译者序
- 现在,我们在七牛内部全面推广和应用 Kubernetes,不仅把无状态服务运行在 Kubernetes 中,也把有状态服务比如数据库运行在 Kubernetes 中,正如使用 GoLang 提高了我们的开发效率一样,使用 Kubernetes 大大提高了我们的部署和运维效率。
1 Kubernetes 介绍
1.2.1 什么是容器
- 如果多个进程运行在同一个操作系统上,那容器到底是怎样隔离它们的。有两个机制可用:第一个是 Linux 命名空间,它使每个进程只看到它自己的系统视图(文件、进程、网络接口、主机名等);第二个是 Linux 控制组(cgroups),它限制了进程能使用的资源量(CPU、内存、网络带宽等)。
1.2.2 Docker 容器平台介绍
- 基于 Docker 容器的镜像和虚拟机镜像的一个很大的不同是容器镜像是由多层构成,它能在多个镜像之间共享和征用。如果某个已经被下载的容器镜像已经包含了后面下载镜像的某些层,那么后面下载的镜像就无须再下载这些层。
- 层不仅使分发更高效,也有助于减少镜像的存储空间。每一层仅被存一次,当基于相同基础层的镜像被创建成两个容器时,它们就能够读相同的文件。但是如果其中一个容器写入某些文件,另外一个是无法看见文件变更的。因此,即使它们共享文件,仍然彼此隔离。这是因为容器镜像层是只读的。容器运行时,一个新的可写层在镜像层之上被创建。容器中进程写入位于底层的一个文件时,此文件的一个拷贝在顶层被创建,进程写的是此拷贝。
- 如果一个容器化的应用需要一个特定的内核版本,那它可能不能在每台机器上都工作。如果一台机器上运行了一个不匹配的 Linux 内核版本,或者没有相同内核模块可用,那么此应用就不能在其上运行。
2 开始使用 Kubernetes 和 Docker
2.1.1 安装 Docker 并运行 Hello World 容器
- busybox 是一个单一可执行文件,包含多种标准 UNIX 命令行工具,如:echo、ls、gzip 等。
2.1.4 构建容器镜像
- 构建镜像时,Dockerfile 中每一条单独的指令都会创建一个新层。镜像构建的过程中,拉取基础镜像所有分层之后,Docker 在它们上面创建一个新层并且添加 app.js。然后会创建另一层来指定镜像被运行时所执行的命令。最后一层会被标记为 kubia:latest。
2.1.6 探索运行容器的内部
- 容器内的进程运行在主机操作系统上
3 pod: 运行于 Kubernetes 中的容器
3.1.1 为何需要 pod
- 容器被设计为每个容器只运行一个进程(除非进程本身产生子进程)。如果在单个容器中运行多个不相关的进程,那么保持所有进程运行、管理它们的日志等将会是我们的责任。例如,我们需要包含一种在进程崩溃时能够自动重启的机制。同时这些进程都将记录到相同的标准输出中,而此时我们将很难确定每个进程分别记录了什么。
3.1.2 了解 pod
- 由于一个 pod 中的容器运行于相同的 Network 命名空间中,因此它们共享相同的 IP 地址和端口空间。这意味着在同一 pod 中的容器运行的多个进程需要注意不能绑定到相同的端口号,否则会导致端口冲突,但这只涉及同一 pod 中的容器。
- 一个 pod 中的所有容器也都具有相同的 loopback 网络接口,因此容器可以通过 localhost 与同一 pod 中的其他容器进行通信。
3.2.5 向 pod 发送请求
- 如果想要在不通过 service 的情况下与某个特定的 pod 进行通信(出于调试或其他原因),Kubernetes 将允许我们配置端口转发到该 pod。可以通过 kubectl port-forward 命令完成上述操作。例如以下命令会将机器的本地端口 8888 转发到我们的 kubia-manual pod 的端口 8080:
$ kubectl port-forward kubia-manual 8888:8080 ... Forwarding from 127.0.0.1:8888 -> 8080 ... Forwarding from [::1]:8888 -> 8080
3.6 注解 pod
- 注解也是键值对,所以它们本质上与标签非常相似。但与标签不同,注解并不是为了保存标识信息而存在的,它们不能像标签一样用于对对象进行分组。当我们可以通过标签选择器选择对象时,就不存在注解选择器这样的东西。
3.6.1 查找对象的注解
- 相对而言,标签应该简短一些,而注解则可以包含相对更多的数据(总共不超过256KB)。
3.8.1 按名称删除pod
- 在删除 pod 的过程中,实际上我们在指示 Kubernetes 终止该 pod 中的所有容器。Kubernetes 向进程发送一个 SIGTERM 信号并等待一定的秒数(默认为30),使其正常关闭。如果它没有及时关闭,则通过 SIGKILL 终止该进程。因此,为了确保你的进程总是正常关闭,进程需要正确处理 SIGTERM 信号。
3.8.5 删除命名空间中的(几乎)所有资源
kubectl delete all --all- 命令中的第一个 all 指定正在删除所有资源类型,而 –all 选项指定将删除所有资源实例,而不是按名称指定它们
- 注意:使用 all 关键字删除所有内容并不是真的完全删除所有内容。一些资源(比如我们将在第7章中介绍的 Secret)会被保留下来,并且需要被明确指定删除。
4 副本机制和其他控制器: 部署托管的 pod
4.1.3 使用存活探针
- 在前一章中,你学习了如何使用 kubectl logs 打印应用程序的日志。如果你的容器重启,kubectl logs 命令将显示当前容器的日志。当你想知道为什么前一个容器终止时,你想看到的是前一个容器的日志,而不是当前容器的。可以通过添加 –previous 选项来完成:
kubectl logs mypod --previous - 可以通过查看 kubectl describe 的内容来了解 为什么必须重启容器,如下面的代码清单所示。
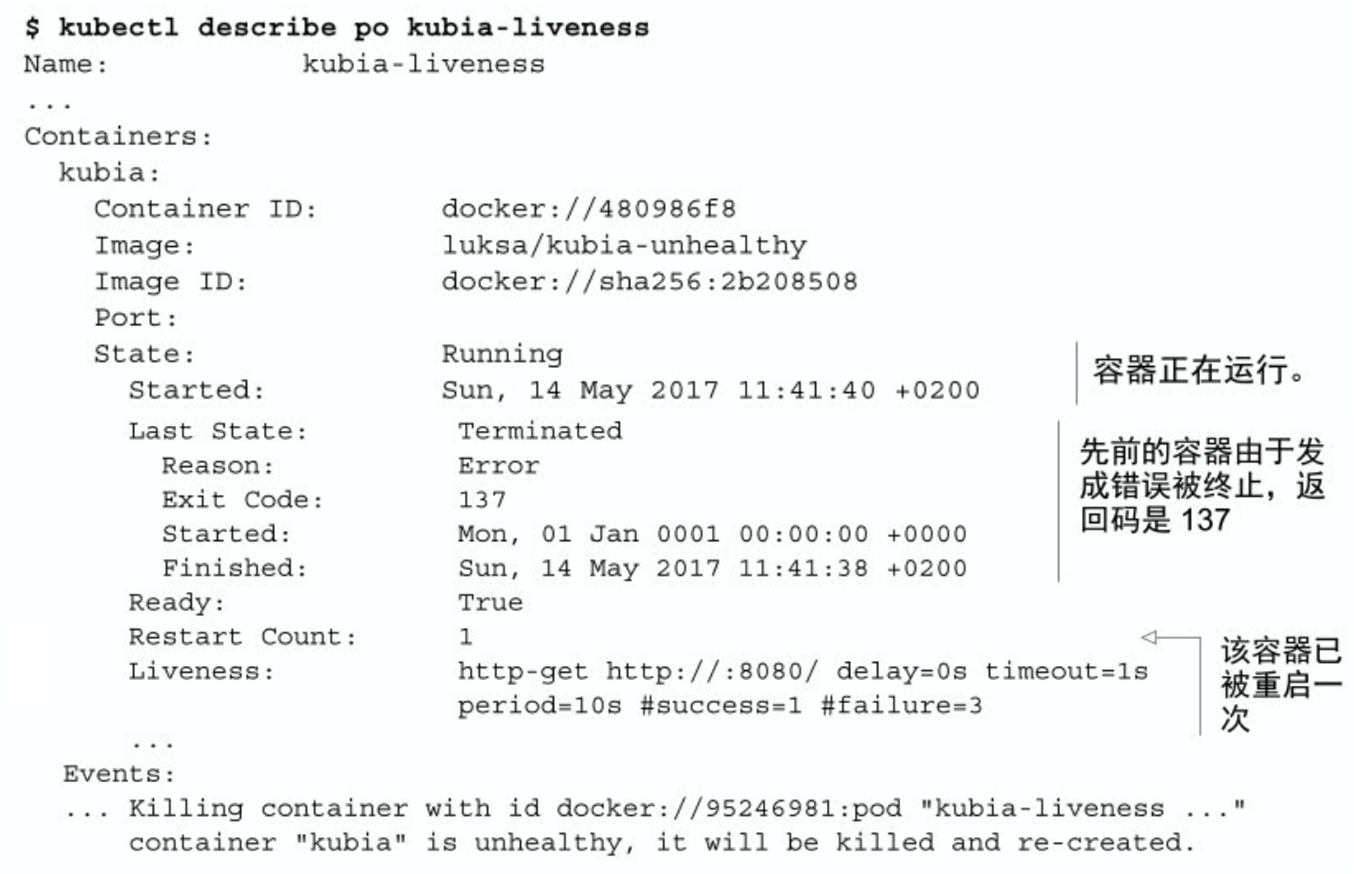
- 可以看到容器现在正在运行,但之前由于错误而终止。退出代码为 137,这有特殊的含义 —— 表示该进程由外部信号终止。数字 137 是两个数字的总和:128+x,其中 x 是终止进程的信号编号。在这个例子中,x 等于 9,这是 SIGKILL 的信号编号,意味着这个进程被强行终止。
- 在底部列出的事件显示了容器为什么终止 —— Kubernetes 发现容器不健康,所以终止并重新创建。
4.1.4 配置存活探针的附加属性
- 注意:退出代码 137 表示进程被外部信号终止,退出代码为 128+9 (SIGKILL)。同样,退出代码 143 对应于 128+15 (SIGTERM)。
4.2.4 将 pod 移入或移出 ReplicationController 的作用域
- 尽管一个 pod 没有绑定到一个 ReplicationController,但该 pod 在 metadata.ownerReferences 字段中引用它,可以轻松使用它来找到一个 pod 属于哪个 ReplicationController。
- 当你想操作特定的 pod 时,从 ReplicationController 管理范围中移除 pod 的操作很管用。例如,你可能有一个 bug 导致你的 pod 在特定时间或特定事件后开始出问题。如果你知道某个 pod 发生了故障,就可以将它从 Replication-Controller 的管理范围中移除,让控制器将它替换为新 pod,接着这个 pod 就任你处置了。完成后删除该 pod 即可。
4.2.7 删除一个 ReplicationController
- 当使用 kubectl delete 删除 ReplicationController 时,可以通过给命令增加 –cascade=false 选项来保持 pod 的运行。
4.3 使用 ReplicaSet 而不是 ReplicationController
- 最初,ReplicationController 是用于复制和在异常时重新调度节点的唯一 Kubernetes 组件,后来又引入了一个名为 ReplicaSet 的类似资源。它是新一代的 ReplicationController,并且将其完全替换掉 ( ReplicationController 最终将被弃用)。
4.3.1 比较 ReplicaSet 和 ReplicationController
- ReplicaSet 的行为与 ReplicationController 完全相同,但 pod 选择器的表达能力更强。
4.3.4 使用 ReplicaSet 的更富表达力的标签选择器
- 一个 matchExpressions 选择器,要求该 pod 包含名为“app”的标签,标签的值必须是“kubia”
selector: matchExpressions: - key: app operator: In values: - kubia
4.5.2 定义 Job 资源
- 在一个 pod 的定义中,可以指定在容器中运行的进程结束时,Kubernetes 会做什么。这是通过 pod 配置的属性 restartPolicy 完成的,默认为 Always。Job pod 不能使用默认策略,因为它们不是要无限期地运 行。因此,需要明确地将重启策略设置为 OnFailure 或 Never。此设置防止容器在完成任务时重新启动( pod 被 Job 管理时并不是这样的)。
4.5.4 在 Job 中运行多个 pod 实例
- 作业可以配置为创建多个 pod 实例,并以并行或串行方式运行它们。这是通过在 Job 配置中设置 completions 和 parallelism 属性来完成的。
- 将 completions 设置为 5,将使此作业顺序运行五个 pod。Job 将一个接一个地运行五个 pod。它最初创建一个 pod,当 pod 的容器运行完成时,它创建第二个 pod,以此类推,直到五个pod成功完成。如果其中一个 pod 发生故障,工作会创建一个新的 pod,所以 Job 总共可以创建五个以上的 pod。
