现象
一个线上的 Java 应用(JDK1.8,默认 Parallel GC)在运行几天之后,出现频繁 Full GC 的现象,使用 jstat -gcutil <pid> 2s 观察,状态大致如下:
$ jstat -gcutil 23426 2s
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 0.00 93.17 99.99 83.81 78.48 1814 90.687 45 261.660 352.347
0.00 0.00 97.30 99.99 83.81 78.48 1814 90.687 45 261.660 352.347
0.00 0.00 100.00 99.99 83.81 78.48 1814 90.687 46 261.660 352.347
0.00 0.00 100.00 99.99 83.81 78.48 1814 90.687 46 261.660 352.347
0.00 0.00 100.00 99.99 83.81 78.48 1814 90.687 46 261.660 352.347
0.00 0.00 100.00 99.99 83.81 78.48 1814 90.687 46 261.660 352.347
0.00 0.00 14.38 99.99 83.81 78.48 1814 90.687 46 269.050 359.737
0.00 0.00 22.19 99.99 83.81 78.48 1814 90.687 46 269.050 359.737在 Eden 区用满后,并不进行 Young GC(1814),而是直接触发 Full GC(45 => 46),导致 CPU 使用率上升,应用响应慢。
重启应用后,CPU 使用率恢复正常,老年代占用空间降低,新生代空间占满后,执行 Young GC,不引发 Full GC。
运行一段时间,老年代占用空间持续上升,Full GC 也不会有空间被回收,直至老年代空间占满,再次出现最初的情况。
工具
jps
JDK 中自带的 jps(Java Virtual Machine Process Status Tool) 命令,可以快速查询 Java 的进程标识(pid),如:
$ jps
7168 Jps
7114 hello.jar但有时可能会遇到类似下面的情况:
$ jps
12929 -- process information unavailable
31097 -- process information unavailable
12878 Jps某些 pid 后面并未显示出对应的 java 应用信息,原因是运行 java 应用的用户与执行 jps 命令的用户不一致,通过 su 等切换为相同的用户再执行 jps 命令即可。
jstat
获得 Java 应用的 pid 之后,可以使用 jstat(Java Virtual Machine statistics monitoring tool)对指定 Java 应用进行监控,以上面 pid 为 7114 的 Java 应用为例:
$ jstat -gcutil 7114 2s
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 0.00 6.11 7.94 92.59 90.24 6 0.028 2 0.068 0.096
0.00 0.00 6.11 7.94 92.59 90.24 6 0.028 2 0.068 0.096
0.00 0.00 6.11 7.94 92.59 90.24 6 0.028 2 0.068 0.096
0.00 0.00 6.11 7.94 92.59 90.24 6 0.028 2 0.068 0.096
0.00 0.00 6.11 7.94 92.59 90.24 6 0.028 2 0.068 0.096
0.00 0.00 6.11 7.94 92.59 90.24 6 0.028 2 0.068 0.096上面命令意为获得 pid 为 7114 的 Java 应用的垃圾收集统计信息,时间间隔 2 秒统计一次。
统计信息每列的具体含义如下:
| Column | Description |
|---|---|
| S0 | Survivor space 0 utilization as a per- |
| centage of the space’s current capacity. | |
| S1 | Survivor space 1 utilization as a per- |
| centage of the space’s current capacity. | |
| E | Eden space utilization as a percentage of |
| the space’s current capacity. | |
| O | Old space utilization as a percentage of |
| the space’s current capacity. | |
| M | Metaspace utilization as a percentage of |
| the space’s current capacity. | |
| CCS | Compressed class space utilization as a |
| percentage. | |
| YGC | Number of young generation GC events. |
| YGCT | Young generation garbage collection time. |
| FGC | Number of Full GC events. |
| FGCT | Full garbage collection time. |
| GCT | Total garbage collection time. |
关于 jstat 命令更多的说明,可见 官方文档。
通过上述命令,可以观察到最初现象中描述的故障时 Java 应用的 GC 状态。
GC 日志
jstat 统计的是应用在执行命令时的状态,通常我们不能预知故障发生,并提前使用 jstat 进行监控,这时可以选择将应用的 GC 状况输出到日志文件中,以便后续查询和分析。在启动 Java 应用时,可以选择添加如下参数:
-Xloggc:/home/admin/filelogs/gc.log
-XX:+PrintGCDetails
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=5
-XX:GCLogFileSize=200mJava 的参数大致可以分为三类:
- 标准参数(
-),如:-jar、-Dproperty=value - 非标准参数(
-X),如:-Xms、-Xmx - 高级参数(
-XX),如:-XX:+HeapDumpOnOutOfMemoryError、-XX:HeapDumpPath=path
上面添加的 GC 日志相关参数的意思为:
每次 GC 时,将 GC 日志输出至指定文件,并启用日志文件滚动,滚动文件数量 5 个,每个文件大小 200mb 。
各类参数的详细说明,可参见 官方文档。
也可通过如下命令查看所使用的 Java 版本支持的所有高级参数:
$ java -XX:+PrintFlagsFinal -versionjmap -heap
通过 GC 统计及日志,可以发现 GC 的执行时间、次数、耗时,以及每次 GC 所释放的内存情况。
正常情况下,对象均应在年轻代被创建,使用过后被年轻代 GC 回收,回收不了的对象进入幸存区,在年轻代经历多次 GC 仍不能被回收的对象,会被移至老年代,当老年代空间也被使用满或无法放入新对象时,触发 Full GC。
YGC 执行时间短,对系统影响较小,而 FGC 会引发 STW(Stop the world),占用大量计算资源,执行时间较长,对系统影响较大。所以 YGC 的次数,应该明显高于 FGC,且每次 FGC 应该能够有内存空间被释放出来。
当频繁发生 FGC,且对系统造成比较大的影响时,可以先通过 jmap(memory map)命令查看堆的内存分配及使用情况,如:
$ jmap -heap 7114
Attaching to process ID 7114, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.121-b13
using thread-local object allocation.
