HumanEval-X 是 清华大学 KEG 实验室 THUDM 在 CodeGeeX 系列多语言代码生成模型中提供的一套评价标准。
使用了与 HumanEval 相似的评价方式,不同的是,除 Python 外还包含了 C++、Java、JavaScript、Go 及 Rust 语言的手写样本,可对上述语言的代码生成能力进行评价:
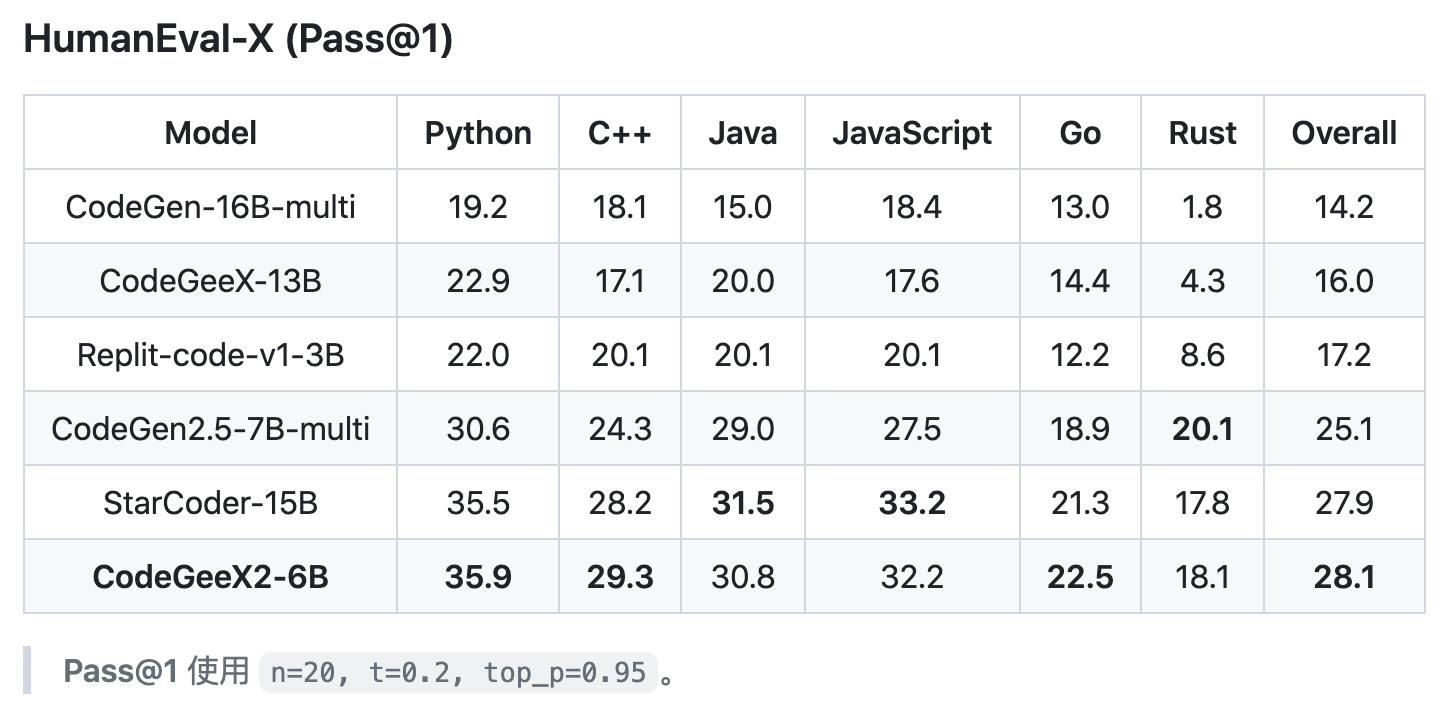
接下来,我们以评估 StarCoderBase-7B 模型的 Java 代码生成能力为例,简单介绍一下 HumanEval-X 的用法。
数据集
先来看下数据集,引用 如何使用HumanEval-X 对样本数据集的描述:
样本使用JSON列表格式存储在
codegeex/benchmark/humaneval-x/[LANG]/data/humaneval_[LANG].jsonl.gz,每条样本包含6个部分:
task_id: 题目的目标语言与ID。语言为[“Python”, “Java”, “JavaScript”, “CPP”, “Go”]中之一。prompt: 函数声明与描述,用于代码生成。declaration: 仅有函数声明,用于代码翻译。canonical_solution: 手写的示例解答。test: 隐藏测例,用于评测。example_test: 提示中出现的公开测例,用于评测。
下面是 humaneval_java.jsonl.gz 中的一条数据(总计包含 164 条样本数据):
{
"task_id": "Java/0",
"prompt": "import java.util.*;\nimport java.lang.*;\n\nclass Solution {\n /**\n Check if in given list of numbers, are any two numbers closer to each other than given threshold.\n >>> hasCloseElements(Arrays.asList(1.0, 2.0, 3.0), 0.5)\n false\n >>> hasCloseElements(Arrays.asList(1.0, 2.8, 3.0, 4.0, 5.0, 2.0), 0.3)\n true\n */\n public boolean hasCloseElements(List<Double> numbers, double threshold) {\n",
"declaration": "import java.util.*;\nimport java.lang.*;\n\nclass Solution {\n public boolean hasCloseElements(List<Double> numbers, double threshold) {\n",
"canonical_solution": " for (int i = 0; i < numbers.size(); i++) {\n for (int j = i + 1; j < numbers.size(); j++) {\n double distance = Math.abs(numbers.get(i) - numbers.get(j));\n if (distance < threshold) return true;\n }\n }\n return false;\n }\n}",