apiVersion: batch/v1 kind: Job metadata: name: multi-completion-batch-job spec: completions: 5 template: ... - 这项任务必须确保五个 pod 成功完成,最多运行两个 pod 可以并行运行:
apiVersion: batch/v1 kind: Job metadata: name: multi-completion-batch-job spec: completions: 5 parallelism: 2 template: ... - Job 的缩放:你甚至可以在 Job 运行时更改 Job 的 parallelism 属性。这与缩放 ReplicaSet 或 ReplicationController 类似,可以使用 kubectl scale 命令完成:
$ kubectl scale job multi-completion-batch-job --replicas 3 job "multi-completion-batch-job" scaled
4.5.5 限制 Job pod 完成任务的时间
- 通过在 pod 配置中设置 activeDeadlineSeconds 属性,可以限制 pod的时间。如果 pod 运行时间超过此时间,系统将尝试终止 pod,并将 Job 标记为失败。
- 通过指定 Job manifest 中的 spec.backoffLimit 字段,可以配置 Job 在被标记为失败之前可以重试的次数。如果你没有明确指定它,则默认为 6。
4.6.2 了解计划任务的运行方式
- 在正常情况下,CronJob 总是为计划中配置的每个执行创建一个 Job,但可能会同时创建两个 Job,或者根本没有创建。为了解决第一个问题,你的任务应该是幂等的(多次而不是一次运行不会得到不希望的结果)。对于第二个问题,请确保下一个任务运行完成本应该由上一次的(错过的)运行完成的任何工作。
5 服务: 让客户端发现 pod 并与之通信
5.1.1 创建服务
$ kubectl exec kubia-7nog1 -- curl -s http://10.111.249.153
You've hit kubia-gzwli- 双横杠(–)代表着 kubectl 命令项的结束。在两个横杠之后的内容是指在 pod 内部需要执行的命令。如果需要执行的命令并没有以横杠开始的参数,横杠也不是必需的。
- Kubernetes 仅仅支持两种形式的会话亲和性服务: None 和 ClientIP。你或许惊讶竟然不支持基于 cookie 的会话亲和性的选项,但是你要了解 Kubernetes 服务不是在 HTTP 层面上工作。服务处理 TCP 和 UDP 包,并不关心其中的载荷内容。因为 cookie 是 HTTP 协议中的一部分,服务并不知道它们,这就解释了为什么会话亲和性不能基于 cookie。
- 为什么要采用命名端口的方式?最大的好处就是即使更换端口号也无须更改服务 spec。
5.1.2 服务发现
- 全限定域名(FQDN),如 backend-database.default.svc.cluster.local
- curl 这个服务是工作的,但是却 ping 不通。这是因为服务的集群 IP 是一个虚拟 IP,并且只有在与服务端口结合时才有意义。
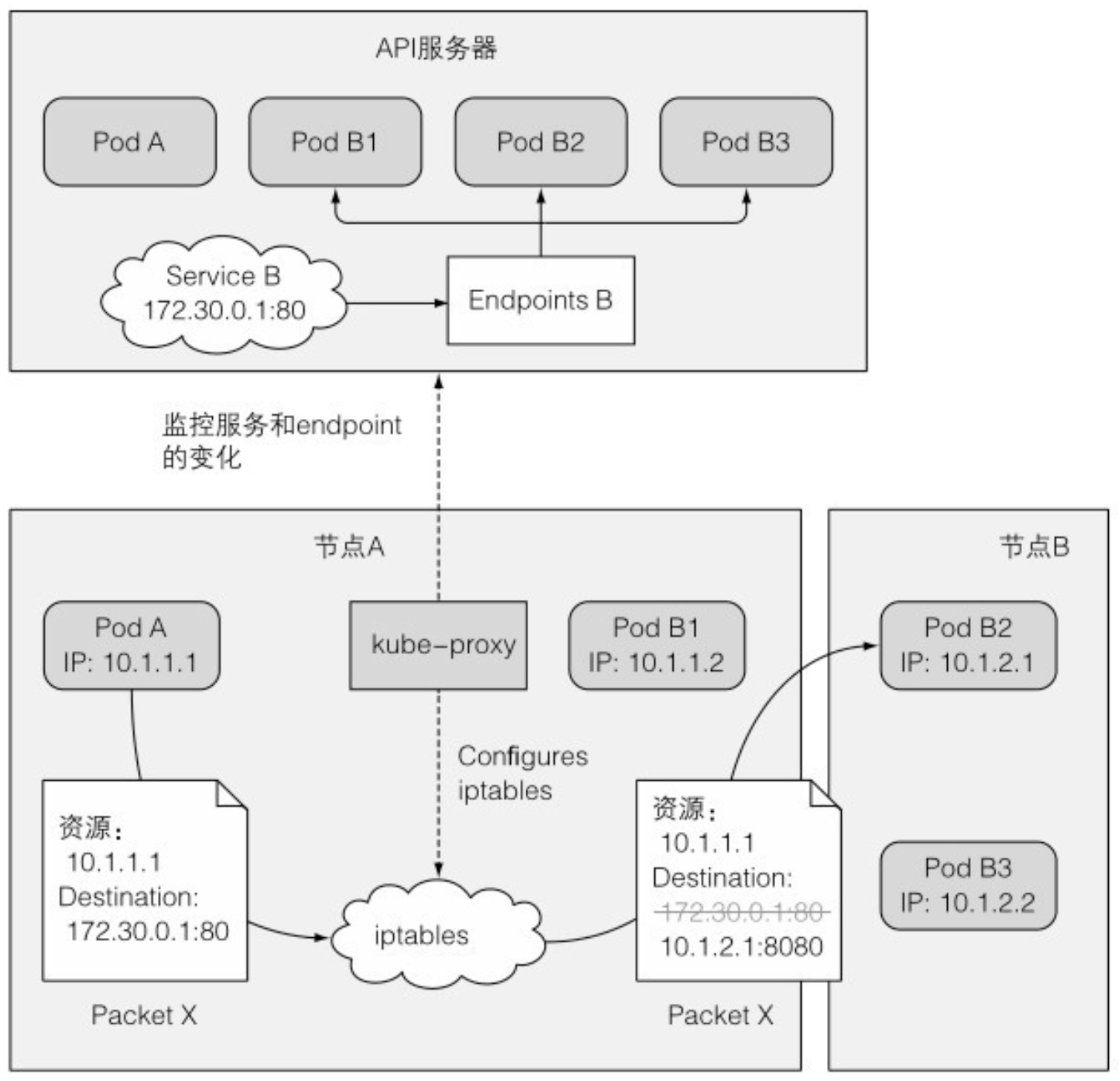
5.2.1 介绍服务 endpoint
- 服务并不是和 pod 直接相连的。相反,有一种资源介于两者之间——它就是 Endpoint 资源。
5.2.2 手动配置服务的 endpoint
- 如果创建了不包含 pod 选择器的服务,Kubernetes 将不会创建 Endpoint 资源。这样就需要创建 Endpoint 资源来指定该服务的 endpoint 列表。
- 服务的名字必须和 Endpoint 对象的名字相匹配。
- Endpoint 对象需要与服务具有相同的名称,并包含该服务的目标 IP 地址和端口列表。
- 如果稍后决定将外部服务迁移到 Kubernetes 中运行的 pod,可以为服务添加选择器,从而对 Endpoint 进行自动管理。反过来也是一样的 —— 将选择器从服务中移除,Kubernetes 将停止更新 Endpoints。这意味着服务的 IP 地址可以保持不变,同时服务的实际实现却发生了改变。
5.2.3 为外部服务创建别名
- 除了手动配置服务的 Endpoint 来代替公开外部服务方法,有一种更简单的方法,就是通过其完全限定域名(FQDN)访问外部服务。
- 代码的 type 被设置成 ExternalName,
externalName使用实际服务的完全限定域名apiVersion: v1 kind: Service metadata: name: external-service spec: type: ExternalName externalName: someapi.somecompany.com ports: - port: 80 - ExternalName 服务仅在 DNS 级别实施 —— 为服务创建了简单的 CNAME DNS 记录。因此,连接到服务的客户端将直接连接到外部服务,完全绕过服务代理。出于这个原因,这些类型的服务甚至不会获得集群IP。
- CNAME 记录指向完全限定的域名而不是数字 IP 地址。
5.3.1 使用 NodePort 类型的服务
- 使用 JSONPath 获取所有节点的 IP

5.5.3 了解就绪探针的实际作用
- 当一个容器关闭时,运行在其中的应用程序通常会在收到终止信号后立即停止接收连接。
- 只要删除该容器,Kubernetes就会从所有服务中移除该容器。
5.6 使用 headless 服务来发现独立的 pod
- Kubernetes 允许客户通过 DNS 查找发现 pod IP。通常,当执行服务的 DNS 查找时,DNS 服务器会返回单个 IP —— 服务的集群 IP。但是,如果告诉 Kubernetes,不需要为服务提供集群 IP(通过在服务 spec 中将 clusterIP 字段设置为 None 来完成此操作),则 DNS 服务器将返回 pod IP 而不是单个服务 IP。
- DNS 服务器不会返回单个 DNS A 记录,而是会为该服务返回多个 A 记录,每个记录指向当时支持该服务的单个 pod 的 IP。客户端因此可以做一个简单的 DNS A 记录查找并获取属于该服务一部分的所有 pod 的 IP。客户端可以使用该信息连接到其中的一个、多个或全部。
5.6.1 创建 headless 服务
- 将服务 spec 中的 clusterIP 字段设置为 None 会使服务成为 headless 服务,因为 Kubernetes 不会为其分配集群 IP,客户端可通过该 IP 将其连接到支持它的 pod。
- 在使用 kubectl create 创建 headless 服务之后,可以通过 kubectl get 和 kubectl describe 来查看服务,你会发现它没有集群 IP,并且它的后端包含与 pod 选择器匹配的(部分) pod。“部分”是因为 pod 包含就绪探针,所以只有准备就绪的 pod 会被列出。
5.6.2 通过 DNS 发现 pod
- 理解 headless 服务的 DNS A 记录解析
$ kubectl exec dnsutils nslookup kubia-headless ... Name: kubia-headless.default.svc.cluster.local Address: 10.108.1.4 Name: kubia-headless.default.svc.cluster.local Address: 10.108.2.5 - DNS 服务器为 kubia-headless.default.svc.cluster.local FQDN 返回两个不同的IP。这些是报告准备就绪的两个 pod 的 IP。
- 这与常规(非 headless 服务)服务返回的 DNS 不同,比如 kubia 服务,返回的 IP 是服务的集群 IP:
$ kubectl exec dnsutils nslookup kubia ... Name: kubia.default.svc.cluster.local Address: 10.111.249.153 - 尽管 headless 服务看起来可能与常规服务不同,但在客户的视角上它们并无不同。即使使用 headless 服务,客户也可以通过连接到服务的 DNS 名称来连接到 pod上,就像使用常规服务一样。但是对于 headless 服务,由于 DNS 返回了 pod 的 IP,客户端直接连接到该 pod,而不是通过服务代理。
- headless 服务仍然提供跨 pod 的负载平衡,但是通过 DN S轮询机制不是通过服务代理。
5.6.3 发现所有的 pod —— 包括未就绪的 pod
- 要告诉 Kubernetes 无论 pod 的准备状态如何,希望将所有 pod 添加到服务中。必须将以下注解添加到服务中:
kind: Service metadata: annotations: service.alpha.kubernetes.io/tolerate-unready-endpoints: "true" - 警告:就像说的那样,注解名称表明了这是一个 alpha 功能。Kubernetes Service API 已经支持一个名为 publishNotReadyAddresses 的新服务规范字段,它将替换 tolerate-unready-endpoints 注解。在Kubernetes 1.9.0 版本中,这个字段还没有实现(这个注解决定了未准备好的 endpoints 是否在 DNS 的记录中)。检查文档以查看是否已更改。
5.7 排除服务故障
- 不要通过 ping 服务 IP 来判断服务是否可访问(请记住,服务的集群 IP 是虚拟 IP,是无法 ping 通的)。
- 要确认某个容器是服务的一部分,请使用 kubectl get endpoints 来检查相应的端点对象。
5.8 本章小结
- 使用 kubectl run–generator=run-pod/v1 运行临时的 pod
