Start at: 2020-01-05
End at: 2020-03-28
Process: 298/298
3 Netty components and design
3.1 Channel, EventLoop, and ChannelFuture
3.1.2 Interface EventLoop
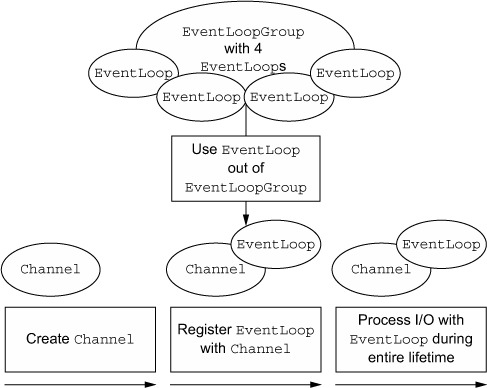
- An
EventLoopGroupcontains one or moreEventLoops. - An
EventLoopis bound to a singleThreadfor its lifetime. - All I/O events processed by an
EventLoopare handled on its dedicatedThread. - A
Channelis registered for its lifetime with a singleEventLoop. - A single
EventLoopmay be assigned to one or moreChannels.
4 Transports
4.3 Included transports
4.3.1 NIO —— non-blocking I/O
- Zero-copy is a feature currently available only with NIO and Epoll transport. It allows you to quickly and efficiently move data from a file system to the network without copying from kernel space to user space, which can significantly improve performance in protocols such as FTP or HTTP. This feature is not supported by all OSes. Specifically it is not usable with file systems that implement data encryption or compression—only the raw content of a file can be transferred. Conversely, transferring files that have already been encrypted isn’t a problem.
5 ByteBuf
5.2 Class ByteBuf—Netty’s data container
5.2.2 ByteBuf usage patterns
- If ByteBuf isn’t backed by an array. If not, this is a direct buffer.
- The ByteBuf instances in a CompositeByteBuf may include both direct and nondirect allocations. If there is only one instance, calling has- Array() on a CompositeByteBuf will return the hasArray() value of that component; otherwise it will return false.
5.3 Byte-level operations
5.3.2 Sequential access indexing
- While ByteBuf has both reader and writer indices, the JDK’s ByteBuffer has only one, which is why you have to call flip() to switch between read and write modes.
5.3.8 Derived buffers
duplicate(),slice(),slice(int, int),Unpooled.unmodifiableBuffer(...),order(ByteOrder),readSlice(int), each returns a newByteBufinstance with its own reader, writer, and marker indices. The internal storage is shared just as in a JDKByteBuffer. This makes a derived buffer inexpensive to create, but it also means that if you modify its contents you are modifying the source instance as well, so beware.- If you need a true copy of an existing buffer, use
copy()orcopy(int,int). Unlike a derived buffer, theByteBufreturned by this call has an independent copy of the data.
6 ChannelHandler and ChannelPipeline
6.1 The ChannelHandler family
6.1.3 Interface ChannelInboundHandler
- When a ChannelInboundHandler implementation overrides channelRead(), it is responsible for explicitly releasing the memory associated with pooled ByteBuf instances. Netty provides a utility method for this purpose, ReferenceCountUtil.relese()
- A simpler alternative is to use SimpleChannelInboundHandler. … Because SimpleChannelInboundHandler releases resources automatically, you shouldn’t store references to any messages for later use, as these will become invalid.
6.1.4 Interface ChannelOutboundHandler
- ChannelPromise vs. ChannelFuture: ChannelPromise is a subinterface of ChannelFuture that defines the writable methods, … thus making ChannelFuture immutable.
6.1.6 Resource management
- On the outbound side, if you handle a write() operation and discard a message, you’re responsible for releasing it.
- It’s important not only to release resources but also to notify the ChannelPromise. Otherwise a situation might arise where a ChannelFutureListener has not been notified about a message that has been handled.
- In sum, it is the responsibility of the user to call ReferenceCountUtil.release() if a message is consumed or discarded and not passed to the next ChannelOutboundHandler in the ChannelPipeline. If the message reaches the actual transport layer, it will be released automatically when it’s written or the Channel is closed.