"test": "public class Main {\n public static void main(String[] args) {\n Solution s = new Solution();\n List<Boolean> correct = Arrays.asList(\n s.hasCloseElements(new ArrayList<>(Arrays.asList(11.0, 2.0, 3.9, 4.0, 5.0, 2.2)), 0.3),\n !s.hasCloseElements(new ArrayList<>(Arrays.asList(1.0, 2.0, 3.9, 4.0, 5.0, 2.2)), 0.05),\n s.hasCloseElements(new ArrayList<>(Arrays.asList(1.0, 2.0, 5.9, 4.0, 5.0)), 0.95),\n !s.hasCloseElements(new ArrayList<>(Arrays.asList(1.0, 2.0, 5.9, 4.0, 5.0)), 0.8),\n s.hasCloseElements(new ArrayList<>(Arrays.asList(1.0, 2.0, 3.0, 4.0, 5.0, 2.0)), 0.1),\n s.hasCloseElements(new ArrayList<>(Arrays.asList(1.1, 2.2, 3.1, 4.1, 5.1)), 1.0),\n !s.hasCloseElements(new ArrayList<>(Arrays.asList(1.1, 2.2, 3.1, 4.1, 5.1)), 0.5)\n );\n if (correct.contains(false)) {\n throw new AssertionError();\n }\n }\n}",
"example_test": "public class Main {\n public static void main(String[] args) {\n Solution s = new Solution();\n List<Boolean> correct = Arrays.asList(\n !s.hasCloseElements(new ArrayList<>(Arrays.asList(1.0, 2.0, 3.0)), 0.5),\n s.hasCloseElements(new ArrayList<>(Arrays.asList(1.0, 2.8, 3.0, 4.0, 5.0, 2.0)), 0.3)\n );\n if (correct.contains(false)) {\n throw new AssertionError();\n }\n }\n}\n",
"text": " Check if in given list of numbers, are any two numbers closer to each other than given threshold.\n >>> hasCloseElements(Arrays.asList(1.0, 2.0, 3.0), 0.5)\n false\n >>> hasCloseElements(Arrays.asList(1.0, 2.8, 3.0, 4.0, 5.0, 2.0), 0.3)\n true"
}输入给大模型的提示词 prompt 为:
import java.util.*;
import java.lang.*;
class Solution {
/**
Check if in given list of numbers, are any two numbers closer to each other than given threshold.