6 卷: 将磁盘挂载到容器
- Kubernetes 通过定义存储卷来满足这个需求,它们不像 pod 这样的顶级资源,而是被定义为 pod 的一部分,并和 pod 共享相同的生命周期。这意味着在 pod 启动时创建卷,并在删除 pod 时销毁卷。因此,在容器重新启动期间,卷的内容将保持不变,在重新启动容器之后,新容器可以识别前一个容器写入卷的所有文件。另外,如果一个 pod 包含多个容器,那这个卷可以同时被所有的容器使用。
6.1 介绍卷
- pod 中的所有容器都可以使用卷,但必须先将它挂载在每个需要访问它的容器中。
6.2.1 使用 emptyDir 卷
- 可以通知 Kubernetes 在 tmfs 文件系统(存在内存而非硬盘)上创建 emptyDir。因此,将 emptyDir 的 medium 设置为 Memory,emptyDir 的文件将会存储在内存中:
volumes: - name: html emptyDir: medium: Memory
6.2.2 使用 Git 仓库作为存储卷
- gitRepo 卷基本上也是一个 emptyDir 卷,它通过克隆 Git 仓库并在 pod 启动时(但在创建容器之前)检出特定版本来填充数据
6.5.2 创建持久卷
- 和集群节点一样,持久卷不属于任何命名空间,区别于 pod 和持久卷声明
6.6 持久卷的动态卷配置
- 与持久卷类似,StorageClass 资源并非命名空间。
6.6.3 不指定存储类的动态配置
- 如果希望 PVC 使用预先配置的 PV,请将 storageClassName 显式设置为””。将空字符串指定为存储类名可确保 PVC 绑定到预先配置的 PV,而不是动态配置新的 PV
kind: PersistentVolumeClaim spec: storageClassName: ""
7 ConfigMap 和 Secret: 配置应用程序
7.2.1 在 Docker 中定义命令与参数
- 尽管可以直接使用 CMD 指令指定镜像运行时想要执行的命令,正确的做法依旧是借助 ENTRYPOINT 指令,仅仅用 CMD 指定所需的默认参数。这样,镜像可以直接运行,无须添加任何参数:
docker run <image> - 或者是添加一些参数,覆盖 Dockerile 中任何由 CMD 指定的默认参数值:
docker run <image> <arguments> - shell 形式 —— 如 ENTRYPOINT node app.js。
$ docker exec -it e4bad ps x PID TTY STAT TIME COMMAND 1 ? Ss 0:00 /bin/sh -c node app.js 7 ? Sl 0:00 node app.js 13 ? Rs+ 0:00 ps x - 可以看出,主进程(PID 1)是 shell 进程而非 node 进程,node 进程 (PID 7)于 shell 中启动。shell 进程往往是多余的,因此通常可以直接采用 exec 形式的 ENTRYPOINT 指令。
- exec 形式 —— 如 ENTRYPOINT[“node”,”app.js”]。
$ docker exec -it e4bad ps x PID TTY STAT TIME COMMAND 1 ? Ssl 0:00 node app.js 12 ? Rs 0:00 ps x - 两者的区别在于指定的命令是否是在 shell 中被调用。
7.3 为容器设置环境变量
- Kubernetes 允许为 pod 中的每一个容器都指定自定义的环境变量集合,尽管从 pod 层面定义环境变量同样有效,然而当前并未提供该选项。
7.3.1 在容器定义中指定环境变量
- 不要忘记在每个容器中,Kubernetes 会自动暴露相同命名空间下每个 service 对应的环境变量。这些环境变量基本上可以被看作自动注入的配置。
7.4.6 使用 configMap 卷将条目暴露为文件
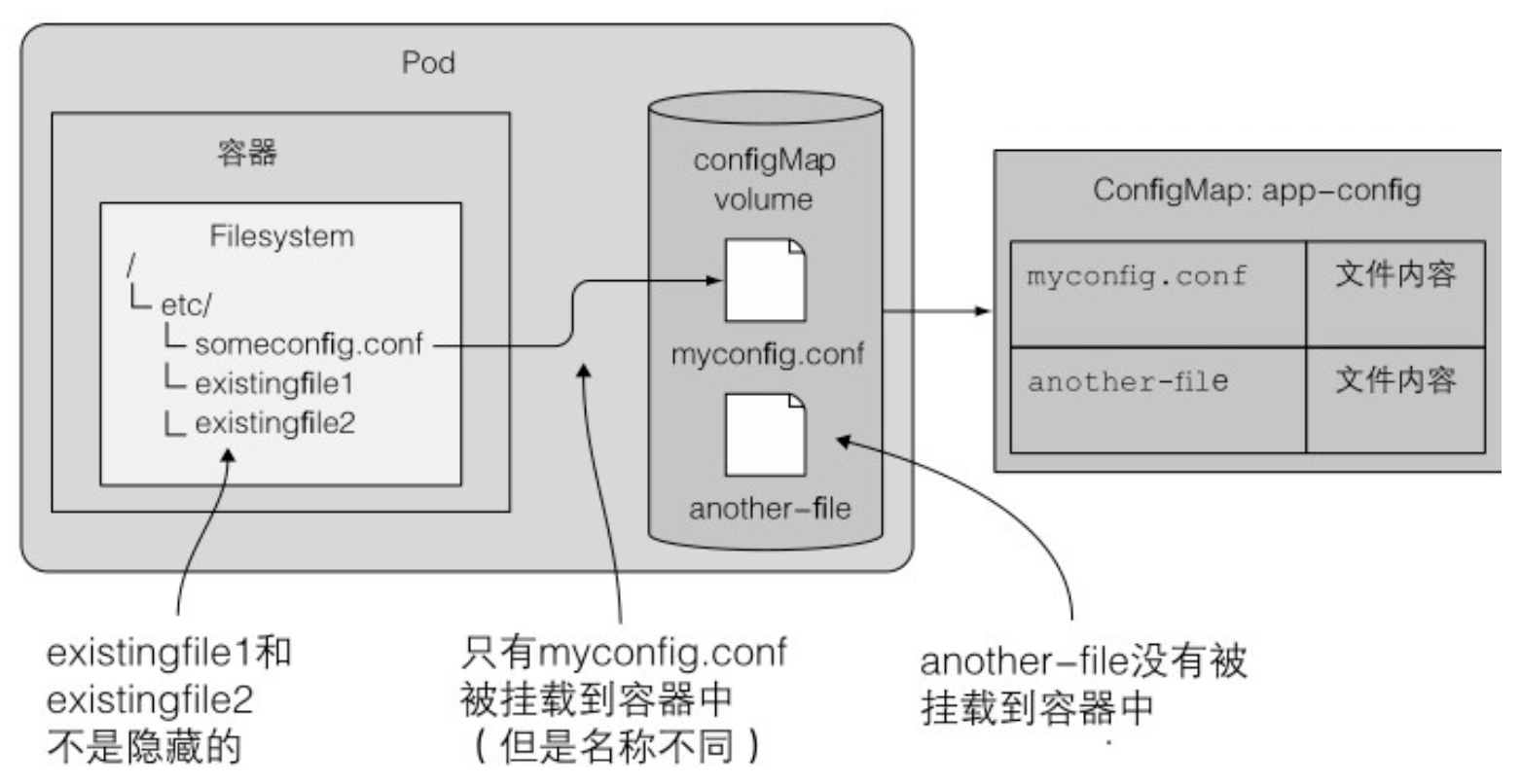
mountPath挂载至某一文件,而不是文件夹;subPath仅挂载指定的条目myconfig.conf,并非完整的卷spec: containers: - image: some/image volumeMounts: - name: myvolume mountPath: /etc/someconfig.conf subPath: myconfig.conf- configMap 卷中所有文件的权限默认被设置为 644(-rw-r-r–)。可以通过卷规格定义中的 defaultMode 属性改变默认权限
7.4.7 更新应用配置且不重启应用程序
- 涉及到更新 configMap 卷需要提出一个警告:如果挂载的是容器中的单个文件而不是完整的卷,ConfigMap 更新之后对应的文件不会被更新!至少在写本章节的时候表现如此。
7.5.1 介绍 Secret
- Kubernetes 通过仅仅将 Secret 分发到需要访问 Secret 的 pod 所在的机器节点来保障其安全性。另外,Secret 只会存储在节点的内存中,永不写入物理存储,这样从节点上删除 Secret 时就不需要擦除磁盘了。
7.5.2 默认令牌 Secret 介绍
- default-token Secret 默认会被挂载至每个容器。可以通过设置 pod 定义中的 automountServiceAccountToken 字段为 false,或者设置 pod 使用的服务账户中的相同字段为 false 来关闭这种默认行为。
7.5.4 对比 ConfigMap 与 Secret
- Secret 的大小限于 1MB。
8 从应用访问 pod 元数据以及其他资源
8.1.2 通过环境变量暴露元数据
- 容器请求的 CPU 和内存使用量是引用 resourceFieldRef 字段,而不是 fieldRef 字段
8.1.3 通过 downwardAPI 卷来传递元数据
- 通过将卷的名字设定为 downward 来定义一个 downwardAPI 卷;pod 的名称(来自 manifest 文件中的 metadata.name 字段)将被写入 podName 文件中;pod 的标签将被保存到 /etc/downward/labels 文件中
volumes:
- name: downward
downwardAPI:
items:
- path: "podName"
fieldRef:
fieldPath: metadata.name
- path: "podNamespace"
fieldRef:
fieldPath: metadata.namespace
- path: "labels"
fieldRef:
fieldPath: metadata.labels- 为什么不能通过环境变量的方式暴露标签和注解,在环境变量方式下,一旦标签和注解被修改,新的值将无法暴露。
- 当暴露容器级的元数据时,如容器可使用的资源限制或者资源请求(使用字段 resourceFieldRef),必须指定引用资源字段对应的容器名称(
containerName字段):spec: volumes: - name: downward downwardAPI: items: - path: "containerCpuRequestMilliCores" resourceFieldRef: containerName: main resource: requests.cpu divisor: 1m - 这样做的理由很明显,因为我们对于卷的定义是基于 pod 级的,而不是容器级的。当我们引用卷定义某一个容器的资源字段时,我们需要明确说明引用的容器的名称。这个规则对于只包含单容器的 pod 同样适用。
- 使用卷的方式来暴露容器的资源请求和使用限制比环境变量的方式稍显复杂,但好处是如果有必要,可以传递一个容器的资源字段到另一个容器(当然两个容器必须处于同一个 pod)。使用环境变量的方式,一个容器只能传递它自身资源申请求和限制的信息。
8.2.2 从 pod 内部与 API 服务器进行交互
- 首先,需要找到 Kubernetes API 服务器的 IP 地址和端口。这一点比较容易做到,因为一个名为 kubernetes 的服务在默认的命名空间被自动暴露,并被配置为指向 API 服务器。
- 每个服务都被配置了对应的环境变量,在容器内通过查询 KUBERNETES_SERVICE_HOST 和 KUBERNETES_SERVICE_PORT 这两个环境变量就可以获取 API 服务器的 IP 地址和端口。
- 每个服务都可以获得一个 DNS 入口,所以甚至没有必要去查询环境变量,而只是简单地将 curl 指向 https://kubernetes。
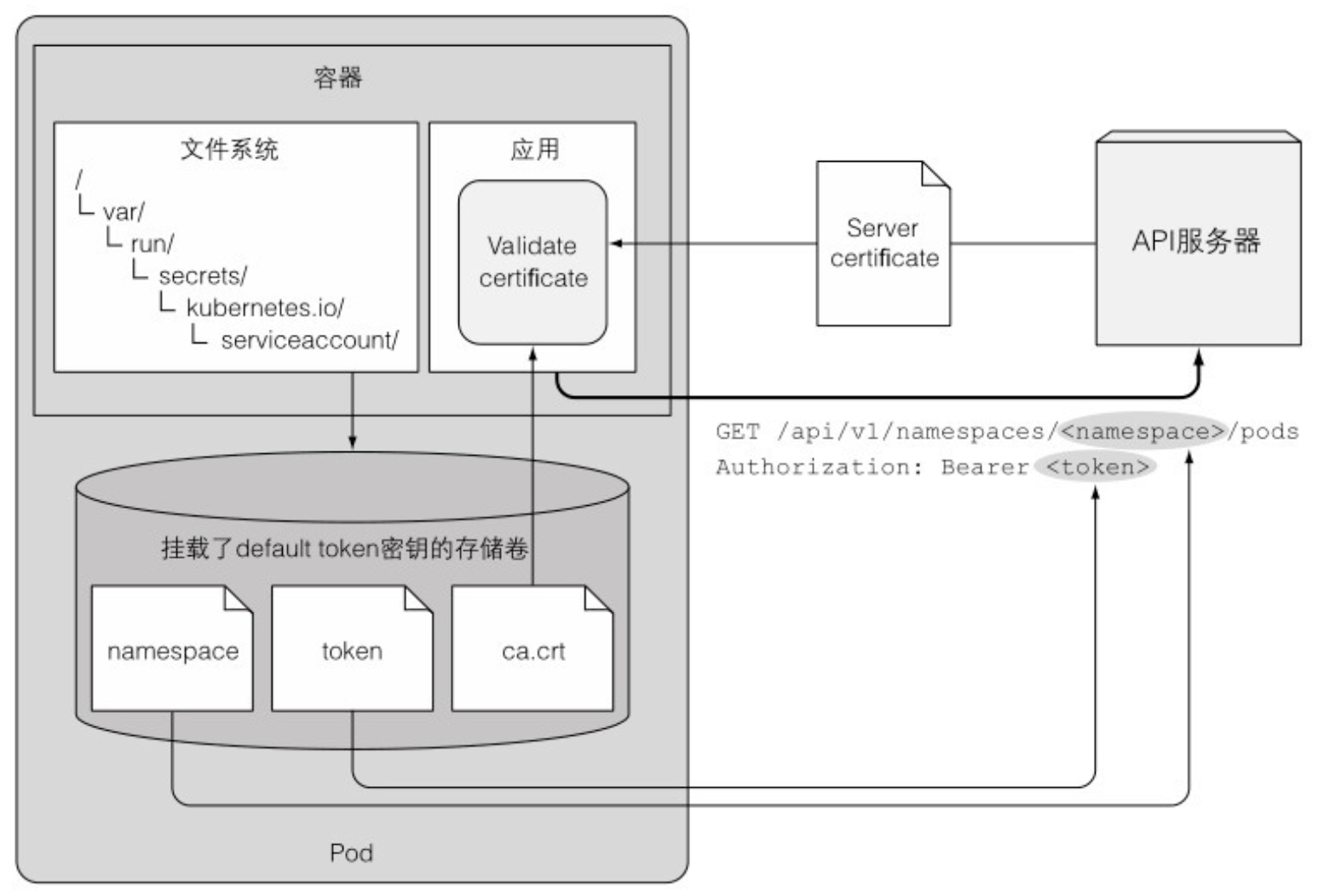
- 一个名为 defalut-token-xyz 的 Secret 被自动创建,并挂载到每个容器的 /var/run/secrets/kubernetes.io/serviceaccount 目录下。
root@curl:/# ls/var/run/secrets/kubernetes.io/serviceaccount/ ca.crt namespace token - curl 允许使用 -cacert 选项来指定 CA 证书,我们来尝试重新访问 API 服务器:
root@curl:/# curl --cacert /var/run/secrets/kubernetes.io/serviceaccount/ca.crt https://kubernetes Unauthorized - 通过设置 CURL_CA_BUNDLE 环境变量来简化操作,从而不必在每次运行 curl 时 都指定 –cacert 选项:
root@curl:/# export CURL_CA_BUNDLE=/var/run/secrets/kubernetes.io/serviceaccount/ca.crt # 现在,我们可以不使用 --cacert 来访问 API 服务器: root@curl:/# curl https://kubernetes Unauthorized - 我们需要获得 API 服务器的授权,以便可以读取并进一步修改或删除部署在集群中的 API 对象。为了获得授权,我们需要认证的凭证
