HumanEval 是 OpenAI 用来评估大语言模型生成代码能力的工具,包括手写的 164 个 python 编程问题及解答的 jsonl 格式数据,以及执行评估的脚本。
数据集
先来看下数据集,下面是 HumanEval.jsonl.gz 中的一条数据:
{
"task_id": "HumanEval/0",
"prompt": "from typing import List\n\n\ndef has_close_elements(numbers: List[float], threshold: float) -> bool:\n \"\"\" Check if in given list of numbers, are any two numbers closer to each other than\n given threshold.\n >>> has_close_elements([1.0, 2.0, 3.0], 0.5)\n False\n >>> has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3)\n True\n \"\"\"\n",
"entry_point": "has_close_elements",
"canonical_solution": " for idx, elem in enumerate(numbers):\n for idx2, elem2 in enumerate(numbers):\n if idx != idx2:\n distance = abs(elem - elem2)\n if distance < threshold:\n return True\n\n return False\n",
"test": "\n\nMETADATA = {\n 'author': 'jt',\n 'dataset': 'test'\n}\n\n\ndef check(candidate):\n assert candidate([1.0, 2.0, 3.9, 4.0, 5.0, 2.2], 0.3) == True\n assert candidate([1.0, 2.0, 3.9, 4.0, 5.0, 2.2], 0.05) == False\n assert candidate([1.0, 2.0, 5.9, 4.0, 5.0], 0.95) == True\n assert candidate([1.0, 2.0, 5.9, 4.0, 5.0], 0.8) == False\n assert candidate([1.0, 2.0, 3.0, 4.0, 5.0, 2.0], 0.1) == True\n assert candidate([1.1, 2.2, 3.1, 4.1, 5.1], 1.0) == True\n assert candidate([1.1, 2.2, 3.1, 4.1, 5.1], 0.5) == False\n\n"
}数据结构为:
{
"task_id": "问题编号",
"prompt": "提示词",
"entry_point": "入口函数",
"canonical_solution": "手写答案",
"test": "测试用例"
}prompt:
from typing import List
def has_close_elements(numbers: List[float], threshold: float) -> bool:
""" Check if in given list of numbers, are any two numbers closer to each other than
given threshold.
>>> has_close_elements([1.0, 2.0, 3.0], 0.5)
False
>>> has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3)
True
"""canonical_solution:
for idx, elem in enumerate(numbers):
for idx2, elem2 in enumerate(numbers):
if idx != idx2:
distance = abs(elem - elem2)
if distance < threshold:
return True
return Falsetest:
METADATA = {
'author': 'jt',
'dataset': 'test'
}
def check(candidate):
assert candidate([1.0, 2.0, 3.9, 4.0, 5.0, 2.2], 0.3) == True
assert candidate([1.0, 2.0, 3.9, 4.0, 5.0, 2.2], 0.05) == False
assert candidate([1.0, 2.0, 5.9, 4.0, 5.0], 0.95) == True
assert candidate([1.0, 2.0, 5.9, 4.0, 5.0], 0.8) == False
assert candidate([1.0, 2.0, 3.0, 4.0, 5.0, 2.0], 0.1) == True
assert candidate([1.1, 2.2, 3.1, 4.1, 5.1], 1.0) == True
assert candidate([1.1, 2.2, 3.1, 4.1, 5.1], 0.5) == False评估方式
将每条数据的 prompt 输入给大模型,拼接上大模型生成的代码,作为被 test 测试的 candidate 方法,执行测试用例记录测试结果是否通过。
需要准备一份 jsonl 格式的用来评估的样本文件,格式如下:
{"task_id": "Corresponding HumanEval task ID", "completion": "Completion only without the prompt"}
{"task_id": "Corresponding HumanEval task ID", "completion": "Completion only without the prompt"}
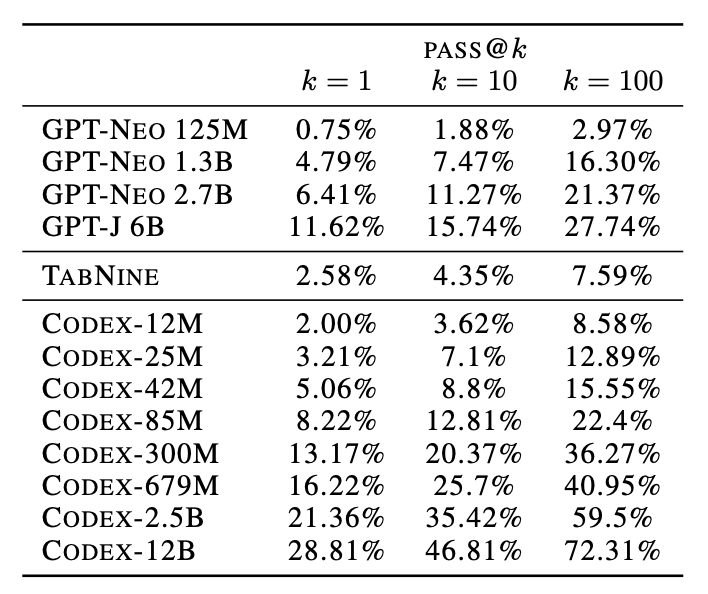
...可以为同一个 task_id 生成多个待评估样本,假设样本数量为 k,其中有一个样本的测试用例能通过即被认为此 task_id 的状态是通过的,也就是通常使用 HumanEval 的评估结果标记为 pass@k 中 k 的含义,执行评估后会得到被评估样本通过所有评估问题的概率,如 Evaluating Large Language Models Trained on Code 论文中给出的数据:
生成样本
下面给出一段生成样本文件的示例代码:调用通过 FastChat 为大语言模型代理的 Create completion 接口,为每个 task 生成 num_samples_per_task 个样本,生成样本文件为 samples.jsonl。
import time
from datetime import datetime
import json
import requests
from human_eval.data import write_jsonl, read_problems
problems = read_problems()
def generate_one_completion(task_id, prompt):
print(datetime.now().strftime("%H:%M:%S"), task_id)
url = 'http://localhost:9000/v1/completions'
headers = {'Content-Type': 'application/json', 'Connection': 'close'}
data = {
"model": "starcoder",
"prompt": prompt,
"max_tokens": 1000,
"temperature": 0.2
}
try:
response = requests.post(url, headers=headers, json=data)
result = json.loads(response.text)["choices"][0]["text"]
print(result)
return result
except:
print(f"Exception occurs, wait 3 seconds then retry...")
time.sleep(3)
generate_one_completion(task_id, prompt)
num_samples_per_task = 1
for task_id in problems:
for _ in range(num_samples_per_task):
samples = [
dict(task_id=task_id, completion=generate_one_completion(task_id, problems[task_id]["prompt"]))
]
write_jsonl("samples.jsonl", samples, True)执行评估
pip install 过 human-eval 后,可直接使用 evaluate_functional_correctness samples.jsonl 命令对样本文件进行评估,或通过 python evaluate_functional_correctness.py samples.jsonl 执行评估:
$ evaluate_functional_correctness samples.jsonl
Reading samples...
32800it [00:01, 23787.50it/s]
Running test suites...
100%|...| 32800/32800 [16:11<00:00, 33.76it/s]
Writing results to samples.jsonl_results.jsonl...
100%|...| 32800/32800 [00:00<00:00, 42876.84it/s]
{'pass@1': ..., 'pass@10': ..., 'pass@100': ...}留言
