在线学习地址:https://learn.pingcap.com/learner/course/960001
TiDB 数据库架构
Lesson 01 TiDB 数据库架构概述
- TiDB 整体架构:TiDB Server、TiKV、TiFlash、PD
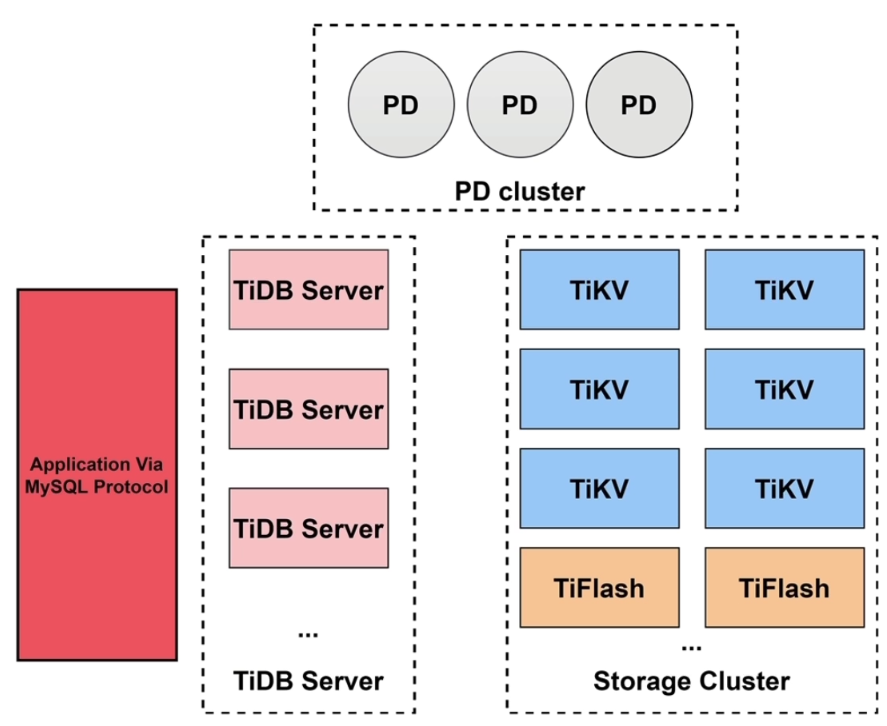
- TiFlash 是 TiKV 的列存版本,并参与复制,保持数据一致
- PD(Placement Driver) 节点记录数据在哪些 TiKV 或 TiFlash 节点上,以及全局时间戳(TSO),还会配合 TiDB Server 生成事务的唯一 ID
- 数据分区(Region)存储(96~144mb),默认三副本,一个 leader 负责读写,另两个读
- 96mb 后 Region 里就不会新插入数据了,但可能会修改已有的数据,所以 region 大小是 96~144mb 一个区间
- 兼容 MySQL 5.7 协议
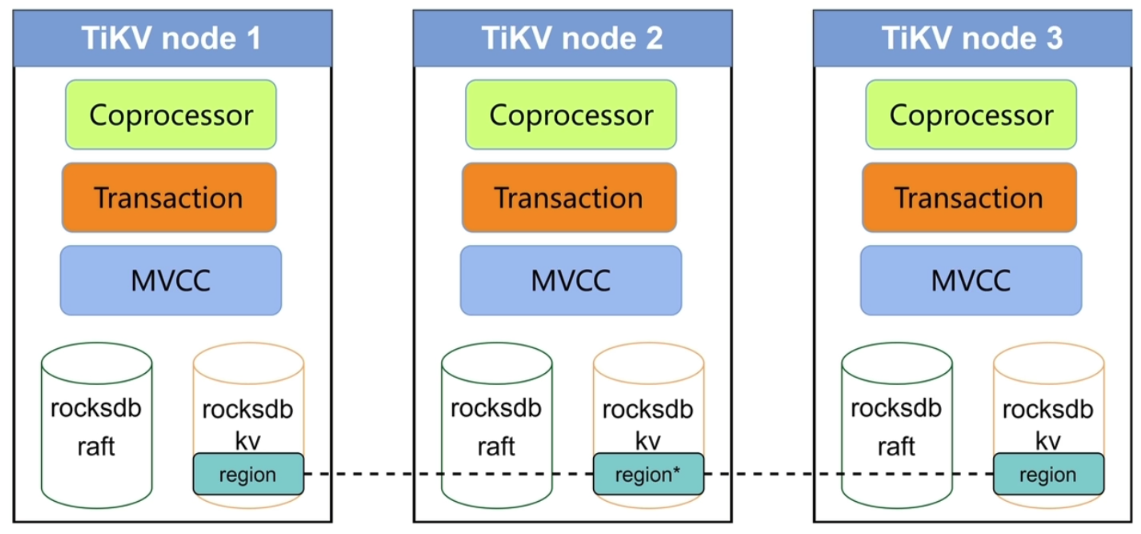
- TiKV = Transaction + MVCC + Raft + rocksdb raft + rocksdb kv
- 分布式事务是两阶段提交。两阶段提交的锁信息被持久化到 TiKV 中。