- 可以使用凭证来访问 API 服务器,第一步,将凭证挂载到环境变量中:
root@curl:/# TOKEN=$(cat /var/run/secrets/kubernetes.io/serviceaccount/token) root@curl:/# curl -H "Authorization: Bearer $TOKEN" https://kubernetes { "path": [ "/api", "/api/v1", ... "/ui/", "/version" ] } - secret 卷中也包含了一个叫作命名空间的文件。这个文件包含了当前运行 pod 所在的命名空间,所以我们可以读取这个文件来获得命名空间信息
- 应用应该验证 API 服务器的证书是否是证书机构所签发,这个证书是在 ca.crt 文件中。
- 应用应该将它在 token 文件中持有的凭证通过 Authorization 标头来获得 API 服务器的授权。
- 当对 pod 所在命名空间的 API 对象进行 CRUD 操作时,应该使用 namespace 文件来传递命名空间信息到 API 服务器。
8.2.4 使用客户端库与 API 服务器交互
- Kubernetes API 服务器在 /swaggerapi 下暴露 Swagger API 定义,在 /swagger.json 下暴露 OpenAPI 定义。
- Kubernetes 不仅暴露了 Swagger API,同时也有与 API 服务器集成的 Swagger UI。Swagger UI 默认状态没有激活,可以通过使用 –enable-swagger-ui=true 选项运行 API 服务器对其进行激活。
- 在激活 UI 后,可以通过以下地址在浏览器中打开它: http(s)://
: /swagger-ui
9 Deployment: 声明式地升级应用
9.3.1 创建一个 Deployment
- 创建 Deployment 与创建 ReplicationController 并没有任何区别。 Deployment 也是由标签选择器、期望副数和 pod 模板组成的。此外,它还包含另一个字段,指定一个部署策略,该策略定义在修改 Deployment 资源时应该如何执行更新。
- Deployment 会创建多个 ReplicaSet,用来对应和管理一个版本的 pod 模板。像这样使用 pod 模板的哈希值,可以让 Deployment 始终对给定版本的 pod 模板创建相同的(或使用已有的) ReplicaSet。
9.3.2 升级 Deployment
- 使用 kubectl set image 命令来更改任何包含容器资源的镜像 ( ReplicationController、ReplicaSet、Deployment 等 )。
9.3.3 回滚 Deployment
- Deployment 可以非常容易地回滚到先前部署的版本,它可以让 Kubernetes 取消最后一次部署的 Deployment:
$ kubectl rollout undo deployment kubia deployment "kubia" rolled back - undo 命令也可以在滚动升级过程中运行,并直接停止滚动升级。在升级过程中已创建的 pod 会被删除并被老版本的 pod 替代。
- 显示Deployment的滚动升级历史:回滚升级之所以可以这么快地完成,是因为 Deployment 始终保持着升级的版本历史记录。之后也会看到,历史版本号会被保存在 ReplicaSet 中。滚动升级成功后,老版本的 ReplicaSet 也不会被删掉,这也使得回滚操作可以回滚到任何一个历史版本,而不仅仅是上一个版本。可以使用 kubectl rollout history 来显示升级的版本:
$ kubectl rollout history deployment kubia deployments "kubia": REVISION CHANGE-CAUSE 2 kubectl set image deployment kubia nodejs=luksa/kubia:v2 3 kubectl set image deployment kubia nodejs=luksa/kubia:v3 - 还记得创建 Deployment 时的 –record 参数吗?如果不给定这个参数,版本历史中的 CHANGE-CAUSE 这一栏会为空。这也会使用户很难辨别每次的版本做了哪些修改。
- 回滚到一个特定的 Deployment 版本:通过在 undo 命令中指定一个特定的版本号,便可以回滚到那个特定的版本。例如,如果想回滚到第一个版本,可以执行下述命令:
$ kubectl rollout undo deployment kubia --to-revision=1 - 由 Deployment 创建的所有 ReplicaSet 表示完整的修改版本历史,每个 ReplicaSet 都用特定的版本号来保存 Deployment 的完整信息,所以不应该手动删除 ReplicaSet。如果这么做便会丢失 Deployment 的历史版本记录而导致无法回滚。
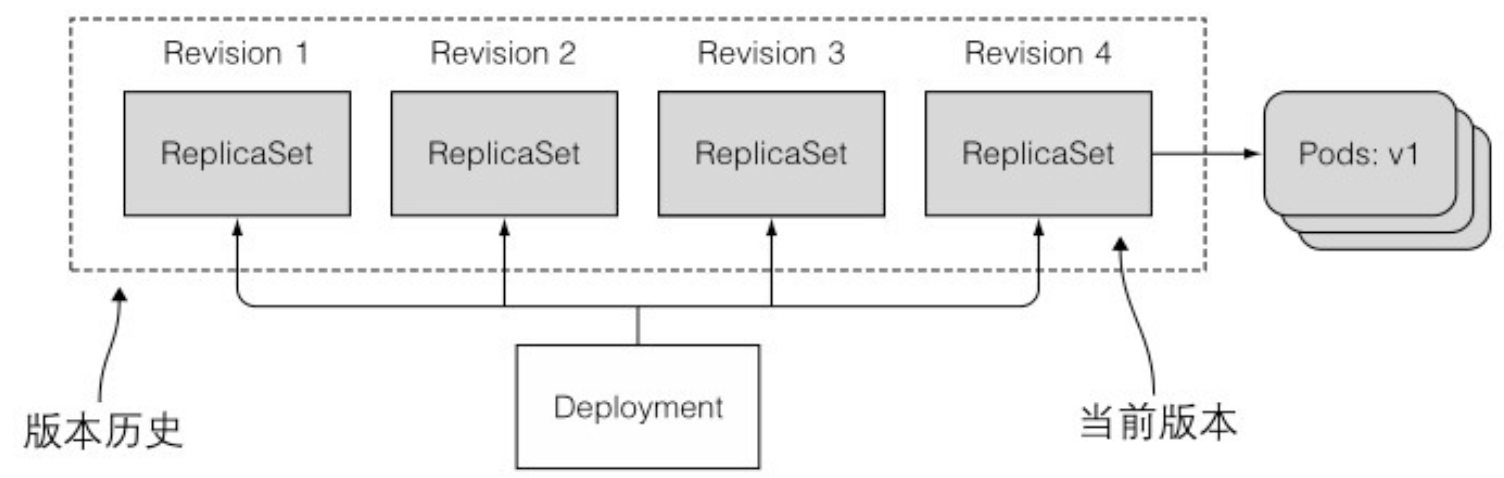
- 旧版本的 ReplicaSet 过多会导致 ReplicaSet 列表过于混乱,可以通过指定 Deployment 的 revisionHistoryLimit 属性来限制历史版本数量。
9.3.5 暂停滚动升级
$ kubectl set image deployment kubia nodejs=luksa/kubia:v4
deployment "kubia" image updated
$ kubectl rollout pause deployment kubia
deployment "kubia" paused- 一个新的 pod 会被创建,与此同时所有旧的 pod 还在运行。一旦新的 pod 成功运行,服务的一部分请求将被切换到新的 pod。这样相当于运行了一个金丝雀版本。
- 恢复滚动升级:
$ kubectl rollout resume deployment kubia deployment "kubia" resumed - 在滚动升级过程中,想要在一个确切的位置暂停滚动升级目前还无法做到,以后可能会有一种新的升级策略来自动完成上面的需求。但目前想要进行金丝雀发布的正确方式是,使用两个不同的 Deployment 并同时调整它们对应的 pod 数量。
- 使用暂停功能来停止滚动升级:暂停部署还可以用于阻止更新 Deployment 而自动触发的滚动升级过程,用户可以对 Deployment 进行多次更改,并在完成所有更改后才恢复滚动升级。一旦更改完毕,则恢复并启动滚动更新过程。
- 注意:如果部署被暂停,那么在恢复部署之前,撤销命令不会撤销它。
9.3.6 阻止出错版本的滚动升级
- minReadySeconds 属性指定新创建的 pod 至少要成功运行多久之后,才能将其视为可用。在 pod 可用之前,滚动升级的过程不会继续
- 使用 kubectl apply 更新 Deployment 时如果不期望副本数被更改,则不用在 YAML 文件中添加 replicas 这个字段。
- 如果只定义就绪探针没有正确设置 minReadySeconds,一旦有一次就绪探针调用成功,便会认为新的 pod 已经处于可用状态。因此最好适当地设置 minReadySeconds 的值。
10 StatefulSet: 部署有状态的多副本应用
10.2.2 提供稳定的网络标识
- 有状态的 pod 有时候需要通过其主机名来定位,因为它们都是彼此不同的 (比如拥有不同的状态),通常希望操作的是其中特定的一个。
- 基于以上原因,一个 Statefulset 通常要求你创建一个用来记录每个 pod 网络标记的 headless Service。通过这个 Service,每个 pod 将拥有独立的 DNS 记录,这样集群里它的伙伴或者客户端可以通过主机名方便地找到它。比如说,一个属于 default 命名空间,名为 foo 的控制服务,它的一个 pod 名称为 A-0,那么可以通过下面的完整域名来访问它: a-0.foo.default.svc.cluster.local。而在 ReplicaSet 中这样是行不通的。
- 另外,也可以通过 DNS 服务,查找域名 foo.default.svc.cluster.local 对应的所有 SRV 记录,获取一个 Statefulset 中所有 pod 的名称。
- Statefulset 缩容任何时候只会操作一个 pod 实例,所以有状态应用的缩容不会很迅速。
- Statefulset 在有实例不健康的情况下是不允许做缩容操作的。
10.3.2 通过 Statefulset 部署应用
- 特定的有状态应用集群在两个或多个集群成员同时启动时引起的竞态条件是非常敏感的,所以在每个成员完全启动后再启动剩下的会更加安全。
10.3.3 使用你的 pod
- 因为之前创建的 Service 处于 headless 模式,所以不能通过它来访问你的 pod。需要直接连接每个单独的 pod 来访问(或者创建一个普通的 Service,但是这样还是不允许你访问指定的 pod)。
- API 服务器的一个很有用的功能就是通过代理直接连接到指定的 pod。如果想请求当前的 kubia-0 pod,可以通过如下 URL:
: /api/v1/namespaces/default/pods/kubia-0/proxy/ - 如果你收到一个空的回应,请确保在 URL 的最后没有忘记输入 / 符号(或者用 curl 的 -L 选项来允许重定向)
- 代理请求到 Service 的 URL 路径格式如下: /api/v1/namespaces/
/services/ /proxy/
10.4 在 Statefulset 中发现伙伴节点
