也是一系列单词:
深入了解
在内部,该模型由一个 编码器 encoder 和一个 解码器 decoder 组成。
编码器 encoder 处理输入序列中的每个项目,并将其捕获的信息编译成一个向量(称为 上下文 context)。在处理完整个输入序列之后,编码器 encoder 将上下文 context 发送给解码器 decoder,解码器开始逐个生成输出序列的项目。
机器翻译也是相同的情况。
在机器翻译中,context 是一个向量(基本上是由数字组成的数组)。编码器 encoder 和解码器 decoder 通常都是循环神经网络(recurrent neural networks,RNN)。请务必查看 Luis Serrano 的 A friendly introduction to Recurrent Neural Networks 以了解 RNN 的基础知识。
 上下文 context 是浮点数组成的向量。稍后我们在本文中将以颜色可视化向量,将更高值的单元格分配更亮的颜色。
上下文 context 是浮点数组成的向量。稍后我们在本文中将以颜色可视化向量,将更高值的单元格分配更亮的颜色。
在设置您的模型时,您可以设置上下文 context 向量的大小。基本上,这是在 RNN 编码器 encoder 中的隐藏单元数量。这些可视化展示了一个大小为 4 的向量,但在现实应用中,上下文 context 向量大小可能会是 256、512 或 1024 等。
按设计,RNN 在每个时间步骤中接受两个输入:一个输入(在编码器的情况下,是输入句子中的一个单词)和一个隐藏状态。并且,单词需要用向量来表示。为了将单词转化为向量,我们使用被称为 “词嵌入 word embedding” 算法的方法类。这些算法将单词转化为向量空间,其中包含单词的许多含义/语义信息(例如:king - man + woman = queen)。
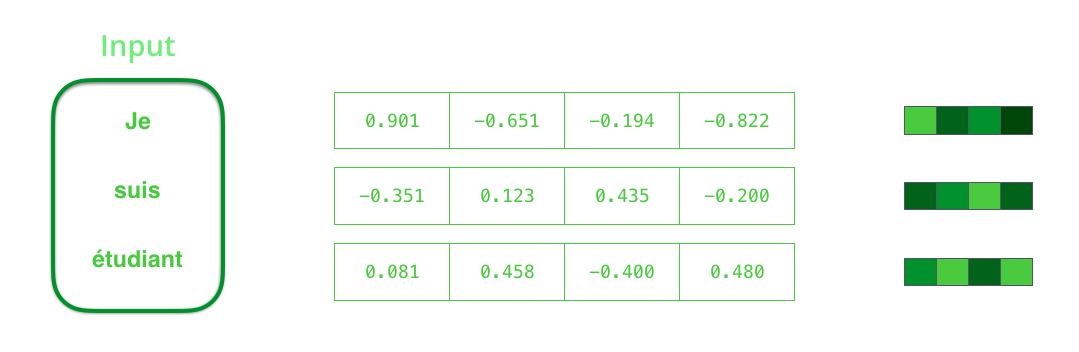 在处理输入之前,我们需要将输入单词转换为向量。这个过程使用 word embedding 算法完成。我们可以使用预训练的嵌入 pre-trained embeddings 或在我们自己的数据集上训练自己的嵌入。典型的嵌入向量边长为 200 或 300,为了简单起见,我们在这里展示了一个大小为 4 的向量。
在处理输入之前,我们需要将输入单词转换为向量。这个过程使用 word embedding 算法完成。我们可以使用预训练的嵌入 pre-trained embeddings 或在我们自己的数据集上训练自己的嵌入。典型的嵌入向量边长为 200 或 300,为了简单起见,我们在这里展示了一个大小为 4 的向量。
现在我们已经介绍了我们的主要向量/张量,让我们回顾一下 RNN 的机制并建立一个可视化的语言来描述这些模型:
RNN 下一步会使用第二个输入向量和第一步的隐藏状态,创建第二个时间步骤的输出。
下一步是使用第二个输入向量和一个隐藏状态#1来创建该时间的输出。后文中,我们会使用类似这样的动画来描述神经机器翻译模型内部的向量。
在接下来的可视化中,每个编码器 encoder 或解码器 decoder 的脉冲都是 RNN 处理其输入并生成该时间步的输出。由于编码器 encoder 和解码器 decoder 都是 RNN,每个时间步骤中一个 RNN 进行一些处理,它根据它的输入和之前步骤中它能看到的输入来更新其隐藏状态 hidden state。
让我们观察编码器 encoder 的隐藏状态 hidden states。请注意,实际上最后一个隐藏状态 hidden state 我们作为上下文 context传递给了解码器 decoder。
在解码器 decoder 中,也会维护一个从一个时间步骤传递到下一个时间步骤的隐藏状态 hidden state。但我们目前关注的是模型的主要部分,所以没有在可视化中展示它。