>>> hasCloseElements(Arrays.asList(1.0, 2.0, 3.0), 0.5)
false
>>> hasCloseElements(Arrays.asList(1.0, 2.8, 3.0, 4.0, 5.0, 2.0), 0.3)
true
*/
public boolean hasCloseElements(List<Double> numbers, double threshold) {手写的示例解答 canonical_solution 为:
for (int i = 0; i < numbers.size(); i++) {
for (int j = i + 1; j < numbers.size(); j++) {
double distance = Math.abs(numbers.get(i) - numbers.get(j));
if (distance < threshold) return true;
}
}
return false;
}
}用于评测的测试用例 test 为:
public class Main {
public static void main(String[] args) {
Solution s = new Solution();
List<Boolean> correct = Arrays.asList(
s.hasCloseElements(new ArrayList<>(Arrays.asList(11.0, 2.0, 3.9, 4.0, 5.0, 2.2)), 0.3),
!s.hasCloseElements(new ArrayList<>(Arrays.asList(1.0, 2.0, 3.9, 4.0, 5.0, 2.2)), 0.05),
s.hasCloseElements(new ArrayList<>(Arrays.asList(1.0, 2.0, 5.9, 4.0, 5.0)), 0.95),
!s.hasCloseElements(new ArrayList<>(Arrays.asList(1.0, 2.0, 5.9, 4.0, 5.0)), 0.8),
s.hasCloseElements(new ArrayList<>(Arrays.asList(1.0, 2.0, 3.0, 4.0, 5.0, 2.0)), 0.1),
s.hasCloseElements(new ArrayList<>(Arrays.asList(1.1, 2.2, 3.1, 4.1, 5.1)), 1.0),
!s.hasCloseElements(new ArrayList<>(Arrays.asList(1.1, 2.2, 3.1, 4.1, 5.1)), 0.5)
);
if (correct.contains(false)) {
throw new AssertionError();
}
}
}评估方式
将每条数据的 prompt 输入给大模型,拼接上大模型生成的代码,作为被 test 中测试代码使用的 Solution 类,执行测试用例记录测试结果是否通过。
需要准备一份 jsonl 格式的用来评估生成的代码的样本文件,格式可基于原始数据格式,在每行数据的 JSON 对象中添加一个 generation 属性,如:
{"task_id": "../..", "prompt": "../..", "declaration": "../..", "canonical_solution": "../..", "test": "../..", "example_test": "../..", "generation: "..."}
{"task_id": "../..", "prompt": "../..", "declaration": "../..", "canonical_solution": "../..", "test": "../..", "example_test": "../..", "generation: "..."}
...注:按 评测 文档中给出的格式例子,每条数据仅包含
task_id和generation两个属性,执行评估时可能会报错。
HumanEval-X 的评估结果形式与 HumanEval 一致,是以 pass@k 表示的一个百分比概率。其中 k 通常使用的值为 100、101、102。
使用 pass@k 指标时,可以为每个问题(task_id)生成 k 个待评估样本,当有任何一个样本通过测试时,则认为问题已解决,并报告解决问题的总比例。
然而,以这种方式计算 pass@k 可能会有很高的方差,这意味着每次得到的结果可能会有很大的差异。取而代之的,在 Evaluating Large Language Models Trained on Code 论文中使用的计算 pass@k 的方法为:
为每个问题生成 n 个样本(n ≥ k),计算通过单元测试的正确样本数 c(c ≤ n),每个问题按如下方式计算该问题的 pass@k,之后将所有问题 pass@k 的平均值作为最终评估结果。
def pass_at_k(n, c, k):
"""
:param n: total number of samples
:param c: number of correct samples
:param k: k in pass@$k$
"""
if n - c < k: return 1.0
return 1.0 - np.prod(1.0 - k / np.arange(n - c + 1, n + 1))HumanEval 及 HumanEval-X 使用的都是这个算法:
pass_at_k = {f"pass@{k}": estimate_pass_at_k(total, correct, k).mean()
for k in ks if (total >= k).all()}def estimate_pass_at_k(
num_samples: Union[int, List[int], np.ndarray],
num_correct: Union[List[int], np.ndarray],
k: int
) -> np.ndarray:
"""
Estimates pass@k of each problem and returns them in an array.
"""
def estimator(n: int, c: int, k: int) -> float:
"""
Calculates 1 - comb(n - c, k) / comb(n, k).