- DNS 记录里还有其他一些不是那么知名的类型,SRV 记录就是其中的一个。
- SRV 记录用来指向提供指定服务的服务器的主机名和端口号。
- 当一个 pod 要获取一个 Statefulset 里的其他 pod 列表时,你需要做的就是触发一次 SRV DNS 查询。例如,在 Node.js 中查询命令为:
dns.resolveSrv("kubia.default.svc.cluster.local", callBackFunction);
10.5.2 手动删除 pod
- 除非你确认节点不再运行或者不会再可以访问(永远不会再可以访问),否则不要强制删除有状态的 pod。
11 了解 Kubernetes 机理
11.1.1 Kubernetes 组件的分布式特性
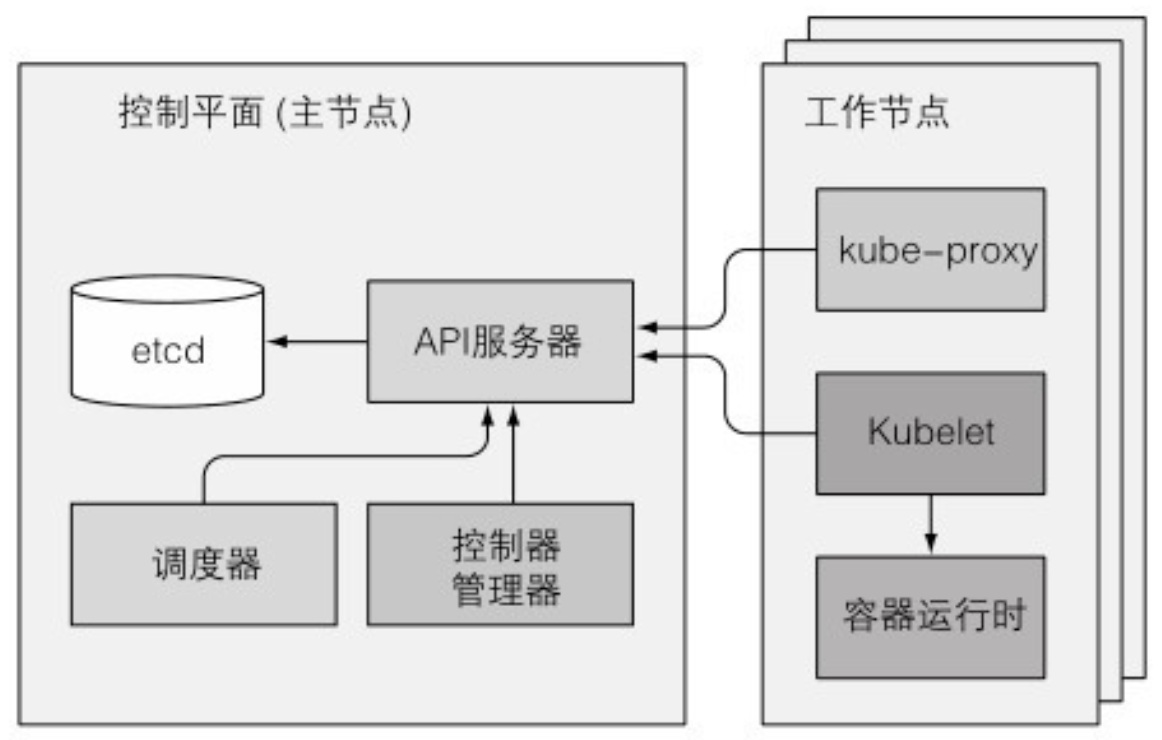
- API 服务器对外暴露了一个名为 ComponentStatus 的 API 资源,用来显示每个控制平面组件的健康状态。可以通过 kubectl 列出各个组件以及它们的状态:
$ kubectl get componentstatuses NAME STATUS MESSAGE ERROR scheduler Healthy ok controller-manager Healthy ok etcd-0 Healthy {"health": "true"} - Kubernetes 系统组件间只能通过 API 服务器通信,它们之间不会直接通信。
- kubectl attach 命令和 kubectl exec 命令类似,区别是:前者会附属到容器中运行着的主进程上,而后者是重新运行一个进程。
- 尽管工作节点上的组件都需要运行在同一个节点上,控制平面的组件可以被简单地分割在多台服务器上。为了保证高可用性,控制平面的每个组件可以有多个实例。etcd 和 API 服务器的多个实例可以同时并行工作,但是,调度器和控制器管理器在给定时间内只能有一个实例起作用,其他实例处于待命模式。
- Kubelet 是唯一一直作为常规系统组件来运行的组件,它把其他组件作为 pod 来运行。为了将控制平面作为 pod 来运行,Kubelet 被部署在 master 上。
11.1.2 Kubernetes 如何使用 etcd
- 乐观并发控制(有时候指乐观锁)是指一段数据包含一个版本数字,而不是锁住该段数据并阻止读写操作。每当更新数据,版本数就会增加。当更新数据时,就会检查版本值是否在客户端读取数据时间和提交时间之间被增加过。如果增加过,那么更新会被拒绝,客户端必须重新读取新数据,重新尝试更新。
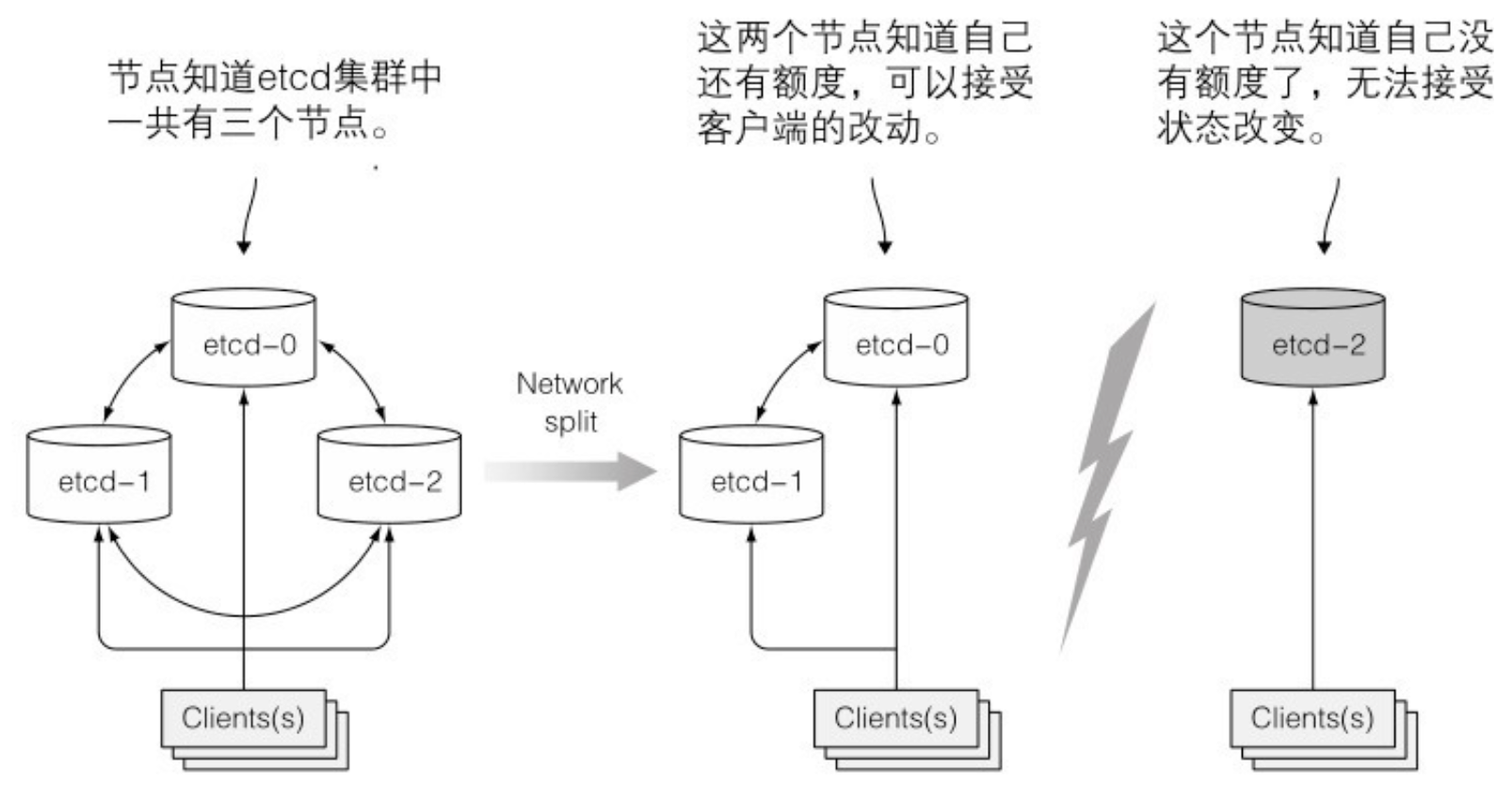
- etcd 使用 RAFT 一致性算法来保证这一点,确保在任何时间点,每个节点的状态要么是大部分节点的当前状态,要么是之前确认过的状态。
- 一致性算法要求集群大部分(法定数量)节点参与才能进行到下一个状态。结果就是,如果集群分裂为两个不互联的节点组,两个组的状态不可能不一致,因为要从之前状态变化到新状态,需要有过半的节点参与状态变更。如果一个组包含了大部分节点,那么另外一组只有少量节点成员。第一个组就可以更改集群状态,后者则不可以。当两个组重新恢复连接,第二个组的节点会更新为第一个组的节点的状态。
- 在脑裂场景中,只有拥有大部分(法定数量)节点的组会接受状态变更
11.1.5 了解调度器
- 可以在集群中运行多个调度器而非单个。然后,对每一个 pod,可以通过在 pod 特性中设置 schedulerName 属性指定调度器来调度特定的 pod。
11.1.6 介绍控制器管理器中运行的控制器
- 资源描述了集群中应该运行什么,而控制器就是活跃的 Kubernetes 组件,去做具体工作部署资源。
- 总的来说,控制器执行一个“调和”循环,将实际状态调整为期望状态(在资源 spec 部分定义),然后将新的实际状态写入资源的 status 部分。控制器利用监听机制来订阅变更,但是由于使用监听机制并不保证控制器不会漏掉时间,所以仍然需要定期执行重列举操作来确保不会丢掉什么。
11.1.9 介绍 Kubernetes 插件
- DNS 服务 pod 通过 kube-dns 服务对外暴露,使得该 pod 能够像其他 pod 一样在集群中移动。服务的 IP 地址在集群每个容器的 /etc/reslv.conf 文件的 nameserver 中定义。kube-dns pod 利用 API 服务器的监控机制来订阅 Service 和 Endpoint 的变动,以及 DNS 记录的变更,使得其客户端(相对地)总是能够获取到最新的 DNS 信息。客观地说,在 Service 和 Endpoint 资源发生变化到 DNS pod 收到订阅通知时间点之间,DNS 记录可能会无效。
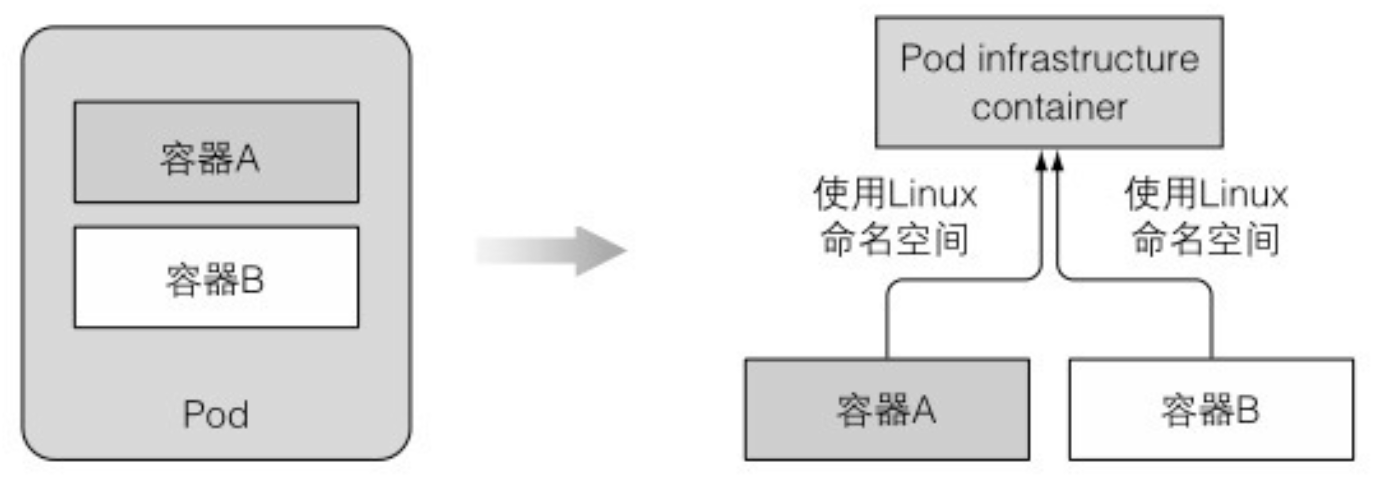
11.3 了解运行中的pod是什么
- 被暂停的容器将一个 pod 所有的容器收纳到一起。暂停的容器是一个基础容器,它的唯一目的就是保存所有的命名空间。所有 pod 的其他用户定义容器使用 pod 的该基础容器的命名空间
- 一个双容器 pod 有 3 个运行的容器,共享同一个 Linux 命名空间
11.4.2 深入了解网络工作原理
- 为了让不同节点上的 pod 能够通信,网桥需要以某种方式连接
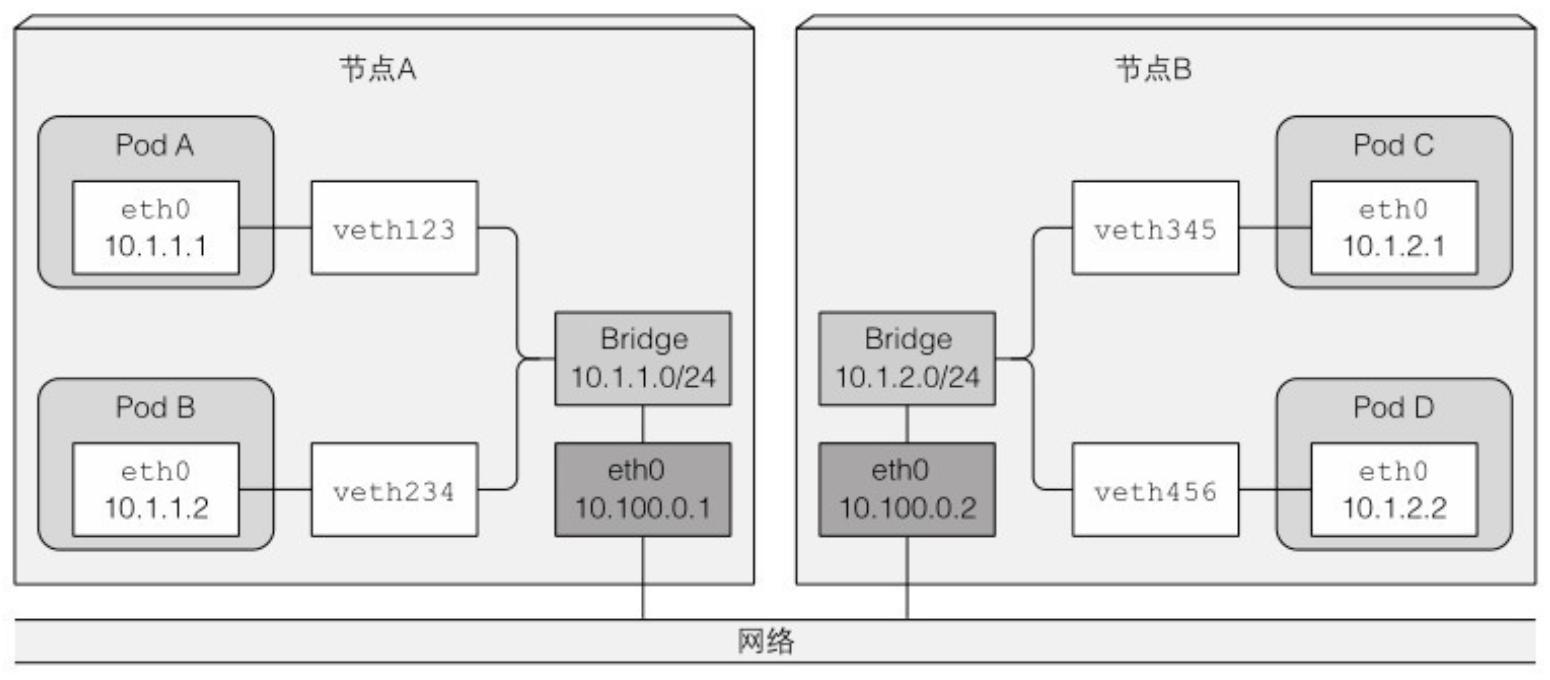
- 按照该配置,当报文从一个节点上容器发送到其他节点上的容器,报文先通过 veth pair,通过网桥到节点物理适配器,然后通过网线传到其他节点的物理适配器,再通过其他节点的网桥,最终经过 veth pair 到达目标容器。
- 仅当节点连接到相同网关、之间没有任何路由时上述方案有效。否则,路由器会扔包因为它们所涉及的 pod IP 是私有的。
- 使用 SDN (软件定义网络)技术可以简化问题,SDN 可以让节点忽略底层网络拓扑,无论多复杂,结果就像连接到同一个网关上。从 pod 发出的报文会被封装,通过网络发送给运行其他 pod 的网络,然后被解封装、以原始格式传递给 pod。
11.5.1 引入 kube-proxy
- 和 Service 相关的任何事情都由每个节点上运行的 kube-proxy 进程处理。开始的时候,kube-proxy 确实是一个 proxy,等待连接,对每个进来的连接,连接到一个 pod。这称为 userspace(用户空间) 代理模式。 后来,性能更好的 iptables 代理模式取代了它。iptables 代理模式目前是默认的模式,如果你有需要也仍然可以配置 Kubernetes 使用旧模式。
- 发送到服务虚拟 IP / 端口对的网络包会被修改、重定向到一个随机选择的后端 pod
11.6.2 让 Kubernetes 控制平面变得高可用
- 三节点高可用集群
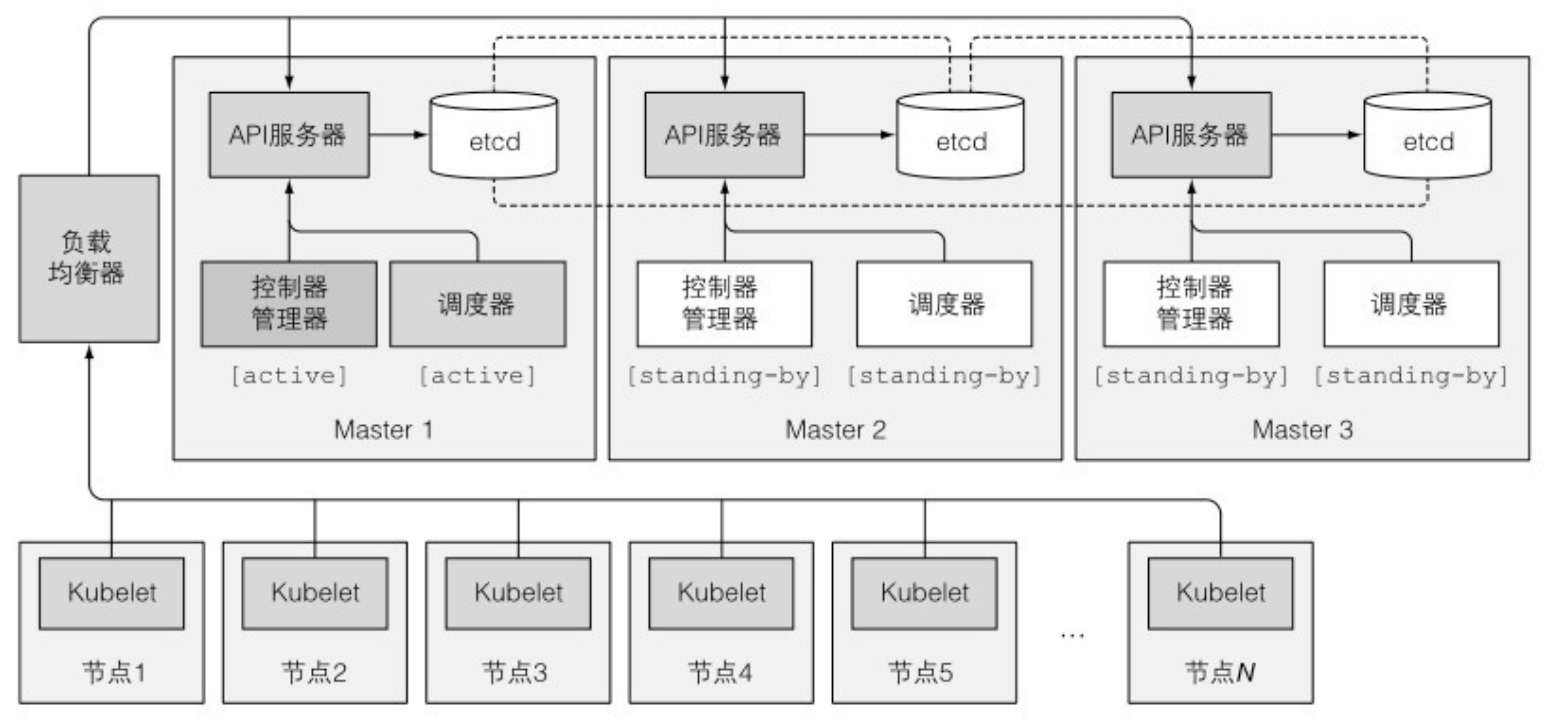
- 运行 etcd 集群:拥有超过 7 个实例基本上没有必要,并且会影响性能。
- 通常,一个 API 服务器会和每个 etcd 实例搭配。这样做,etcd 实例之前就不需要任何负载均衡器,因为每个 API 服务器只和本地 etcd 实例通信。
- 只有一个控制器管理器和一个调度器有效;其他的待机
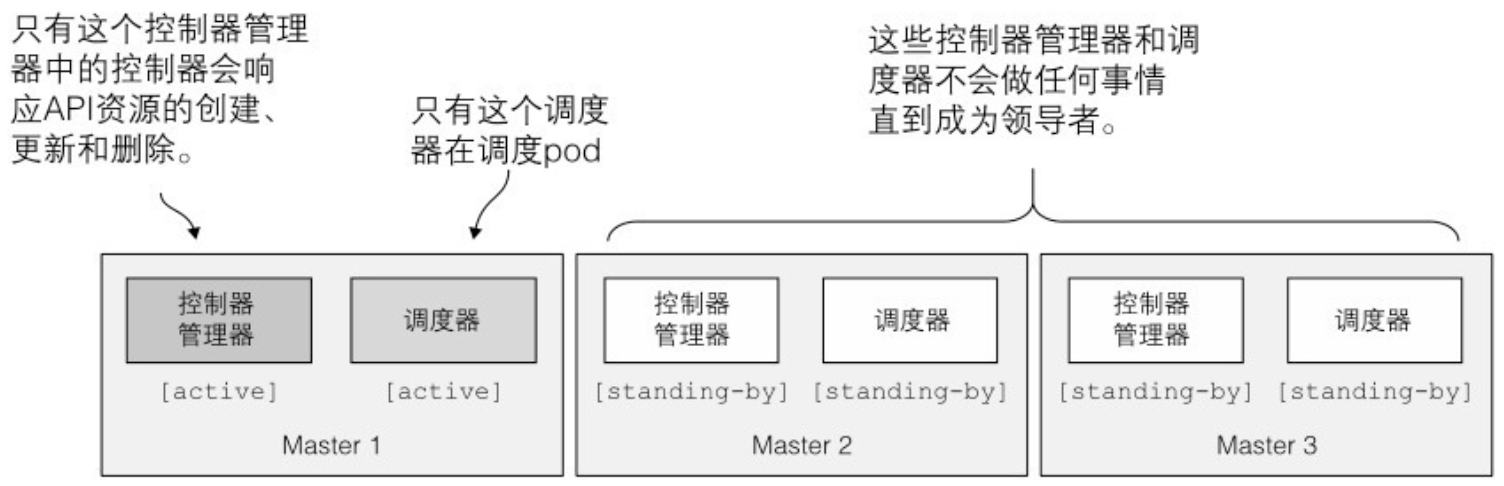
- 控制平面组件使用的领导选举机制:最有趣的是:选举领导时这些组件不需要互相通信。领导选举机制的实现方式是在 API 服务器中创建一个资源
$ kubectl get endpoints kube-scheduler -n kube-system -o yaml apiVersion: v1 kind: Endpoints metadata: annotations: control-plane.alpha.kubernetes.io/leader: '{"holderIdentity": "minikube", "leaseDurationSeconds": 15, "acquireTime": " 2017-05-27T18:54:53Z", "renewTime": "2017-05-28T13:07:49Z", "leaderTransitions": 0}' creationTimestamp: 2017-05-27T18:54:53Z name: kube-scheduler namespace: kube-system resourceVersion: "654059" selfLink: /api/v1/namespaces/kube-system/endpoints/kube-scheduler uid: f847bd14-430d-11e7-9720-080027f8fa4e subsets: [] - control-plane.alpha.kubernetes.io/leader 注释是比较重要的部分。其中包含了一个叫作 holderIdentity 的字段,包含了当前领导者的名字。第一个成功将姓名填入该字段的实例成为领导者。实例之间会竞争,但是最终只有一个胜出。
- 乐观并发保证如果有多个实例尝试写名字到资源,只有一个会成功。根据是否写成功,每个实例就知道自己是否是领导者。
12 Kubernetes API 服务器的安全防护
12.1.2 ServiceAccount 介绍
- pod 只能使用同一个命名空间中的 ServiceAccount。
12.1.3 创建 ServiceAccount
- 在默认情况下,pod 可以挂载任何它需要的密钥。但是我们可以通过对 ServiceAccount 进行配置,让 pod 只允许挂载 ServiceAccount 中列出的可挂载密钥。为了开启这个功能,ServiceAccount 必须包含以下注解: kubernetes.io/enforce-mountable-secrets=ʺtrueʺ。
- 如果 ServiceAccount 被加上了这个注解,任何使用这个 ServiceAccount 的 pod 只能挂载进 ServiceAccount 的可挂载密钥 —— 这些 pod 不能使用其他的密钥。