- PD 会收集集群信息进行调度,达到平衡数据的效果
- TiKV 承载 OLTP 业务,TiFlash 承载 OLAP 业务,达到业务隔离。TiDB Server 根据 SQL 进行预测,智能选择使用 TiKV 还是 TiFlash 进行查询,也可以人工指定
- TiDB Server 是无状态的,不存储数据。支持扩展,缓解连接压力
- TiDB Server 会解析,编译,优化 SQL 语句,生成执行计划;同时会负责将关系型数据转化为 KV 存储进行持久化,以及将 KV 存储转化为关系型数据返回给客户端
- 对于历史版本数据的垃圾回收,是由 TiDB Server 在 TiKV 上完成的
- 数据在TiKV中是以键值对(KEY-VALUE)形式存储的
Lesson 02 TiDB Server
- TiDB Server 架构
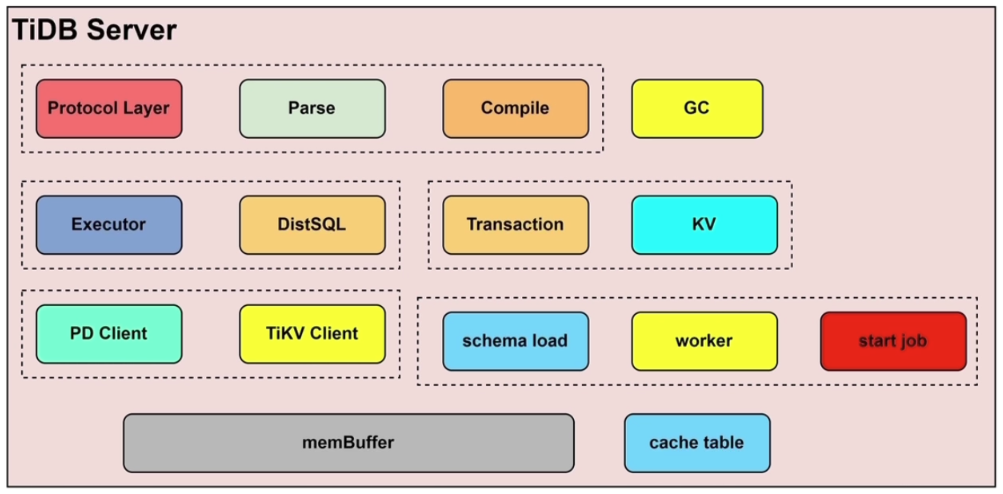
- TiDB Server 主要功能:
- 处理客户端的链接
- SQL 语句的解析和编译
- 关系型数据与 KV 的转化
- SQL 语句的执行
- Online DDL 的执行(DDL 操作不会阻塞读写,但对整个 TiDB 来说,同一时刻只能有一个 TiDB Server 进行 DDL 操作)