"""
if n - c < k:
return 1.0
return 1.0 - np.prod(1.0 - k / np.arange(n - c + 1, n + 1))
if isinstance(num_samples, int):
num_samples_it = itertools.repeat(num_samples, len(num_correct))
else:
assert len(num_samples) == len(num_correct)
num_samples_it = iter(num_samples)
return np.array([estimator(int(n), int(c), k) for n, c in zip(num_samples_it, num_correct)])生成样本
下面给出一段生成样本文件的示例代码 gen_samples.py:调用通过 FastChat 为大语言模型代理的 Create completion 接口,为每个 task 生成 num_samples_per_task 个样本,生成样本文件为 samples.jsonl。
import time
from datetime import datetime
import json
import requests
from human_eval.data import write_jsonl, read_problems
problems = read_problems('/workspace/CodeGeeX/codegeex/benchmark/humaneval-x/java/data/humaneval_java.jsonl.gz')
def generate_one_completion(task_id, prompt):
print(datetime.now().strftime("%H:%M:%S"), task_id)
url = 'http://localhost:9000/v1/completions'
headers = {'Content-Type': 'application/json', 'Connection': 'close'}
data = {
"model": "starcoder",
"prompt": prompt,
"max_tokens": 1000,
"temperature": 0.2
}
try:
response = requests.post(url, headers=headers, json=data)
result = json.loads(response.text)["choices"][0]["text"]
print(result)
return result
except:
print(f"Exception occurs, wait 3 seconds then retry...")
time.sleep(3)
generate_one_completion(task_id, prompt)
num_samples_per_task = 1
for task_id in problems:
for _ in range(num_samples_per_task):
samples = [
dict(
task_id=task_id,
generation=generate_one_completion(task_id, problems[task_id]["prompt"]),
canonical_solution=problems[task_id]["canonical_solution"],
declaration=problems[task_id]["declaration"],
example_test=problems[task_id]["example_test"],
prompt=problems[task_id]["prompt"],
test=problems[task_id]["test"],
text=problems[task_id]["text"]
)
]
write_jsonl("samples.jsonl", samples, True)评估环境
执行评估涉及到多种语言的编译和运行,HumanEval-X 使用的 评估环境 依赖及版本如下:
| Dependency | Version |
|---|---|
| Python | 3.8.12 |
| JDK | 18.0.2.1 |
| Node.js | 16.14.0 |
| js-md5 | 0.7.3 |
| C++ | 11 |
| g++ | 7.5.0 |
| Boost | 1.71.0 |
| OpenSSL | 3.0.0 |
| go | 1.18.4 |
可直接使用官方提供的 Docker 镜像作为评估环境:
# 拉取镜像
$ docker pull rishubi/codegeex:latest
# 启动并进入容器,挂载生成样本脚本 gen_samples.py 至容器内 /work/data 路径下
$ docker run -ti --rm -v /path/to/gen_samples.py:/work/data/gen_samples.py rishubi/codegeex bashlatest 镜像的构建时间是 2022年9月20日,进入容器后,先更新一下容器中的 CodeGeeX 仓库代码:
$ cd /workspace/CodeGeeX
$ git pull origin main参照下面 diff 内容去掉 /workspace/CodeGeeX/codegeex/benchmark/execution.py 文件中的注释内容:
diff --git a/codegeex/benchmark/execution.py b/codegeex/benchmark/execution.py
index cbdf14f..604eeec 100644
--- a/codegeex/benchmark/execution.py
+++ b/codegeex/benchmark/execution.py
@@ -122,7 +122,7 @@ def check_correctness(
# does not perform destructive actions on their host or network.
# Once you have read this disclaimer and taken appropriate precautions,
# uncomment the following line and proceed at your own risk:
- exec_result = subprocess.run(["go", "test", f"-timeout={timeout}s", "main_test.go"], timeout=timeout, capture_output=True)
+ exec_result = subprocess.run(["go", "test", f"-timeout={timeout}s", "main_test.go"], timeout=timeout, capture_output=True)
if exec_result.returncode == 0:
result.append("passed")