现在让我们来看看另一种可视化序列到序列模型的方式。这个动画将更容易理解描述这些模型的静态图形。这被称为“展开”视图,在这个视图中,我们不只显示一个解码器 decoder,而是为每个时间步骤显示一个副本。这样我们就可以查看每个时间步骤的输入和输出。
让我们集中注意力
对于这类模型来说,上下文 context 向量成为了一个瓶颈。它使得模型难以处理较长的句子。Bahdanau et al., 2014 和 Luong et al., 2015 提出了一个解决方案。这些论文引入并改进了一种被称为“注意力”的技术,极大地提高了机器翻译系统的质量。注意力允许模型根据需要专注于输入序列的相关部分。
让我们继续在这个高层抽象层面上查看注意力模型。注意力模型与经典的序列到序列模型有两个主要区别:
首先,编码器 encoder 将更多的数据传递给解码器 decoder。编码器 encoder 不再只传递编码阶段的最后隐藏状态,而是将 所有 隐藏状态 hidden states 都传递给解码器 decoder:
其次,在生成输出之前,有注意力机制的解码器 decoder 会执行一个额外的步骤。为了聚焦于与当前解码时间步骤相关的输入部分,解码器 decoder 会执行以下操作:
- 浏览它收到的编码器隐藏状态 hidden states 集合 - 每个编码器隐藏状态 encoder hidden state 与输入句子中最相关的某个单词关联
- 给每个隐藏状态 hidden state 赋予一个分数(我们先不考虑分数的计算方式)
- 将每个隐藏状态 hidden state 乘以其经过 softmax 处理后的分数,从而放大具有高分数的隐藏状态 hidden states,并淹没具有低分数的隐藏状态 hidden states
这个评分过程在解码器 decoder 端的每个时间步骤中进行。
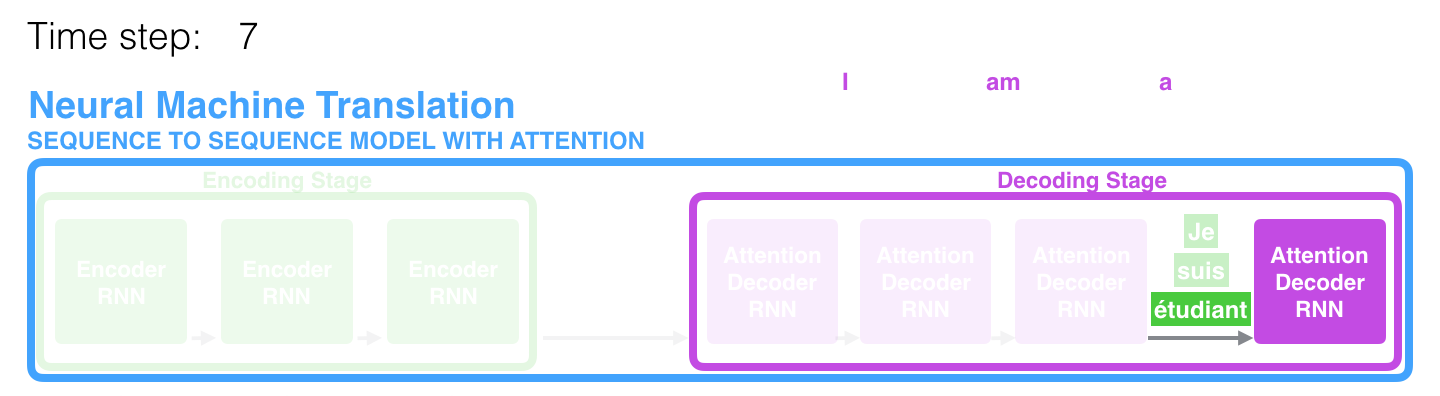
现在让我们将所有内容整合到以下可视化中,看看注意力过程是如何工作的:
- 注意力解码器 RNN 接收 符号的嵌入向量,和一个初始解码器隐藏状态 initial decoder hidden state。
- RNN 处理输入,生成一个输出和一个新的隐藏状态 new hidden state 向量(h4)。输出被丢弃。
- 注意力步骤:我们使用编码器隐藏状态 encoder hidden states 和 h4 向量来计算该时间步骤的上下文向量(C4)。
- 我们将 h4 和 C4 连接成一个向量。
- 我们通过一个前馈神经网络 feedforward neural network(与模型一起训练的网络)传递这个向量。
- 前馈神经网络的输出 output 指示了该时间步骤的输出单词。
- 下一个时间步骤重复以上步骤。
这是另一种观察我们在每个解码步骤上关注输入句子的哪个部分的方式:
请注意,模型并不是简单地将输出的第一个单词与输入的第一个单词对齐。它实际上是在训练阶段学习了如何对齐该语言对(例如上例中的法语和英语)。可以从上面列出的注意力论文中看到这种机制有多么精确的例子:
 您可以看到,当输出“European Economic Area”时,模型正确地进行了注意力对齐。在法语中,这些单词的顺序与英语相反(“européenne économique zone”)。句子中的其他单词也以类似的顺序排列。
您可以看到,当输出“European Economic Area”时,模型正确地进行了注意力对齐。在法语中,这些单词的顺序与英语相反(“européenne économique zone”)。句子中的其他单词也以类似的顺序排列。
如果您觉得已经准备好学习实现的内容,请务必查看 TensorFlow 的 Neural Machine Translation (seq2seq) Tutorial。