Parallel GC with 8 thread(s)
Heap Configuration:
MinHeapFreeRatio = 0
MaxHeapFreeRatio = 100
MaxHeapSize = 20971520 (20.0MB)
NewSize = 3145728 (3.0MB)
MaxNewSize = 6815744 (6.5MB)
OldSize = 7340032 (7.0MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
PS Young Generation
Eden Space:
capacity = 2621440 (2.5MB)
used = 538160 (0.5132293701171875MB)
free = 2083280 (1.9867706298828125MB)
20.5291748046875% used
From Space:
capacity = 1572864 (1.5MB)
used = 1572864 (1.5MB)
free = 0 (0.0MB)
100.0% used
To Space:
capacity = 2097152 (2.0MB)
used = 0 (0.0MB)
free = 2097152 (2.0MB)
0.0% used
PS Old Generation
capacity = 14155776 (13.5MB)
used = 11533024 (10.998748779296875MB)
free = 2622752 (2.501251220703125MB)
81.47221317997685% used
13542 interned Strings occupying 1172704 bytes.分析
通过 jmap -heap <pid> 观察对比应用重启后,以及发生故障时堆的分配情况,发现故障时,S0(From Space/Survivor1) 及 S1(To Space/Survivor2) 被分配的空间非常小(几 mb,甚至为 0mb),堆的大部分空间被老年代占据且无法释放,当 Eden 区也被占满后,本应进行 Young GC,但 S0 和 S1 均没有空间了,只能触发 Full GC 希望能从老年代中释放出一些空间。然而此时老年代中的对象均未能释放,导致 Full GC 时间长且无效果,进而引起频繁 Full GC。
出现这种状况时,基本可以断定应用中出现了内存泄露,导致垃圾收集器无法回收内存。
要解决这个问题,我们首先需要知道内存中究竟都存放了哪些对象,以及这些对象为什么不能被垃圾回收。
jmap -histo
使用 jmap 命令,还可以获得堆中对象的柱状图统计信息,如:
$ jmap -histo:live 7114 | more
num #instances #bytes class name
----------------------------------------------
1: 29510 2809856 [C
2: 6998 769912 java.lang.Class
3: 29465 707160 java.lang.String
4: 21190 678080 java.util.concurrent.ConcurrentHashMap$Node
5: 6549 318440 [Ljava.lang.Object;
6: 2043 306528 [B
:注意:
:live参数会触发 FGC,以保证统计出的都是存活的对象。如果想保留现场,可不添加此参数。
jmap -dump
从柱状图统计信息中,可以了解到堆中占用内存最多的类及实例数量,但无法得知这些对象为什么不能被垃圾回收,此时可以进行堆转储(heap dump),以便进一步分析:
$ jmap -h
...
-dump:<dump-options> to dump java heap in hprof binary format
dump-options:
live dump only live objects; if not specified,
all objects in the heap are dumped.
format=b binary format
file=<file> dump heap to <file>
...$ jmap -dump:live,format=b,file=/path/to/heap.hprof 7114
Dumping heap to /path/to/heap.hprof ...