@@ -167,7 +167,7 @@ def check_correctness(
# does not perform destructive actions on their host or network.
# Once you have read this disclaimer and taken appropriate precautions,
# uncomment the following line and proceed at your own risk:
- exec_result = subprocess.run(["node", "test.js"], timeout=timeout, capture_output=True)
+ exec_result = subprocess.run(["node", "test.js"], timeout=timeout, capture_output=True)
if exec_result.stderr.decode():
err = exec_result.stderr.decode()
@@ -220,7 +220,7 @@ def check_correctness(
# does not perform destructive actions on their host or network.
# Once you have read this disclaimer and taken appropriate precautions,
# uncomment the following line and proceed at your own risk:
- exec_result = subprocess.run(["./a.out"], timeout=timeout, capture_output=True)
+ exec_result = subprocess.run(["./a.out"], timeout=timeout, capture_output=True)
if exec_result.returncode == 0:
result.append("passed")
@@ -344,7 +344,7 @@ def check_correctness(
# does not perform destructive actions on their host or network.
# Once you have read this disclaimer and taken appropriate precautions,
# uncomment the following line and proceed at your own risk:
- # exec_result = subprocess.run([f'java', '-cp', tmp_dir, 'Main'], timeout=timeout, capture_output=True)
+ exec_result = subprocess.run([f'java', '-cp', tmp_dir, 'Main'], timeout=timeout, capture_output=True)
if exec_result.returncode == 0:
res = "passed"
elif exec_result.returncode == 1:使用 gen_samples.py 脚本生成评估数据
# 工作目录 /work/data
$ cd /work/data
# 安装依赖
$ pip install human-eval
# 生成评估数据,可调整 gen_samples.py 中参数
$ python gen_samples.py执行评估
$ cd /workspace/CodeGeeX/
$ bash scripts/evaluate_humaneval_x.sh /work/data/samples.jsonl java
/work/data/samples.jsonl
python /workspace/CodeGeeX/codegeex/benchmark/humaneval-x/evaluate_humaneval_x.py --input_file /work/data/samples.jsonl --n_workers 64 --tmp_dir /workspace/CodeGeeX/codegeex/benchmark/humaneval-x/ --problem_file /workspace/CodeGeeX/codegeex/benchmark/humaneval-x/java/data/humaneval_java.jsonl.gz --timeout 5
Reading samples...
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 164/164 [00:00<00:00, 240.52it/s]
Counter({'Java/0': 1, 'Java/1': 1, 'Java/2': 1, 'Java/3': 1, 'Java/4': 1, 'Java/5': 1, 'Java/6': 1, 'Java/7': 1, 'Java/8': 1, 'Java/9': 1, 'Java/10': 1, 'Java/11': 1, 'Java/12': 1, 'Java/13': 1, 'Java/14': 1, 'Java/15': 1, 'Java/16': 1, 'Java/17': 1, 'Java/18': 1, 'Java/19': 1, 'Java/20': 1, 'Java/21': 1, 'Java/22': 1, 'Java/23': 1, 'Java/24': 1, 'Java/25': 1, 'Java/26': 1, 'Java/27': 1, 'Java/28': 1, 'Java/29': 1, 'Java/30': 1, 'Java/31': 1, 'Java/32': 1, 'Java/33': 1, 'Java/34': 1, 'Java/35': 1, 'Java/36': 1, 'Java/37': 1, 'Java/38': 1, 'Java/39': 1, 'Java/40': 1, 'Java/41': 1, 'Java/42': 1, 'Java/43': 1, 'Java/44': 1, 'Java/45': 1, 'Java/46': 1, 'Java/47': 1, 'Java/48': 1, 'Java/49': 1, 'Java/50': 1, 'Java/51': 1, 'Java/52': 1, 'Java/53': 1, 'Java/54': 1, 'Java/55': 