- 垃圾回收
- 热点小表缓存 V6.0
- 多个 TiDB Server 轮换选举 Owner 节点,Owner 中的 worker 负责执行 DDL
- DDL job 会存储在 TiKV 中进行持久化
- TiDB 是用 Go 开发的
- TiDB Server GC 默认 10 分钟触发一次,删除当前时间上一个 safe point 之前的历史版本数据
- 热点小表缓存,限制表数据需在 64m 以下,可通过
ALTER TABLE users CACHE;将 users 表放入 TiDB Server 的cache table中。 - 热点小表缓存如何保证读写一致的问题:
tidb_table_cache_lease=5参数控制缓存租约。5s 之内用户可以从缓存中读取数据;租约到期前,任何用户不能修改此表,租约过期后,写数据直接写入 TiKV,读也是从 TiKV 读,完成写操作之后,缓存重新续约,缓存内容也会刷新。所以当租约到期时,读性能会下降。不支持对缓存表直接做 DDL 操作,需要先关闭。 - TiDB 中的表分为两种:聚簇表、非聚簇表。聚簇表需要有主键,非聚簇表可以有主键,也可以没有。KV 转换时,聚簇表使用主键作为 key,非聚簇表不管是否定义了主键,都会生成一个 key。
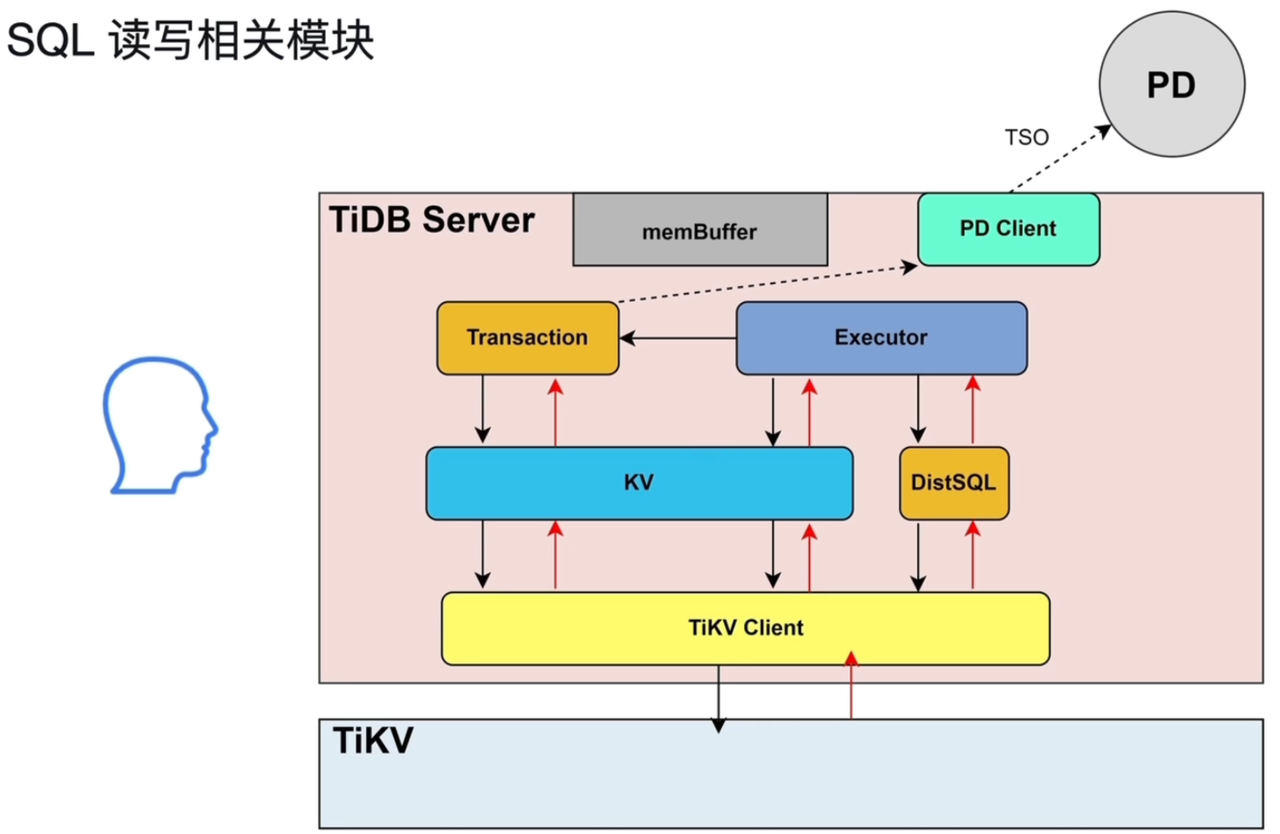
- Protocol Layer 通过 PD Client 异步向 PD 请求 TSO,同时继续进行 SQL 解析和编译,在实际执行前,获取异步请求 TSO 的结果
Lesson 03 TiKV
TiKV-持久化
- TiKV 架构
- RocksDB 写入数据时,先将数据写入到磁盘上的 WAL 文件中(可通过设置
sync_log=true将数据直接写入到磁盘,避免先写入到操作系统的缓存再批量刷到磁盘中而产生的故障时数据丢失的问题),再将数据写入内存的MemTable中(避免因断电等故障导致的内存中数据丢失),MemTable中数据写满后,转为immutable MemTable,有一个immutable MemTable就会触发向磁盘的写入。如果写MemTable速度远大于immutable MemTable写入磁盘的速度,会触发 RocksDB 的流控,导致客户端写入速度降低。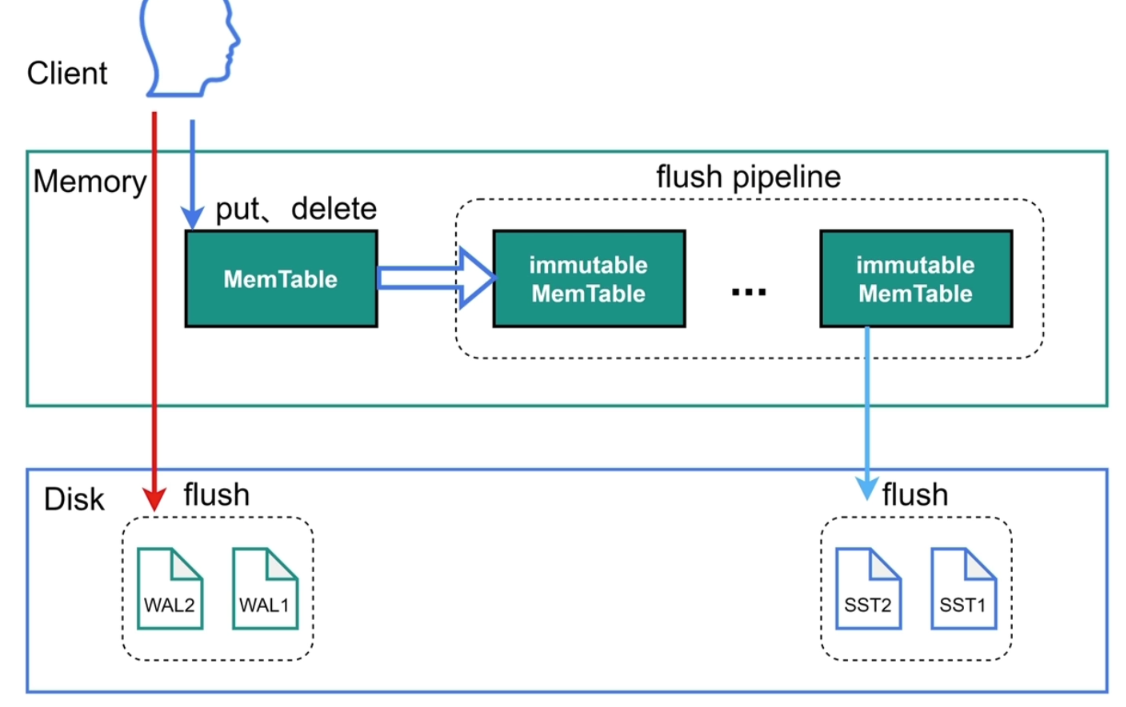
- RocksDB 数据落盘后是分层组织的。
Level 0是对immutable MemTable内容的复刻(转储)。每层数据达到限额时,会进行压缩及按 key 排序,形成下一层的文件(Level 0 不需要排序)。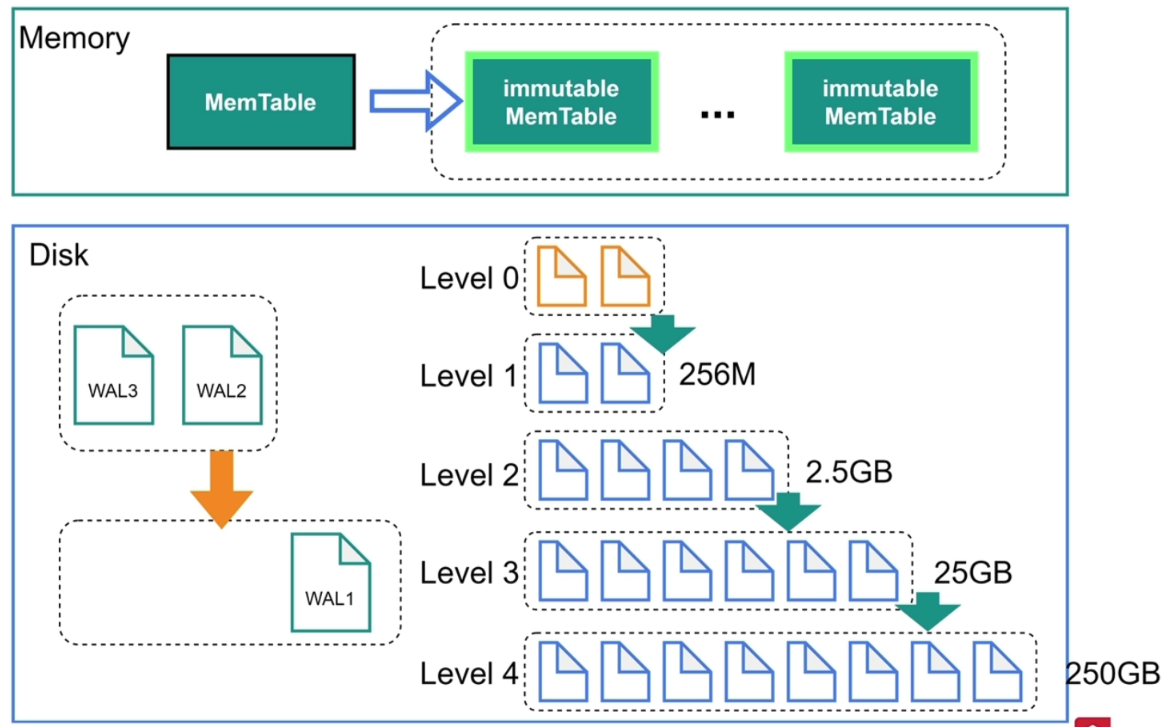