- ServiceAccount 的镜像拉取密钥和它的可挂载密钥表现有些轻微不同。和可挂载密钥不同的是,ServiceAccount 中的镜像拉取密钥不是用来确定一个 pod 可以使用哪些镜像拉取密钥的。添加到 ServiceAccount 中的镜像拉取密钥会自动添加到所有使用这个 ServiceAccount 的 pod 中。向 ServiceAccount 中添加镜像拉取密钥可以不必对每个 pod 都单独进行镜像拉取密钥的添加操作。
12.1.4 将 ServiceAccount 分配给 pod
- pod 的 ServiceAccount 必须在 pod 创建时进行设置,后续不能被修改。
12.2.2 介绍 RBAC 资源
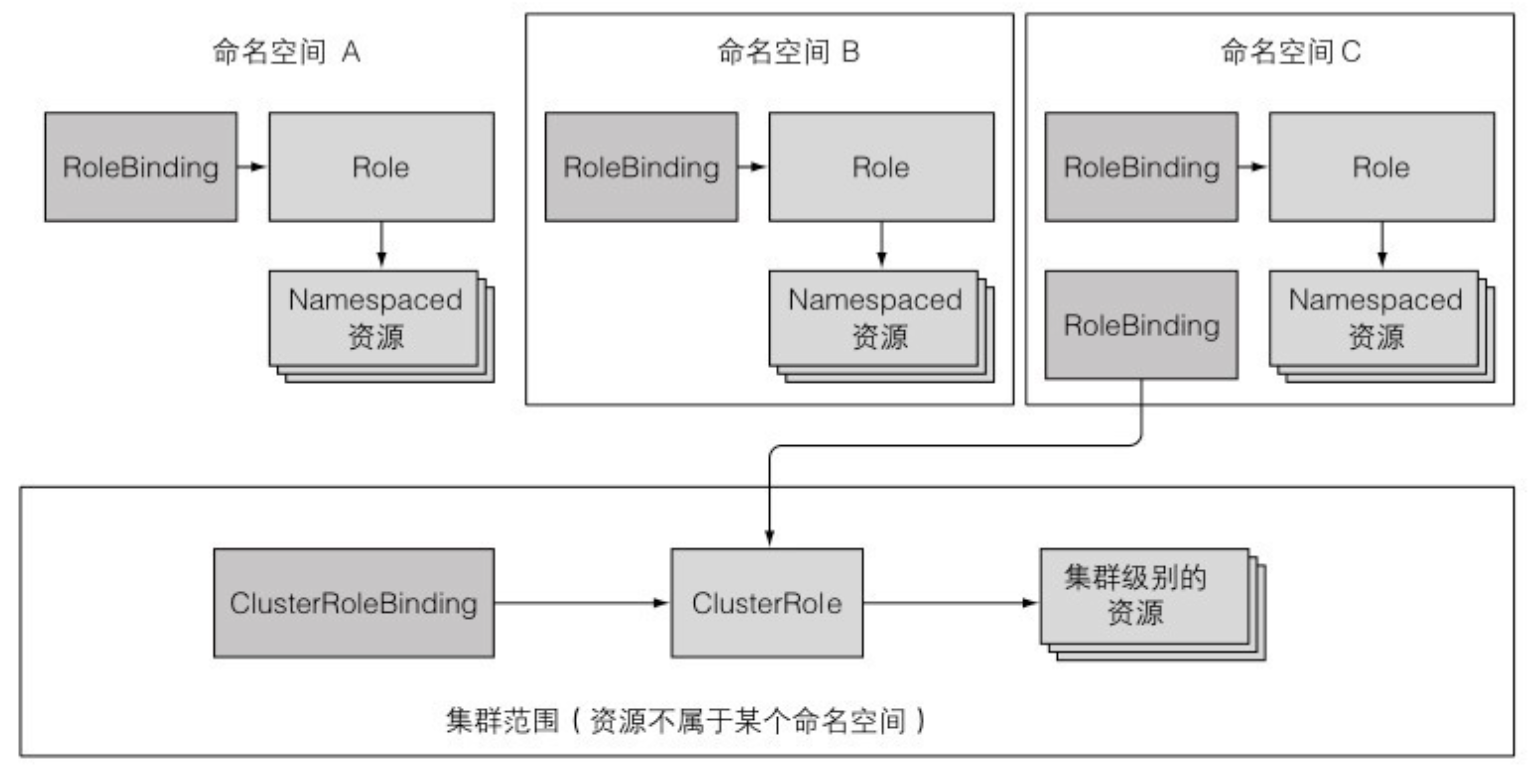
- Role 和 RoleBinding 都在命名空间中,ClusterRole 和 ClusterRoleBinding 不在命名空间中
12.2.3 使用 Role 和 RoleBinding
- RoleBinding 将来自不同命名空间中的 ServiceAccount 绑定到同一个 Role
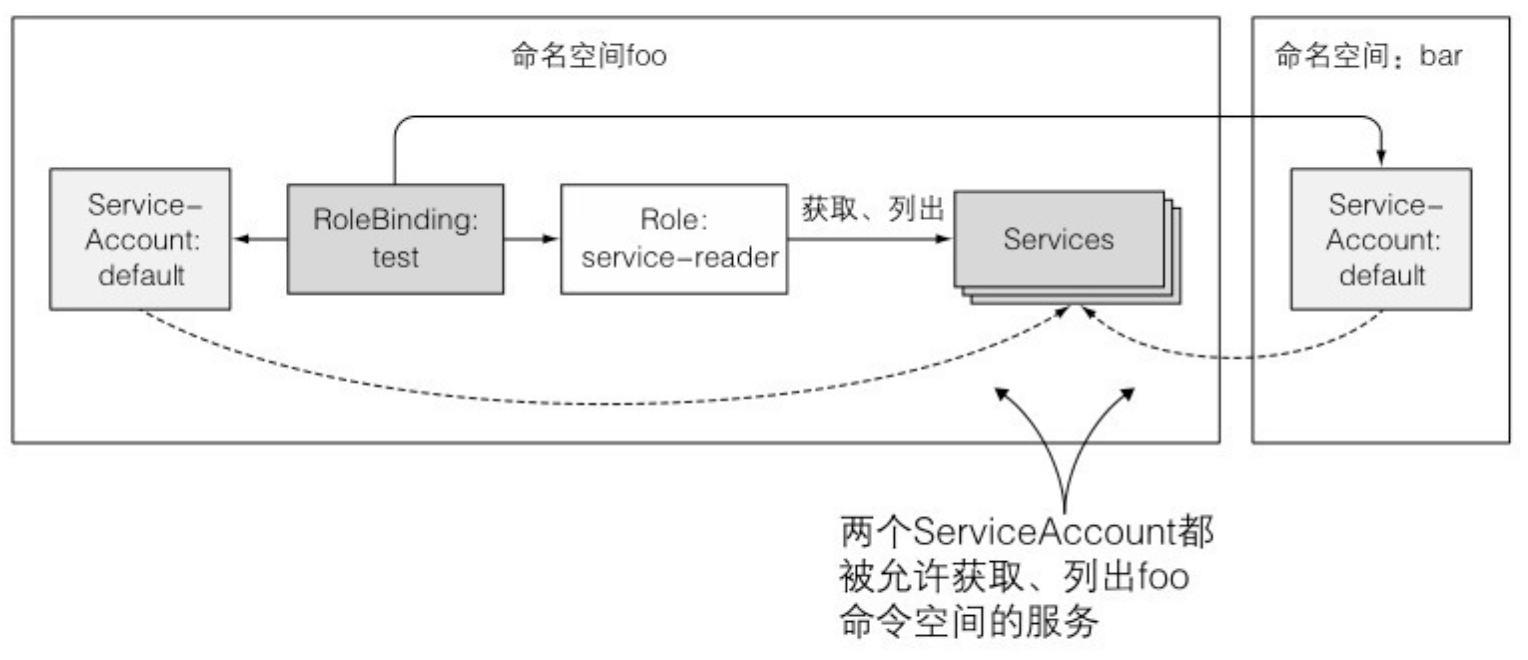
12.2.4 使用 ClusterRole 和 ClusterRoleBinding
- 尽管你可以创建一个 RoleBinding 并在你想开启命名空间资源的访问时引用一个 ClusterRole,但是不能对集群级别(没有命名空间的)资源使用相同的方法。必须始终使用 ClusterRoleBinding 来对集群级别的资源进行授权访问。
- ClusterRoleBinding 和 ClusterRole 必须一起使用授予集群级别的资源的权限
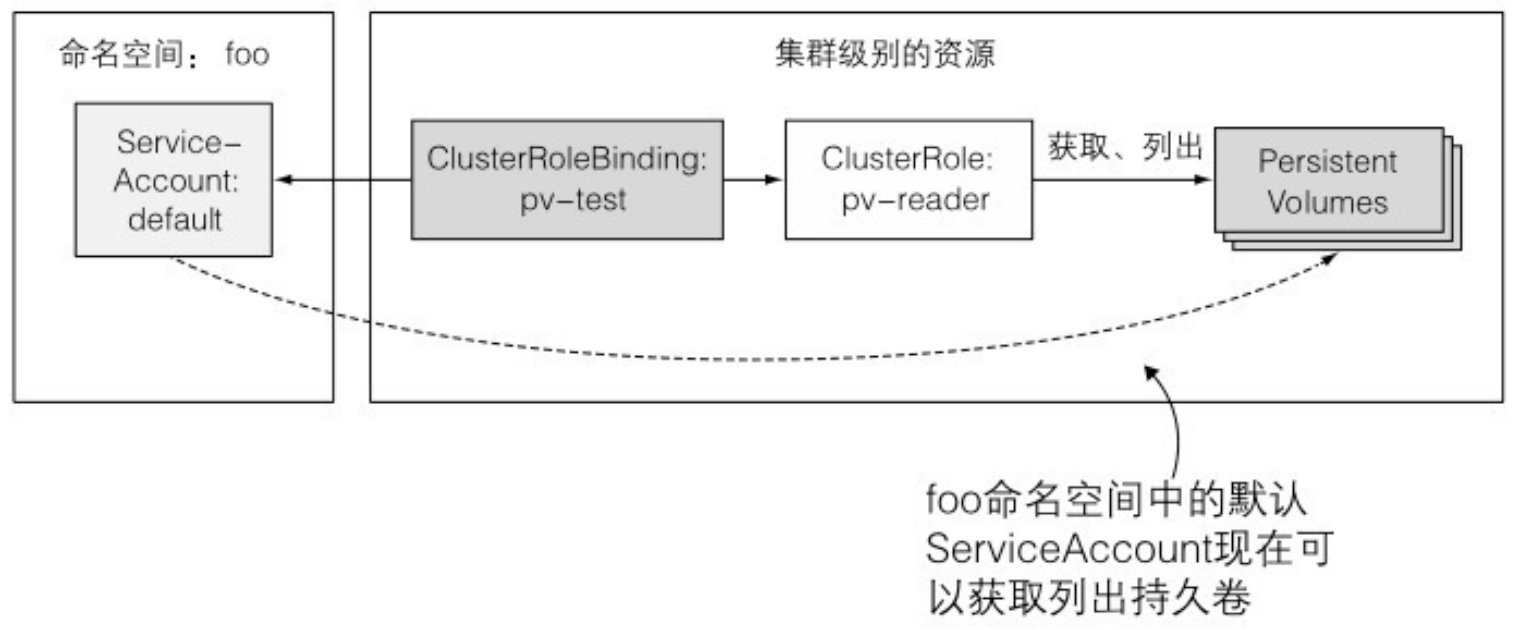
- 记住一个 RoleBinding 不能授予集群级别的资源访问权限,即使它引用了一个 ClusterRoleBinding。
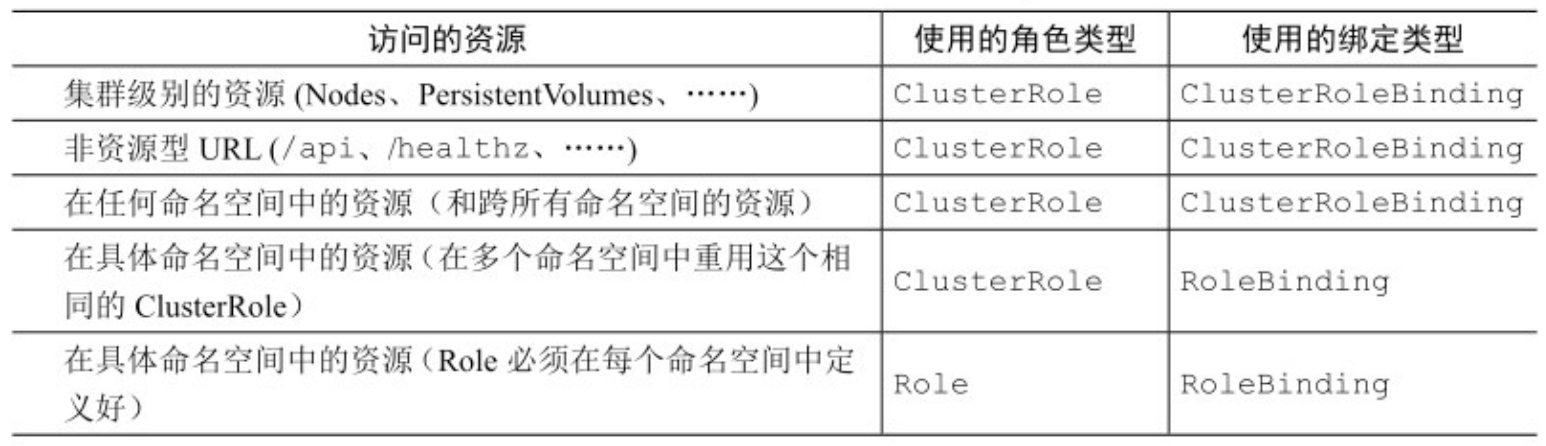
- ClusterRole 不是必须一直和集群级别的 ClusterRoleBinding 捆绑使用。它们也可以和常规的有命名空间的 RoleBinding 进行捆绑。
- 如果你创建了一个 ClusterRoleBinding 并在它里面引用了 ClusterRole,在绑定中列出的主体可以在所有命名空间中查看指定的资源。相反,如果你创建的是一个 RoleBinding,那么在绑定中列出的主体只能查看在 RoleBinding 命名空间中的资源。
- 何时使用具体的 role 和 binding 的组合
12.3 本章小结
- 一个 ServiceAccount 也可以用来给 pod 添加镜像拉取密钥,因此你就不需要在每个 pod 里指定密钥了。
13 保障集群内节点和网络安全
13.1 在 pod 中使用宿主节点的 Linux 命名空间
- pod 中的容器通常在分开的 Linux 命名空间中运行。这些命名空间将容器中的进程与其他容器中,或者宿主机默认命名空间中的进程隔离开来。
- 例如,每一个 pod 有自己的 IP 和端口空间,这是因为它拥有自己的网络命名空间。类似地,每一个 pod 拥有自己的进程树,因为它有自己的 PID 命名空间。同样地,pod 拥有自己的 IPC 命名空间,仅允许同一 pod 内的进程通过进程间通信 (Inter Process Communication,简称 IPC) 机制进行交流。
13.1.3 使用宿主节点的 PID 与 IPC 命名空间
- pod spec 中的 hostPID 和 hostIPC 选项与 hostNetwork 相似。当它们被设置为 true 时,pod 中的容器会使用宿主节点的 PID 和 IPC 命名空间,分别允许它们看到宿主机上的全部进程,或通过 IPC 机制与它们通信。
13.2.1 使用指定用户运行容器
- 你需要指明一个用户 ID,而不是用户名(id 405 对应 guest 用户)
apiVersion: v1 kind: Pod metadata: name: pod-as-user-guest spec: containers: - name: main image: alpine command: ["/bin/sleep", "999999"] securityContext: runAsUser: 405
13.2.4 为容器单独添加内核功能
- Linux 内核功能的名称通常以 CAP_ 开头。但在 pod spec 中指定 内核功能时,必须省略 CAP_ 前缀。
13.2.6 阻止对容器根文件系统的写入
- 如果容器的根文件系统是只读的,你很可能需要为应用会写入的每一个目录(如日志、磁盘缓存等)挂载存储卷。
- 为了增强安全性,请将在生产环境运行的容器的 readOnlyRootFilesystem 选项设置为 true。
- 以上的例子都是对单独的容器设置安全上下文。这些选项中的一部分也可以从 pod 级别设定 (通过 pod.spec.securityContext 属性)。它们会作为 pod 中每一个容器的默认安全上下文,但是会被容器级别的安全上下文覆盖。
13.2.7 容器使用不同用户运行时共享存储卷
- Kubernetes 允许为 pod 中所有容器指定 supplemental 组,以允许它们无论以哪个用户 ID 运行都可以共享文件。这可以通过以下两个属性设置: fsGroup、supplementalGroups
13.3.5 对不同的用户与组分配不同的 PodSecurityPolicy
- 对不同用户分配不同 PodSecurityPolicy 是通过前一章中描述的 RBAC 机制实现的。这个方法是,创建你需要的 PodSecurityPolicy 资源,然后创建 ClusterRole 资源并通过名称将它们指向不同的策略,以此使 PodSecurityPolicy 资源中的策略对不同的用户或组生效。通过 ClusterRoleBinding 资源将特定的用户或组绑定到 ClusterRole 上,当 PodSecurityPolicy 访问控制插件需要决定是否接纳一个 pod 时,它只会考虑创建 pod 的用户可以访问到的 PodSecurityPolicy 中的策略。
- 用 kubectl 的 config 子命令创建用户:
$ kubectl config set-credentials alice --username=alice --password=password User "alice" set. - 可以通过 –user 选项向 kubectl 传达你使用的用户凭据:
$ kubectl --user alice create -f pod-privileged.yaml
13.4 隔离 pod 的网络
- 无类别域间路由(Classless Inter-Domain Routing,CIDR)
13.4.4 使用 CIDR 隔离网络
- 除了通过在 pod 选择器或命名空间选择器定义哪些 pod 可以访问 NetworkPolicy 资源中指定的目标 pod,还可以通过 CIDR 表示法指定一个 IP 段。
ingress:
- from:
- ipBlock:
cidr: 192.168.1.0/24- 这条入向规则来自 192.168.1.0/24 IP 段的客户端的流量
13.4.5 限制 pod 的对外访问流量
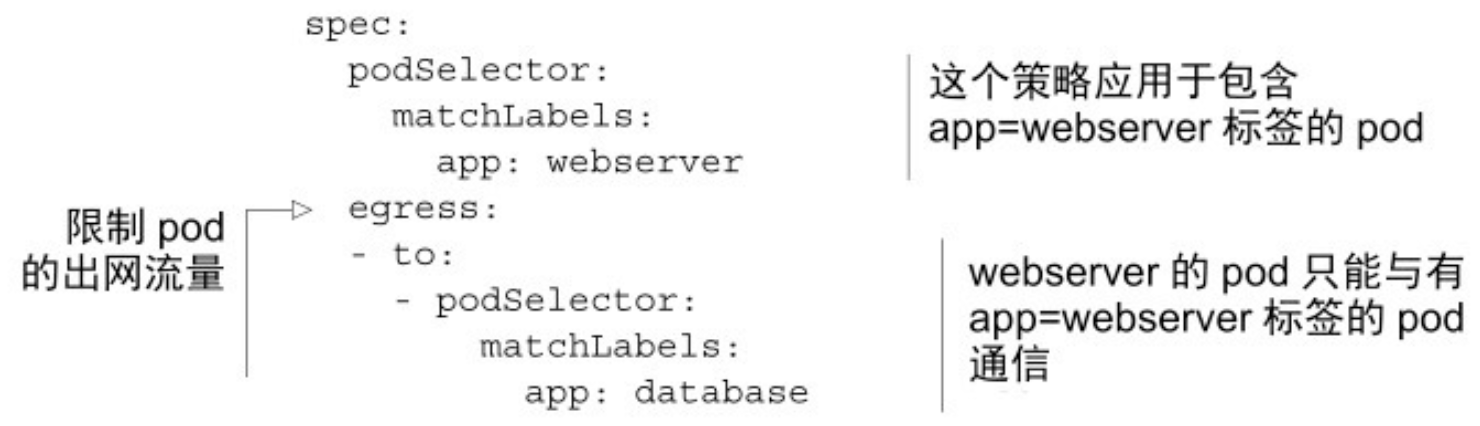
- 以上的 NetworkPolicy 仅允许具有标签 app=webserver 的 pod 访问具有标签 app=database 的 pod,除此之外不能访问任何地址(不论是其他 pod,还是任何其他的 IP,无论在集群内部还是外部)。
14 计算资源管理
14.1.3 CPU requests 如何影响 CPU 时间分配
- 未使用的 CPU 时间按照 CPU requests 在容器之间分配
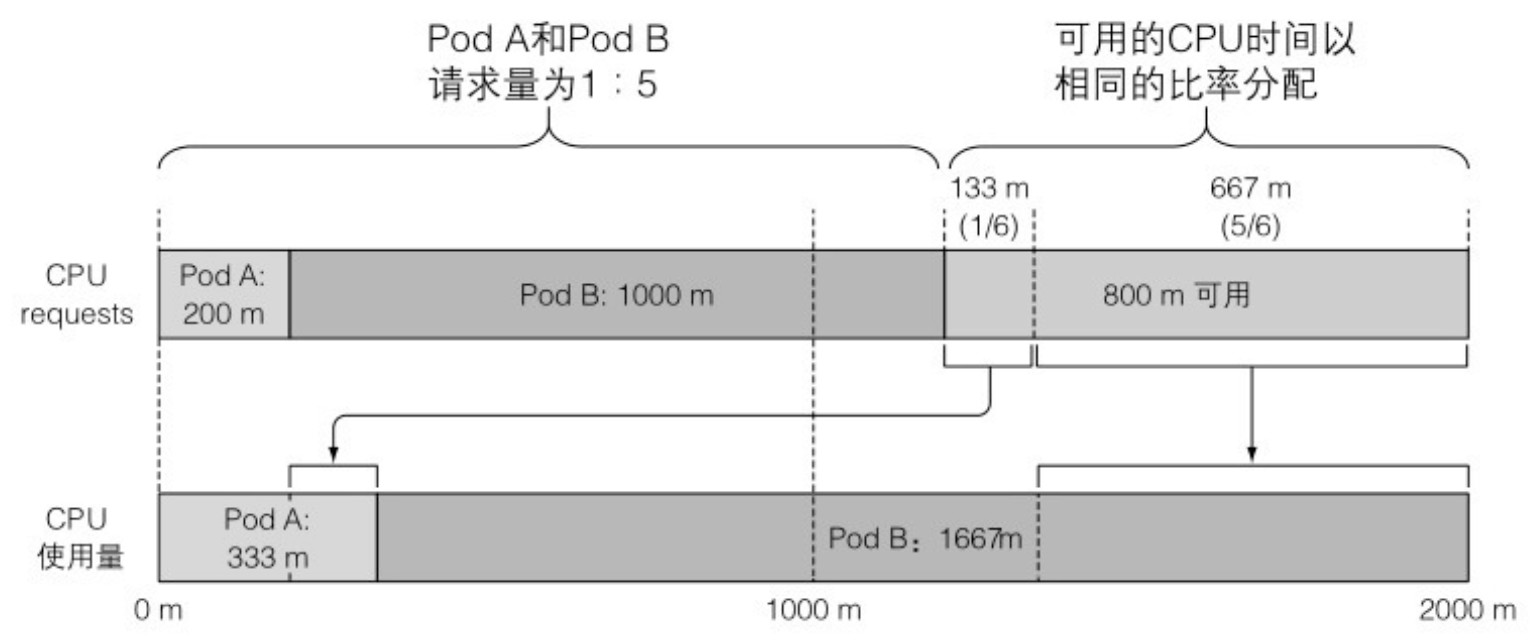
- 另一方面,如果一个容器能够跑满 CPU,而另一个容器在该时段处于空闲状态,那么前者将可以使用整个 CPU 时间(当然会减掉第二个容器消耗的少量时间)。毕竟当没有其他人使用时提高整个 CPU 的利用率也是有意义的,对吧?当然,第二个容器需要 CPU 时间的时候就会获取到,同时第一个容器会被限制回来。
14.2.1 设置容器可使用资源量的硬限制
- CPU 是一种可压缩资源,意味着我们可以在不对容器内运行的进程产生不利影响的同时,对其使用量进行限制。而内存明显不同 —— 是一种不可压缩资源。一旦系统为进程分配了一块内存,这块内存在进程主动释放之前将无法被回收。这就是我们为什么需要限制容器的最大内存分配量的根本原因。
- 可超卖的 limits:与资源 requests 不同的是,资源 limits 不受节点可分配资源量的约束。所有 limits 的总和允许超过节点资源总量的 100%。换句话说,资源 limits 可以超卖。如果节点资源使用量超过 100%,一些容器将被杀掉,这是一个很重要的结果。
14.2.2 超过 limits
- 当进程尝试申请分配比限额更多的内存时会被杀掉(我们会说这个容器被 OOMKilled 了,OOM 是Out Of Memory 的缩写)。如果 pod 的重启策略为 Always 或 OnFailure,进程将会立即重启,因此用户可能根本察觉不到它被杀掉。但是如果它继续超限并被杀死,Kubernetes 会再次尝试重启,并开始增加下次重启的间隔时间。这种情况下用户会看到 pod 处于 CrashLoopBackOff 状态:
$ kubectl get po NAME READY STATUS RESTARTS AGE memoryhog 0/1 CrashLoopBackOff 3 1m - CrashLoopBackOff 状态表示 Kubelet 还没有放弃,它意味着在每次崩溃之后,Kubelet 就会增加下次重启之前的间隔时间。第一次崩溃之后,Kubelet 立即重启容器,如果容器再次崩溃,Kubelet 会等待 10 秒钟 后再重启。随着不断崩溃,延迟时间也会按照 20、40、80、160 秒以几何倍数增长,最终收敛在 300 秒。一旦间隔时间达到 300 秒, Kubelet 将以 5 分钟为间隔时间对容器进行无限重启,直到容器正常运行或被删除。