1, 'Java/56': 1, 'Java/57': 1, 'Java/58': 1, 'Java/59': 1, 'Java/60': 1, 'Java/61': 1, 'Java/62': 1, 'Java/63': 1, 'Java/64': 1, 'Java/65': 1, 'Java/66': 1, 'Java/67': 1, 'Java/68': 1, 'Java/69': 1, 'Java/70': 1, 'Java/71': 1, 'Java/72': 1, 'Java/73': 1, 'Java/74': 1, 'Java/75': 1, 'Java/76': 1, 'Java/77': 1, 'Java/78': 1, 'Java/79': 1, 'Java/80': 1, 'Java/81': 1, 'Java/82': 1, 'Java/83': 1, 'Java/84': 1, 'Java/85': 1, 'Java/86': 1, 'Java/87': 1, 'Java/88': 1, 'Java/89': 1, 'Java/90': 1, 'Java/91': 1, 'Java/92': 1, 'Java/93': 1, 'Java/94': 1, 'Java/95': 1, 'Java/96': 1, 'Java/97': 1, 'Java/98': 1, 'Java/99': 1, 'Java/100': 1, 'Java/101': 1, 'Java/102': 1, 'Java/103': 1, 'Java/104': 1, 'Java/105': 1, 'Java/106': 1, 'Java/107': 1, 'Java/108': 1, 'Java/109': 1, 'Java/110': 1, 'Java/111': 1, 'Java/112': 1, 'Java/113': 1, 'Java/114': 1, 'Java/115': 1, 'Java/116': 1, 'Java/117': 1, 'Java/118': 1, 'Java/119': 1, 'Java/120': 1, 'Java/121': 1, 'Java/122': 1, 'Java/123': 1, 'Java/124': 1, 'Java/125': 1, 'Java/126': 1, 'Java/127': 1, 'Java/128': 1, 'Java/129': 1, 'Java/130': 1, 'Java/131': 1, 'Java/132': 1, 'Java/133': 1, 'Java/134': 1, 'Java/135': 1, 'Java/136': 1, 'Java/137': 1, 'Java/138': 1, 'Java/139': 1, 'Java/140': 1, 'Java/141': 1, 'Java/142': 1, 'Java/143': 1, 'Java/144': 1, 'Java/145': 1, 'Java/146': 1, 'Java/147': 1, 'Java/148': 1, 'Java/149': 1, 'Java/150': 1, 'Java/151': 1, 'Java/152': 1, 'Java/153': 1, 'Java/154': 1, 'Java/155': 1, 'Java/156': 1, 'Java/157': 1, 'Java/158': 1, 'Java/159': 1, 'Java/160': 1, 'Java/161': 1, 'Java/162': 1, 'Java/163': 1})
Running test suites...
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 164/164 [00:07<00:00, 22.01it/s]
{'pass@1': 0.21341463414634146}
Writing to: /work/data/samples_results.jsonl
Evaluation finished.得到评估结果为:
| Model | HumanEval-X Java |
|---|---|
| StarCoderBase-7B | 0.21341463414634146 |
Sampling temperature=0.2, n=1, top_p=1.0 for pass@1
在评估输出文件(本例中为 /work/data/samples_results.jsonl)中可以通过 passed 属性查看每个样本的测试结果,result 属性查看具体信息。
pass
{
"task_id": "Java/9",
"completion_id": 0,
"test_code": "...",
"prompt": "...",
"generation": "\tList<Integer> result = new ArrayList<Integer>();\n\tint max = 0;\n\tfor (int i = 0; i < numbers.size(); i++) {\n\t if (numbers.get(i) > max) {\n\t\tmax = numbers.get(i);\n\t }\n\t result.add(max);\n\t}\n\treturn result;\n }\n}\n",
"result": "passed",
"passed": true,
"finish": -1,
"file": "",
"output": []
}failed
{
"task_id": "Java/6",
"completion_id": 0,
"test_code": "...",
"prompt": "...",
"generation": "\tList<Integer> result = new ArrayList<>();\n\tStack<Integer> stack = new Stack<>();\n\tfor (char c : paren_string.toCharArray()) {\n\t if (c == '(') {\n\t\tstack.push(0);\n\t } else {\n\t\tif (stack.empty()) {\n\t\t result.add(-1);\n\t\t} else {\n\t\t result.add(stack.pop() + 1);\n\t\t}\n\t }\n\t}\n\treturn result;\n }\n}\n",
"result": "failed: wrong answer",
"passed": false,
"finish": -1,
"file": "",
"output": []
}