6.2 Interface ChannelPipeline
- Every new Channel that’s created is assigned a new ChannelPipeline. This association is permanent; the Channel can neither attach another ChannelPipeline nor detach the current one. This is a fixed operation in Netty’s component lifecycle and requires no action on the part of the developer.
6.3 Interface ChannelHandlerContext
ChannelHandlerContexthas numerous methods, some of which are also present onChanneland onChannelPipelineitself, but there is an important difference. If you invoke these methods on aChannelorChannelPipelineinstance, they propagate through the entire pipeline. The same methods called on aChannelHandlerContextwill start at the current associatedChannelHandlerand propagate only to the nextChannelHandlerin the pipeline that is capable of handling the event.
7 EventLoop and threading model
7.3 Task scheduling
7.3.1 JDK scheduling API
- Although the
ScheduledExecutorServiceAPI is straightforward, under heavy load it can introduce performance costs. In the next section we’ll see how Netty provides the same functionality with greater efficiency.
7.3.2 Scheduling tasks using EventLoop
- The
ScheduledExecutorServiceimplementation has limitations, such as the fact that extra threads are created as part of pool management. This can become a bottleneck if many tasks are aggressively scheduled.
7.4 Implementation details
7.4.1 Thread management
- Note that each EvetnLoop has its own task queue, independent of that of any other EventLoop.
- Never put a long-running task in the execution queue, because it will block any other task from executing on the same thread.
- If you must make blocking calls or execute long-running tasks, we advise the use of a dedicated EventExecutor.
7.4.2 EventLoop/thread allocation
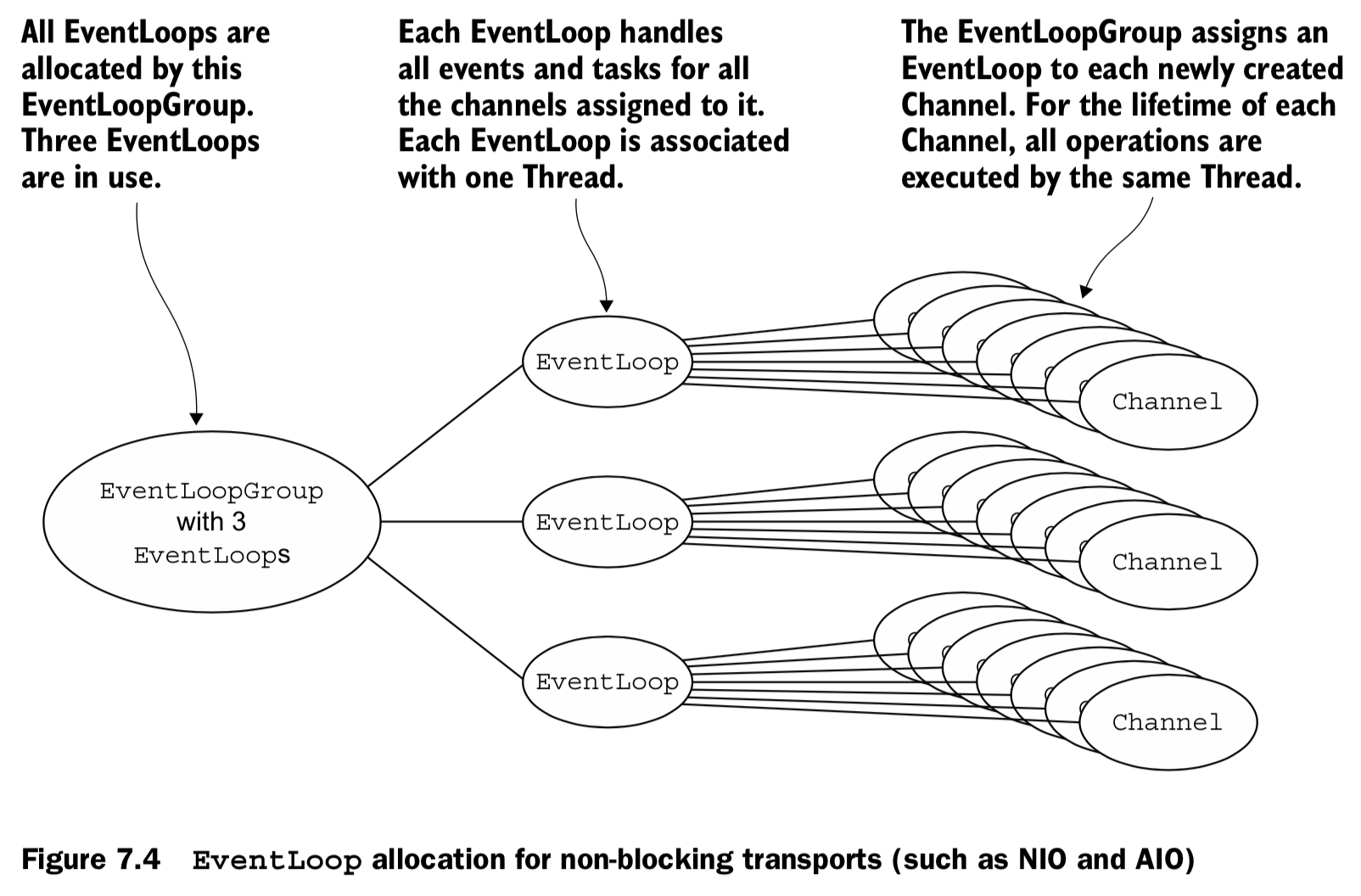
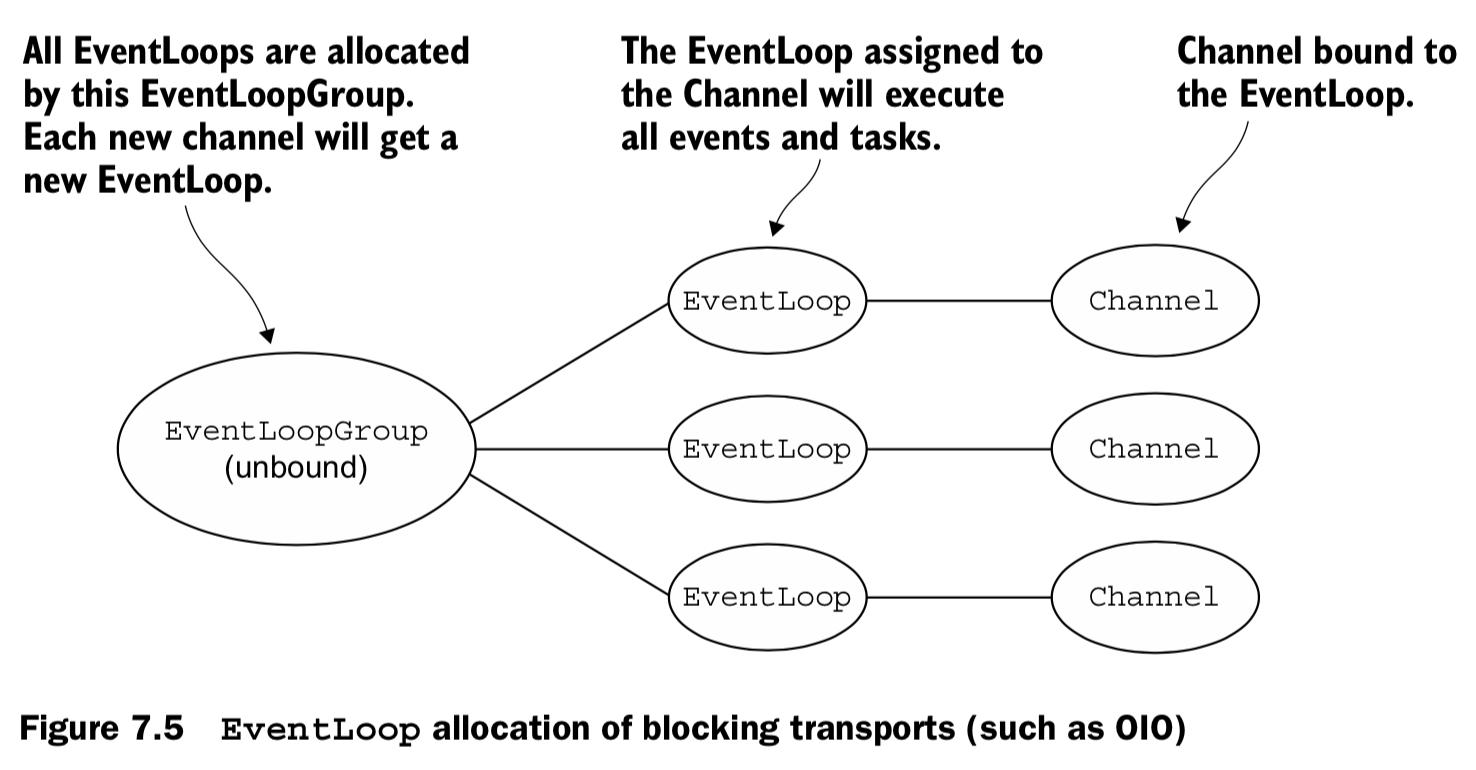
8 Bootstrapping
8.4 Bootstrapping clients from a Channel
- a general guideline in coding Netty applications: reuse EventLoops wherever possible to reduce the cost of thread creation.