14.2.3 容器中的应用如何看待 limits
- 在容器内看到的始终是节点的内存,而不是容器本身的内存
- 不要依赖应用程序从系统获取的 CPU 数量,你可能需要使用 Downward API 将 CPU 限额传递至容器并使用这个值。也可以通过 cgroup 系统直接获取配置的 CPU 限制,请查看下面的文件:
/sys/fs/cgroup/cpu/cpu.cfs_quota_us /sys/fs/cgroup/cpu/cpu.cfs_period_us
14.3 了解 pod QoS 等级
- Kubernetes 将 pod 划分为 3 种 QoS 等级: BestEffort(优先级最低)、Burstable、Guaranteed(优先级最高)
14.3.1 定义 pod 的 QoS 等级
- 最低优先级的 QoS 等级是 BestEffort。会分配给那些没有(为任何容器)设置任何 requests 和 limits 的 pod。前面章节创建的 pod 都是这个等级。在这个等级运行的容器没有任何资源保证。在最坏情况下,它们分不到任何 CPU 时间,同时在需要为其他 pod 释放内存时,这些容器会第一批被杀死。不过因为 BestEffort pod 没有配置内存 limits,当有充足的可用内存时,这些容器可以使用任意多的内存。
- 对于一个 Guaranteed 级别的 pod,有以下几个条件:1. CPU 和内存都要设置 requests 和 limits;2. 每个容器都需要设置资源量;3. 它们必须相等(每个容器的每种资源的 requests 和 limits 必须相等)
- 因为如果容器的资源 requests 没有显式设置,默认与 limits 相同,所以只设置所有资源( pod 内每个容器的每种资源)的限制量就可以使 pod 的 QoS 等级为 Guaranteed。这些 pod 的容器可以使用它所申请的等额资源,但是无法消耗更多的资源(因为它们的 limits 和 requests 相等)。
- Burstable QoS 等级介于 BestEffort 和 Guaranteed 之间。其他所有的 pod 都属于这个等级。
- Burstable pod 可以获得它们所申请的等额资源,并可以使用额外的资源(不超过 limits )。
- 基于资源请求量和限制量的单容器 pod 的 QoS 等级
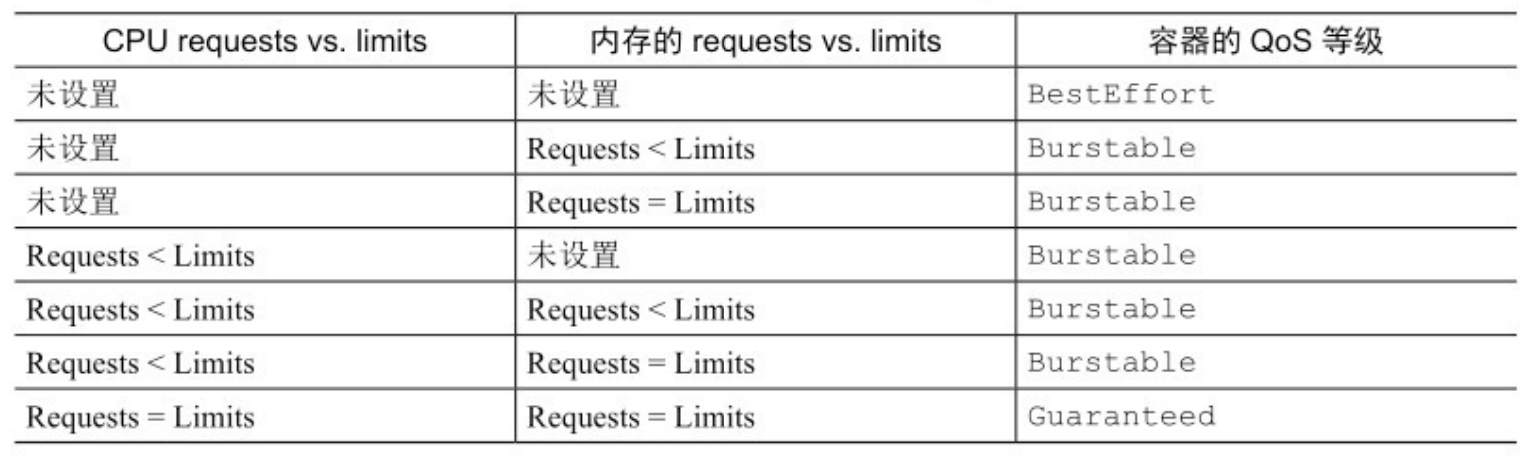
- 注意:如果设置了 requests 而没有设置 limits,参考表中 requests 小于 limits 那一行。如果设置了 limits, requests 默认与 limits 相等,因此参考 request 等于 limits 那一行。
- 对于多容器 pod,如果所有的容器的 QoS 等级相同,那么这个等级就是 pod 的 QoS 等级。如果至少有一个容器的 QoS 等级与其他不同,无论这个容器是什么等级,这个 pod 的 QoS 等级都是 Burstable 等级。
- 由容器的 QoS 等级推导出 pod 的 QoS 等级
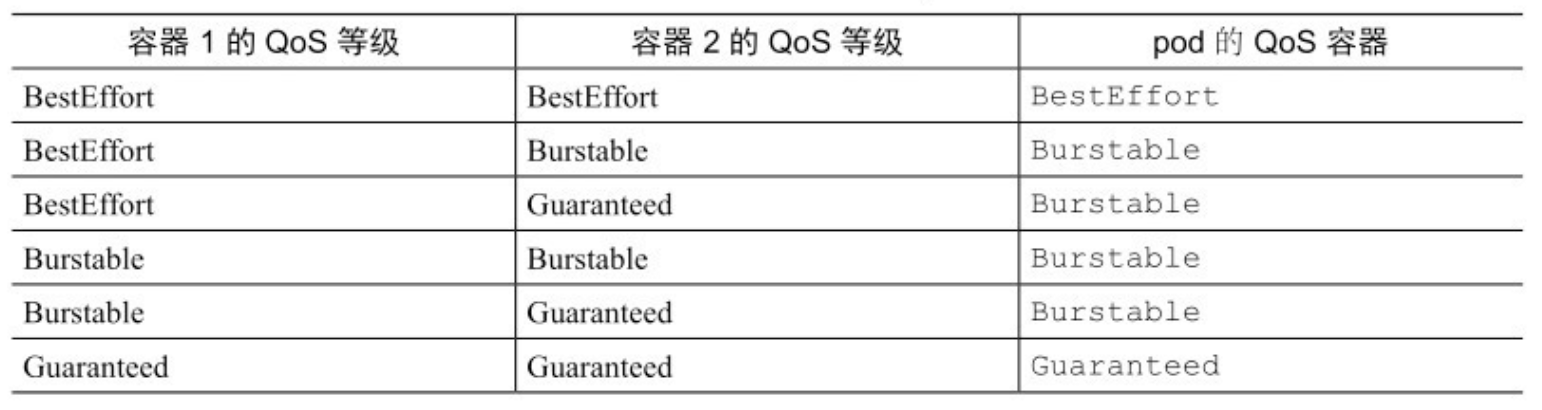
- 运行 kubectl describe pod 以及通过 pod 的 YAML / JSON 描述的 status.qosClass 字段都可以查看 pod 的 QoS 等级。
14.3.2 内存不足时哪个进程会被杀死
- BestEffort 等级的 pod 首先被杀掉,其次是 Burstable pod,最后是 Guaranteed pod。Guaranteed pod 只有在系统进程需要内存时才会被杀掉。
- 每个运行中的进程都有一个称为 OutOfMemory(OOM) 分数的值。系统通过比较所有运行进程的 OOM 分数来选择要杀掉的进程。当需要释放内存时,分数最高的进程将被杀死。
- OOM 分数由两个参数计算得出: 进程已消耗内存占可用内存的百分比,与一个基于 pod QoS 等级和容器内存申请量固定的 OOM 分数调节因子。对于两个属于 Burstable 等级的单容器的 pod,系统会杀掉内存实际使用量占内存申请量比例更高的 pod。
14.5.1 ResourceQuota 资源介绍
- 可以执行 kubectl describe 命令查看当前配额已经使用了多少:
$ kubectl describe quota
Name: cpu-and-mem
Namespace: default
Resource Used Hard
-------- ---- ----
limits.cpu 200m 600m
limits.memory 100Mi 500Mi
requests.cpu 100m 400m
requests.memory 10Mi 200Mi- 当特定资源( CPU 或内存)配置了( requests 或 limits )配额,在 pod 中必须为这些资源(分别)指定 requests 或 limits,否则 API 服务器不会接收该 pod 的创建请求。
15 自动横向伸缩 pod 与集群节点
15.1.2 基于 CPU 使用率进行自动伸缩
- 一定要确保自动伸缩的目标是 Deployment 而不是底层的 ReplicaSet。这样才能确保预期的副本数量在应用更新后继续保持(记着 Deployment 会给每个应用版本创建一个新的 ReplicaSet)。手动伸缩也是同样的道理。
- Autoscaler 在单次扩容操作中可增加的副本数受到限制。如果当前副本数大于 2, Autoscaler 单次操作至多使副本数翻倍; 如果副本数只有 1 或 2, Autoscaler 最多扩容到 4 个副本。
- 另外,Autoscaler 两次扩容操作之间的时间间隔也有限制。目前,只有当 3 分钟内没有任何伸缩操作时才会触发扩容,缩容操作频率更低 —— 5分钟。
15.1.3 基于内存使用进行自动伸缩
- 基于内存的自动伸缩比基于 CPU 的困难很多。主要原因在于,扩容之后原有的 pod 需要有办法释放内存。这只能由应用完成,系统无法代劳。系统所能做的只有杀死并重启应用,希望它能比之前少占用一些内存; 但如果应用使用了跟之前一样多的内存,Autoscaler 就会扩容、扩容,再扩容,直到达到 HPA 资源上配置的最大 pod 数量。显然没有人想要这种行为。
15.3.3 限制集群缩容时的服务干扰
- 一些服务要求至少保持一定数量的 pod 持续运行,对基于 quorum 的集群应用而言尤其如此。为此,Kubernetes 可以指定下线等操作时需要保持的最少 pod 数量,我们通过创建一个 podDisruptionBudget 资源的方式来利用这一特性。
- PodDisruptionBudget(PDB),minAvailable 表示应该有多少个 pod 始终可用
$ kubectl get pdb kubia-pdb -o yaml apiVersion: policy/v1beta1 kind: PodDisruptionBudget metadata: name: kubia-pdb spec: minAvailable: 3 selector: matchLabels: app: kubia status: - 只要它存在,Cluster Autoscaler 与 kubectl drain 命令都会遵守它; 如果疏散一个带有 app=kubia 标签的 pod 会导致它们的总数小于 3,那这个操作就永远不会被执行。
15.4 本章小结
- 除了让 HPA 基于 pod 的 CPU 使用率进行伸缩操作,还可以配置它基于应用自身提供的自定义度量,或者在集群中部署的其他对象的度量来自动伸缩。
16 高级调度
16.1.1 介绍污点和容忍度
- 尽管在 pod 的污点容忍度中显示了等号,但是在节点的污点信息中却没有。当污点或者污点容忍度中的 value 为 null 时,kubectl 故意将污点和污点容忍度进行不同形式的显示。
- 每一个污点都可以关联一个效果,效果包含了以下三种:
- NoSchedule 表示如果 pod 没有容忍这些污点,pod 则不能被调度到包含这些污点的节点上。
- PreferNoSchedule 是 NoSchedule 的一个宽松的版本,表示尽量阻止 pod 被调度到这个节点上,但是如果没有其他节点可以调度,pod 依然会被调度到这个节点上。
- NoExecute 不同于 NoSchedule 以及 PreferNoSchedule,后两者只在调度期间起作用,而 NoExecute 也会影响正在节点上运行着的 pod。如果在一个节点上添加了 NoExecute 污点,那些在该节点上运行着的 pod,如果没有容忍这个 NoExecute 污点,将会从这个节点去除。
17 开发应用的最佳实践
17.2.4 增加生命周期钩子
- 启动后钩子是在容器的主进程启动之后立即执行的。
- 这个钩子和主进程是并行执行的。并不是等到主进程完全启动后
- 即使钩子是以异步方式运行的,它确实通过两种方式来影响容器。在钩子执行完毕之前,容器会一直停留在 Waiting 状态,其原因是 ContainerCreating。因此,pod 的状态会是 Pending 而不是 Running。如果钩子运行失败或者返回了非零的状态码,主容器会被杀死。
- 生命周期的钩子是针对容器而不是 pod 的。你不应该使用停止前钩子来运行那些需要在 pod 终止的时候执行的操作。原因是停止前钩子只会在容器被终止前调用(大部分可能是因为存活探针失败导致的终止)。这个过程会在 pod 的生命周期中发生多次,而不仅仅是在 pod 被关闭的时候。
17.2.5 了解 pod 的关闭