Heap dump file createdlive 参数同上,不想触发 FGC,可直接去掉,如:
$ jmap -dump:format=b,file=/path/to/heap.hprof 7114jvisualvm
分析堆 dump 文件,可以使用 JDK 自带的 jvisualvm 工具,命令行中直接输入即可:
$ jvisualvm打开界面后,选择 文件 -> 装入,选择 hprof 类型,并将堆 dump 文件导入即可:
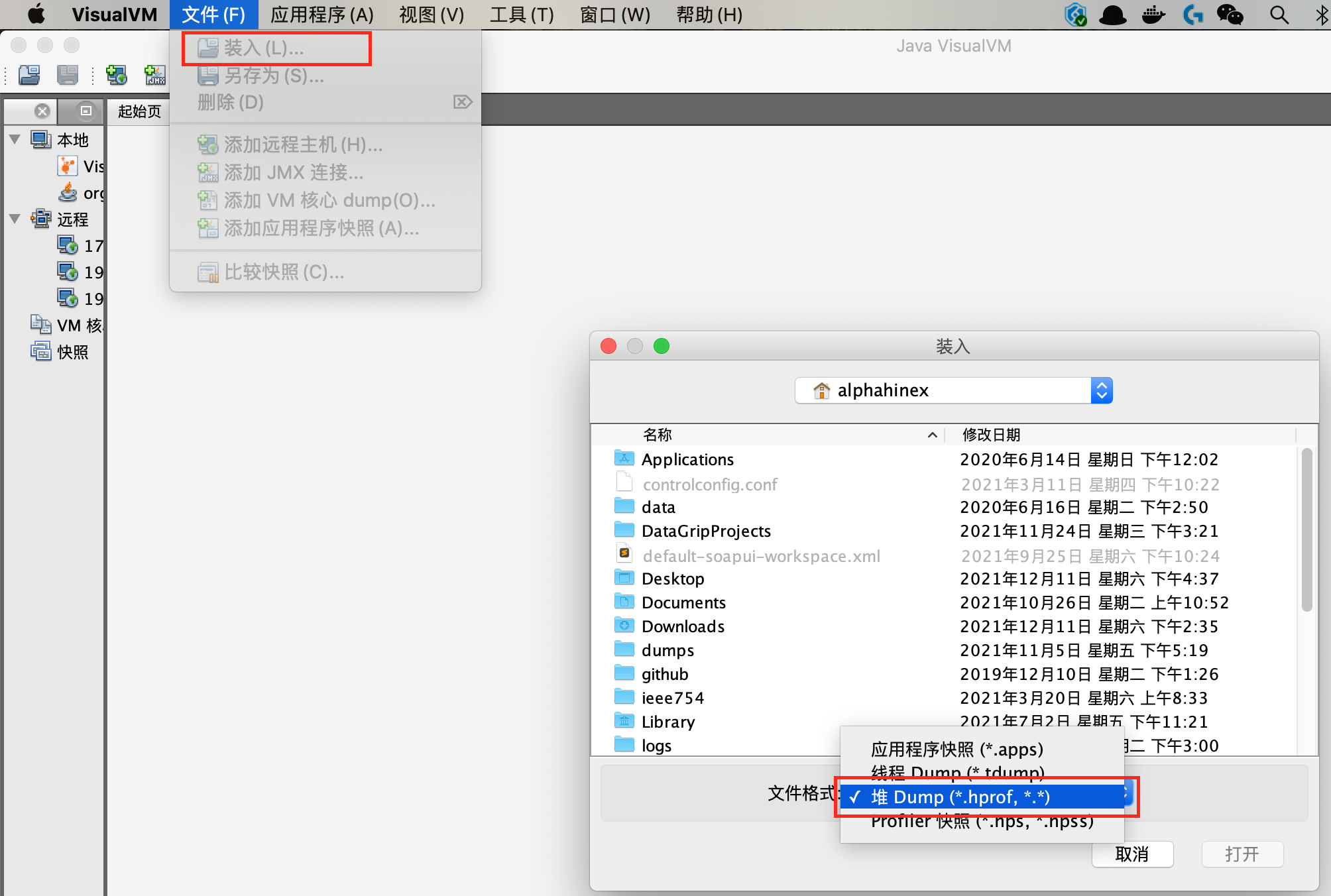
在装载比较大的 heap dump 文件时,可能会出现内存溢出等问题,可使用 -J 指定 Java 标准参数,如:
$ jvisualvm -J-Xms2048m -J-Xmx4096mjvisualvm 虽然比 jmap -histo 直观了一些,但用来分析问题,能够获取的信息还是比较少,并且在分析比较大的堆转储文件时,性能低下,实用性较低。
MAT
Eclipse 出品的 Memory Analyzer (MAT) 工具是一个更好的选择,能够快速的对大 dump 文件进行分析,并且功能丰富。