- RocksDB Column Families(CF),列簇,可以将键值对按不同的属性分配给不同的 CF,实现分片。不同列簇各有一套
MemTable、SST文件等,但共享一份WAL文件。写入数据时可指定列簇,不指定时会使用默认的Default列簇。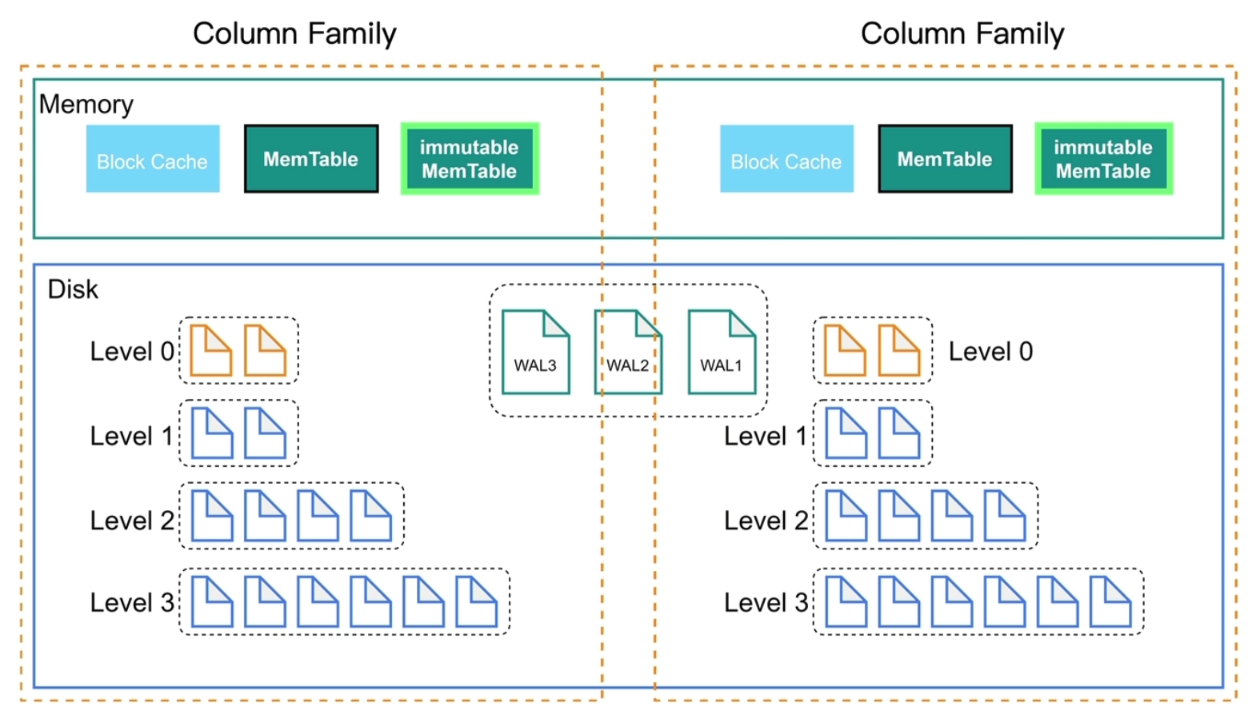
TiKV-分布式事务
- TiKV 的分布式事务主要是通过 乐观锁/悲观锁 + 两阶段提交 实现的,并借助了三个列簇:
Default、Lock、Write - 当用户写入了一行数据时,如果该行数据长度小于 255 字节,那么会被存储到
Write列簇中,否则会被存入到Default列簇中 - 修改多行数据时,只给第一行数据加主锁,其他行的锁会指向主锁
- MVCC:多版本并发控制,该机制可保证不阻塞新事务读取正在事务中的数据的之前已提交的版本
TiKV-Raft
- Raft共识:
- Raft Group 组内成员选举得到Leader 节点;
- Leader 节点负责所有的读写 IO
- Follower只同步变化日志
- Leader + Follower 多数节点写入成功即成功