- pod 的关闭是通过 API 服务器删除 pod 的对象来触发的。当接收到 HTTP DELETE 请求后,API 服务器还没有删除 pod 对象,而是给 pod 设置一个 deletionTimestamp 值。拥有 deletionTimestamp 的 pod 就开始停止了。
- 当 Kubelet 意识到需要终止 pod 的时候,它开始终止 pod 中的每个容器。Kubelet 会给每个容器一定的时间来优雅地停止。这个时间叫作终止宽限期 (Termination Grace Period),每个 pod 可以单独配置。在终止进程开始之后,计时器就开始计时,接着按照顺序执行以下事件:
- 执行停止前钩子(如果配置了的话),然后等待它执行完毕
- 向容器的主进程发送 SIGTERM 信号
- 等待容器优雅地关闭或者等待终止宽限期超时
- 如果容器主进程没有优雅地关闭,使用 SIGKILL 信号强制终止进程
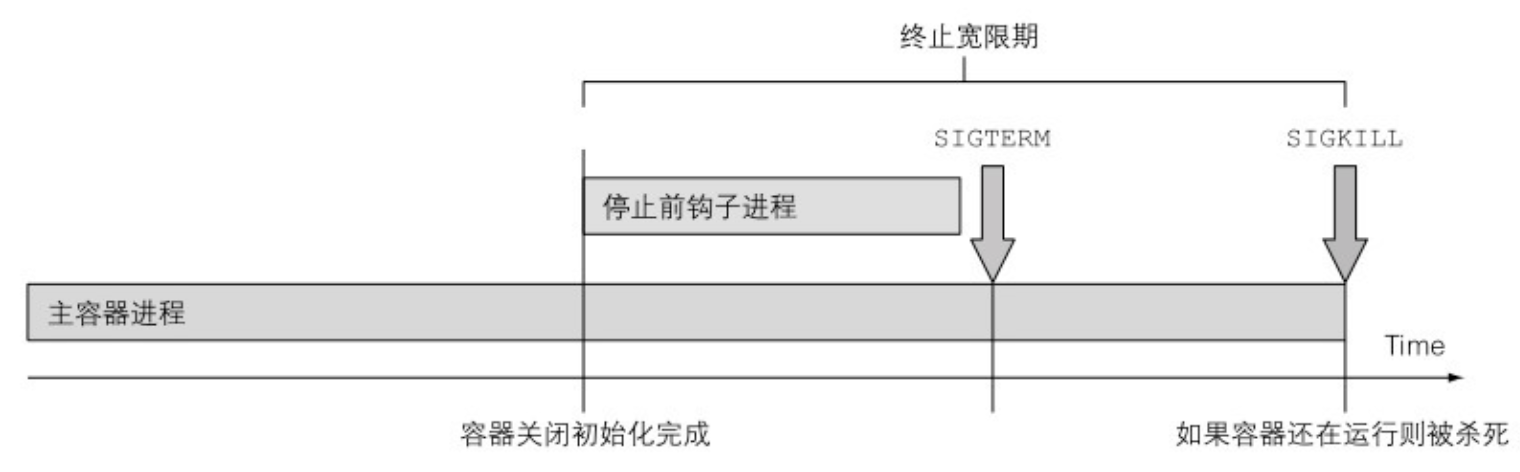
- 指定终止宽限期:终止宽限期可以通过 pod spec 中的 spec.terminationGracePeriod Periods 字段来设置。默认情况下,值为 30,表示容器在被强制终止之前会有 30 秒的时间来自行优雅地终止。
- 你应该将终止宽限时间设置得足够长,这样你的容器进程才可以在这个时间段内完成清理工作。
- 在删除 pod 的时候,pod spec 中指定的终止宽限时间也可以通过如下方式来覆盖:
$ kubectl delete po mypod --grace-period=5 - 强制删除一个 pod 会导致控制器不会等待被删的 pod 里面的容器完成关闭就创建一个替代的 pod。换句话说,相同 pod 的两个实例可能在同一时间运行,这样会导致有状态的集群服务工作异常。
17.3.1 在 pod 启动时避免客户端连接断开
- 如果你在 pod spec 中没有指定就绪探针,那么 pod 总是被认为是准备好了的。
- 你需要做的是当且仅当你的应用准备好处理进来的请求的时候,才去让就绪探针返回成功。
17.3.2 在 pod 关闭时避免客户端连接断开
- 你可以做的唯一的合理的事情就是等待足够长的时间让所有的 kube-proxy 可以完成它们的工作。你无法完美地解决这个问题,理解这一点很重要,但是即使增加 5 秒或者 10 秒延迟也会极大提升用户体验。可以用长一点的延迟时间,但是别太长,因为这会导致容器无法正常关闭,而且会导致 pod 被删除很长一段时间后还显示在列表里面,这个会给删除 pod 的用户带来困扰。
- 简要概括一下,妥善关闭一个应用包括如下步骤:
- 等待几秒钟,然后停止接收新的连接。
- 关闭所有没有请求过来的长连接。
- 等待所有的请求都完成。
- 然后完全关闭应用。
- 至少你可以添加一个停止前钩子来等待几秒钟再退出,或许就像下面代码清单中所示的一样。
lifecycle: preStop: exec: command: - sh - -c - "sleep 5"
17.4.5 给进程终止提供更多的信息
- 为了让诊断过程更容易,可以使用 Kubernetes 的另一个特性,这个特性可以在 pod 状态中很容易地显示出容器终止的原因。可以让容器中的进程向容器的文件系统中指定文件写入一个终止消息。这个文件的内容会在容器终止后被 Kubelet 读取,然后显示在 kubectl describe pod 中。
- 这个进程需要写入终止消息的文件默认路径是 /dev/termination-log,当然这个路径也可以在 pod spec 中容器定义的部分设置 terminationMessagePath 字段来自定义。
- 注意:如果容器没有向任何文件写入消息,可以将 terminationMessage Policy 字段的值设置为 FallbackToLogsOnError。在这种情况下,容器的最后几行日志会被当作终止消息(当然仅当容器没 有成功终止的情况下)。
17.4.6 处理应用日志
- 如果一个容器崩溃了,然后使用一个新的容器替代它,你就会看到新的容器的日志。如果希望看到之前容器的日志,那么在使用 kubectl logs 命令的时候,加上选项 –previous。
- 当日志输出跨越多行的时候,例如 Java 的异常堆栈,就会以不同条目存储在集中式的日志记录系统中。
- 解决方案或许是输出到标准输出终端的日志仍然是用户可读的日志,但是写入日志文件供 FluentD 处理的日志是 JSON 格式。这就要求在节点级别合理地配置 FluentD 代理或者给每一个 pod 增加一个轻量级的日志记录容器。
18 Kubernetes 应用扩展
18.1.3 验证自定义对象
- 在 Kubernetes 1.8 版本中,自定义对象的验证作为 alpha 特性被引入。如果想要让 API 服务器验证自定义对象,需要在 API 服务器中启用 CustomResourceValidation 特性,并在 CRD 中指定一个 JSON schema。
18.2.6 服务目录给我们带来了什么
- 服务提供者可以通过在任何 Kubernetes 集群中注册代理,在该集群中暴露服务,这就是服务目录的最大作用。
18.3.2 Deis Workfiow 与 Helm
- OpenVPN 图表是仓库中最有趣的图表之一,他能使你在 Kubernetes 集群内运行 OpenVPN 服务器,并允许你通过 VPN 和访问服务来输入 pod 网络,就好像本地计算机是集群中的一个容器一样。这在开发应用程序并在本地运行时非常有用。
C 使用其他容器运行时
- Rkt 将属于同一个 pod 的容器放在一起,打印成一组。每个 pod (而不是每个容器)都有其自己的 UUID 和状态。对比使用 Docker 作为容器运行时的执行结果,你会发现,使用 rkt 查看所有 pod 及其容器是多么容易。你可能注意到,由于 rkt 原生支持 pod,每个 pod 中都不存在基础设施容器。
- 可以使用 acbuild 工具 (可在 https://github.com/containers/build 获取) 构建 OCI ( OCI 代表 Open Container Initiative ) 格式的镜像。
- 除 Docker 和 rkt 外,一个称为 CRI-O 的新的 CRI 实现允许 Kubernetes 直接启动和管理 OCI-compliant 容器,而无须部署任何额外的容器运行时。
- 可以用 –container-runtime=crio 来启动 Minikube 试用 CRI-O。
D Cluster Federation
- 虽然 Kubernetes 并不要求你在同一个数据中心内运行控制面板和节点,但为了降低它们之间的网络延迟,减少连接中断的可能性,人们还是希望将它们部署到一起。与其将单个集群分散到多个位置,更好的选择是在每个位置都有一个单独的 Kubernetes 集群。
- 如果你在联合 API 服务器中创建一个命名空间,则所有底层集群中同样会创建出具有相同名称的命名空间。如果你在该命名空间内创建了一个 ConfigMap,那么具有相同名称和内容的 ConfigMap 将在所有基础集群中的同一个命名空间中被创建出来。这也适用于 Secret、 Service 和 DaemonSet。
- ReplicaSet 和 Deployment 是特例,它们不会盲目地被复制到底层集群,因为通常这不是用户想要的。毕竟,如果你创建一个期望副本数为 10 的 Deployment,那么可能你希望的并不是在每个底层集群中运行 10 个 pod 副本,而是一共需要 10 个副本。因此,当你在 Deployment 或 ReplicaSet 中指定所需的副本数时,联合控制器会在底层创建总数相同的副本。默认情况下,副本均匀分布在集群中,当然也可以手动修改。
- 注意:如果要获取所有集群中运行的 pod 列表,需要单独连接各个集群的 API 服务器获得。目前,还无法通过联合 API 服务器列出所有集群的 pod 列表。
- 另一方面,联合 Ingress 资源不会导致在底层集群中创建任何 Ingress 对象。联合 Ingress 资源创建了多底层集群范围全局入口点。
留言

目录
- 1. 译者序
- 2. 1 Kubernetes 介绍
- 3. 2 开始使用 Kubernetes 和 Docker
- 4. 3 pod: 运行于 Kubernetes 中的容器
- 5. 4 副本机制和其他控制器: 部署托管的 pod
- 5.1. 4.1.3 使用存活探针
- 5.2. 4.1.4 配置存活探针的附加属性
- 5.3. 4.2.4 将 pod 移入或移出 ReplicationController 的作用域
- 5.4. 4.2.7 删除一个 ReplicationController
- 5.5. 4.3 使用 ReplicaSet 而不是 ReplicationController
- 5.6. 4.3.1 比较 ReplicaSet 和 ReplicationController
- 5.7. 4.3.4 使用 ReplicaSet 的更富表达力的标签选择器
- 5.8. 4.5.2 定义 Job 资源
- 5.9. 4.5.4 在 Job 中运行多个 pod 实例
- 5.10. 4.5.5 限制 Job pod 完成任务的时间
- 5.11. 4.6.2 了解计划任务的运行方式
- 6. 5 服务: 让客户端发现 pod 并与之通信
- 7. 6 卷: 将磁盘挂载到容器
- 8. 7 ConfigMap 和 Secret: 配置应用程序
- 9. 8 从应用访问 pod 元数据以及其他资源
- 10. 9 Deployment: 声明式地升级应用
- 11. 10 StatefulSet: 部署有状态的多副本应用
- 12. 11 了解 Kubernetes 机理
- 13. 12 Kubernetes API 服务器的安全防护
- 14. 13 保障集群内节点和网络安全
- 15. 14 计算资源管理
- 16. 15 自动横向伸缩 pod 与集群节点
- 17. 16 高级调度
- 18. 17 开发应用的最佳实践
- 19. 18 Kubernetes 应用扩展
- 20. C 使用其他容器运行时
- 21. D Cluster Federation