在分析较大堆文件时,也可能会遇到软件本身内存溢出的问题,可通过在配置文件中指定 Java 标准参数中的内存参数进行调整,如在 Mac 中,可在 /Applications/mat.app/Contents/Eclipse/MemoryAnalyzer.ini 中添加 Xmx 的配置。
MAT 解析完堆文件后,会提供泄露分析报告等,方便快速定位问题。
关于 MAT 的使用,可以参照 官方文档
原因
使用 MAT 分析本文最初描述现象的故障节点 heap dump 文件,在 Dominator Tree 视图中,发现大量内存空间被某类线程所占用:
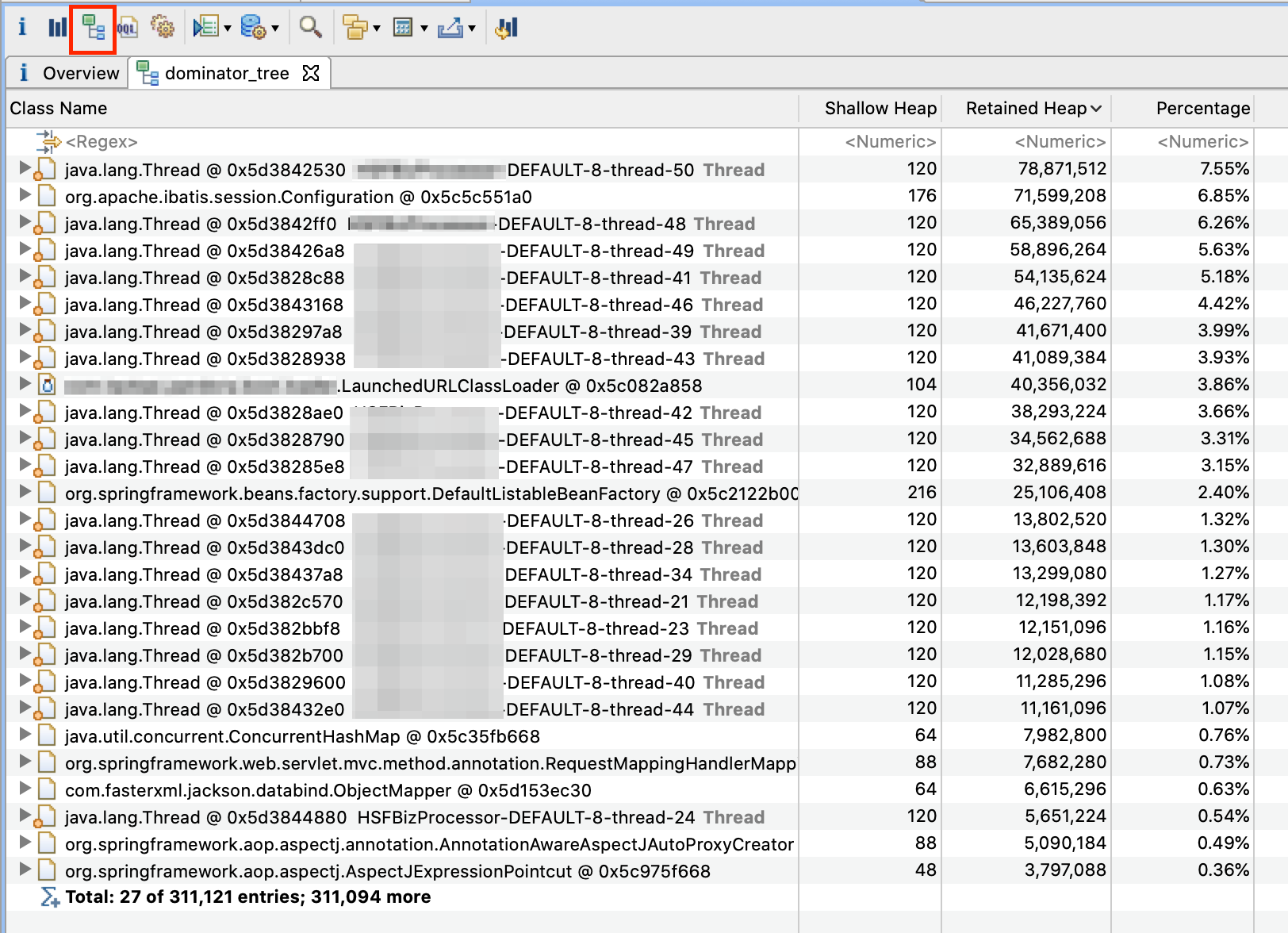
而线程中存在大量线程变量引用的集合对象,类似 ThreadLocal<Map<String, List<Object>>> 这种结构,因为使用了线程池,线程使用后没有对 ThreadLocal 对象进行 clear 操作,导致线程变量泄露,占用了大量内存,无法被 GC 回收,进而导致了最初的故障现象。