9 Unit testing
Best practices dictate that you test not only to prove that your implementation is correct, but also to make it easy to isolate problems that crop up as code is modified. This type of testing is called unit testing.
The basic idea is to test your code in the smallest possible chunks, isolated as much as possible from other code modules and from runtime dependencies such as databases and networks. If you can verify through testing that each unit works correctly by itself, it will be much easier to find the culprit when something goes awry.
10 The codec framework
10.3 Encoders
10.3.1 Abstract class MessageToByteEncoder
- You may have noticed that this class has only one method, while decoders have two. The reason is that decoders often need to produce a last message after the
Channelhas closed (hence thedecodeLast()method). This is clearly not the case for an encoder—there is no sense in producing a message after the connection has been closed.
11 Provided ChannelHandlers and codecs
11.5 Writing big data
- In cases where you need to copy the data from the file system into user memory, you can use
ChunkedWriteHandler, which provides support for writing a large data stream asynchronously without incurring high memory consumption. - The key is
interface ChunkedInput<B>, where the parameterBis the type returned by the methodreadChunk(). Four implementations of this interface are provided, as listed in table 11.7. Each one represents a data stream of indefinite length to be consumed by aChunkedWriteHandler.
11.6 Serializing data
11.6.2 Serialization with JBoss Marshalling
- It’s up to three times faster than JDK Serialization and more compact. The overview on the JBoss Marshalling homepage defines it this way:
- JBoss Marshalling is an alternative serialization API that fixes many of the problems found in the JDK serialization API while remaining fully compatible with java.io.Serializable and its relatives, and adds several new tunable parameters and additional features, all of which are pluggable via factory configuration (externalizers, class/instance lookup tables, class resolution, and object replacement, to name a few).
14 Case studies, part 1
14.3 Urban Airship—building mobile services
14.3.5 Netty excels at managing large numbers of concurrent connections
- As mentioned in the previous section, Netty makes supporting asynchronous I/O on the JVM trivial. Because Netty operates on the JVM, and because the JVM on Linux ultimately uses the Linux epoll facility to manage interest in socket file descriptors, Netty makes it possible to accommodate the rapid growth of mobile by allowing developers to easily accept large numbers of open sockets—close to 1 million TCP connections per single Linux process. At numbers of this scale, service providers can keep costs low, allowing a large number of devices to connect to a single process on a physical server.
- Note the distinction of a physical server in this case. Although virtualization offers many benefits, leading cloud providers were regularly unable to accommodate more than 200,000–300,000 concurrent TCP connections to a single virtual host. With connections at or above this scale, expect to use bare metal servers and expect to pay close attention to the NIC (Network Interface Card) vendor.
Introduction to Maven
A2.2 POM Inheritance and aggregation
- The POM executed by Maven after all inherited information is assembled and all active profiles are applied is referred to as the “effective POM”. To see it, run the following Maven command in the same directory as any POM file:
mvn help:effective-pom
留言