- 一个 Region 会连同其副本,共同组成一个 raft group,多个 region 就会有多个 raft group,即 Multi Raft
- TiKV包括两个rocksdb:rocksdb raft存放 raft 日志,rocksdb kv存放数据。
- Region 的复制是通过 Raft 日志实现的:Raft Leader 先将数据写入 Raft 日志,然后将日志分发给 follower,follower 收到日志后存入 rocksdb raft,当多数 follower 已完成 raft 日志的同步后,各节点再将数据根据 raft 日志存入自己节点的 rocksdb kv 中
- 通过为每个节点的选举超时时间增加自动的随机值,可以较大程度避免多个节点同时发起选举
- Raft 日志复制过程:
- Propose:写 raft 日志
- Append:持久化到 rocksdb raft
- Replicate:将 raft 日志复制到其他的 TiKV
3.1. Append:Follower 收到 raft 日志后,在自己节点持久化到 rocksdb raft - Committed:给 Leader 回应,不是用户的 committed
- Apply:持久化到 rocksdb kv 中,用户提交成功
TiKV-读写与Coprocessor
- 数据的写入:借助
raftsotre pool和apply pool两个线程池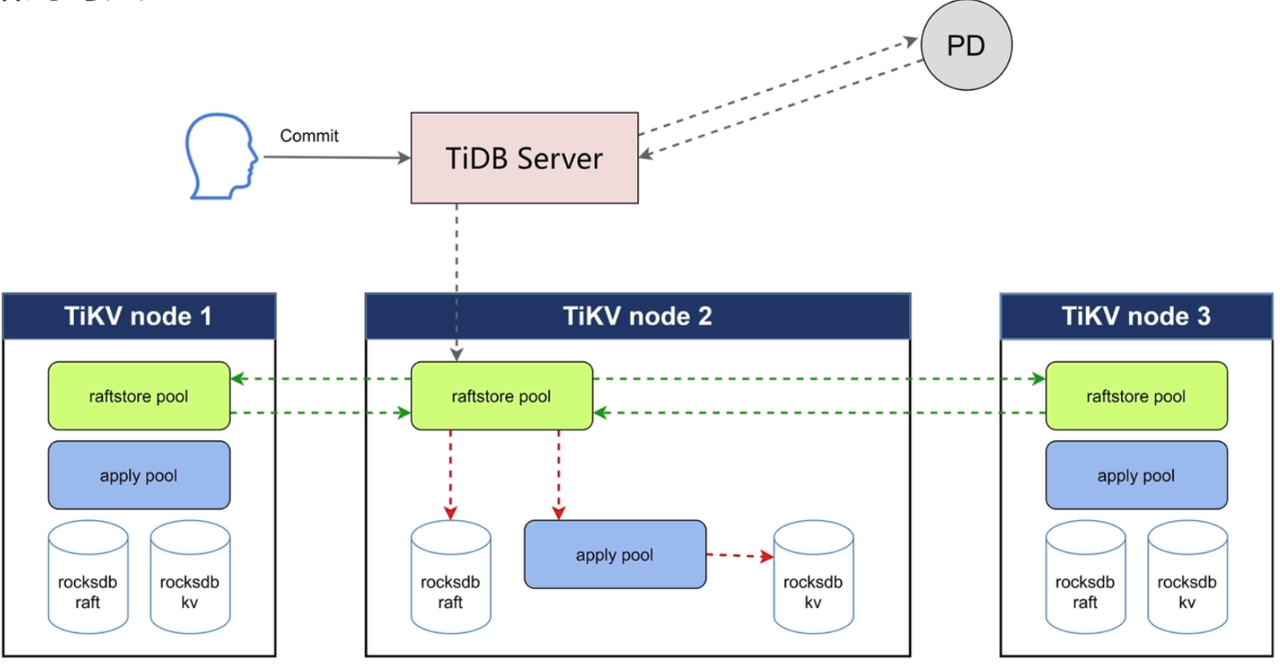
- 数据的读取方式:
- ReadIndex Read:读取时先得到已经 commit 的 raft 日志位置,等待该日志完成 apply 后,再进行读取
- Lease Read:也叫 Local Read。读取需要保证在 Leader 节点读取,通过心跳机制保证,从 Leader 节点发出心跳后至 election timeout 之前,都能保证没有重新选举 Leader 节点,进而保证在 Leader 节点完成数据读取
- Follower Read:与 ReadIndex Read 机制类似,但可能会出现从 Follower 读到 Leader 中尚未 apply 的数据(如果 Follower 的 apply 比 Leader apply 快的话)
- Coprocessor:移动计算不移动数据
- TiFlash 节点也有 Coprocessor,也可以计算
Lesson 04 Placement Driver
- PD 集成了 etcd
- PD 主要功能:
- 整个集群 TiKV 的元数据存储
- 分配全局 ID 和事务 ID
- 生成全局时间戳 TSO
- 收集集群信息进行调度
- 提供 label,支持高可用
- 提供 TiDB Dashboard
- Region Cache的主要作用是缓存region的元数据,减少访问PD的次数。
- TSO = physical time + logical time(顺序不能颠倒),int64 类型
- TSO 的分配能保证增长性,但不能保证连续性
- 只能从 PD 的 Leader 节点获得 TSO
- TiKV 会周期性的向 PD 上报状态
- PD 的调度功能会平衡存储(region)和读写(Leader)的分布
- Label 需要在 PD 和 TiKV 上进行配置
Lesson 05 TiDB 数据库 SQL 执行流程
- DML读流程:
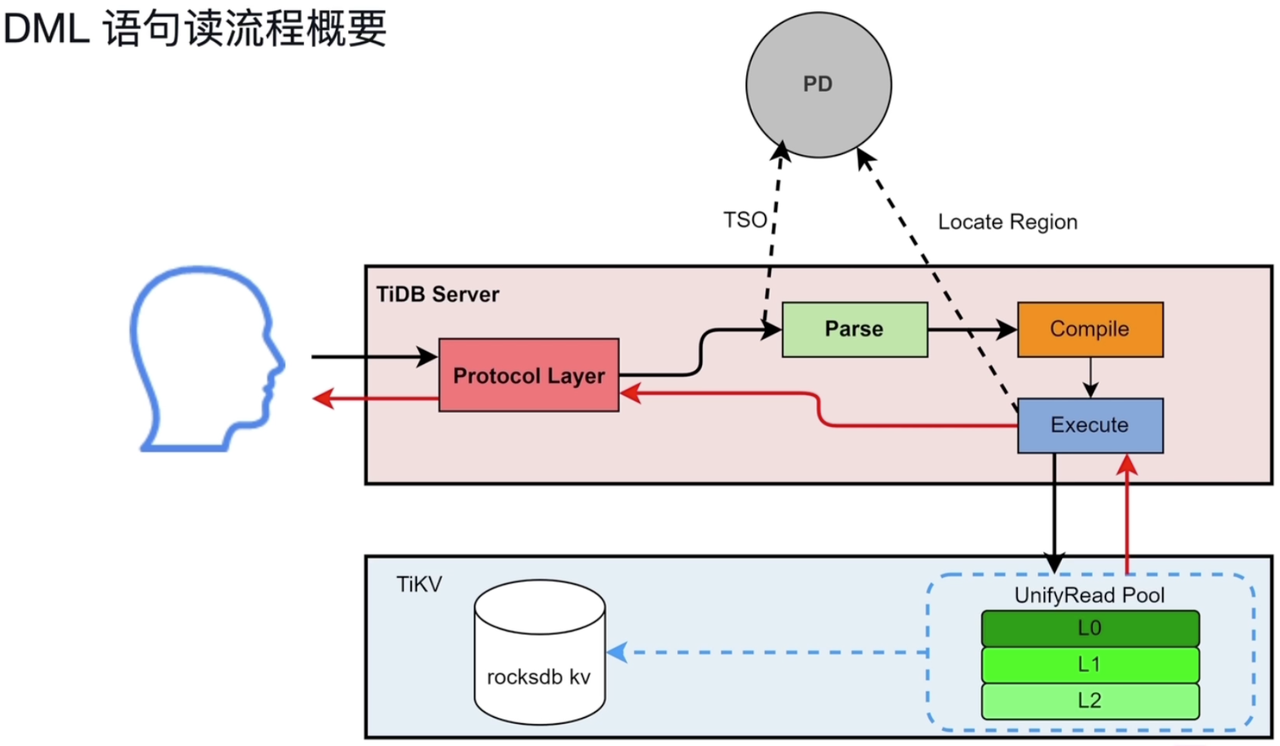
- 解析 SQL 时,会区分是否是点查(Point Get,比如通过索引获得一条记录),如果是点查,则直接通过 KV 模块读取数据,否则会经过后面的过程,到 DistSQL 模块生成执行计划。KV / DistSQL 模块之后都需要通过 Executor 模块执行,再通过 TiKV Client 发送给 TiKV。
- DML写入执行:
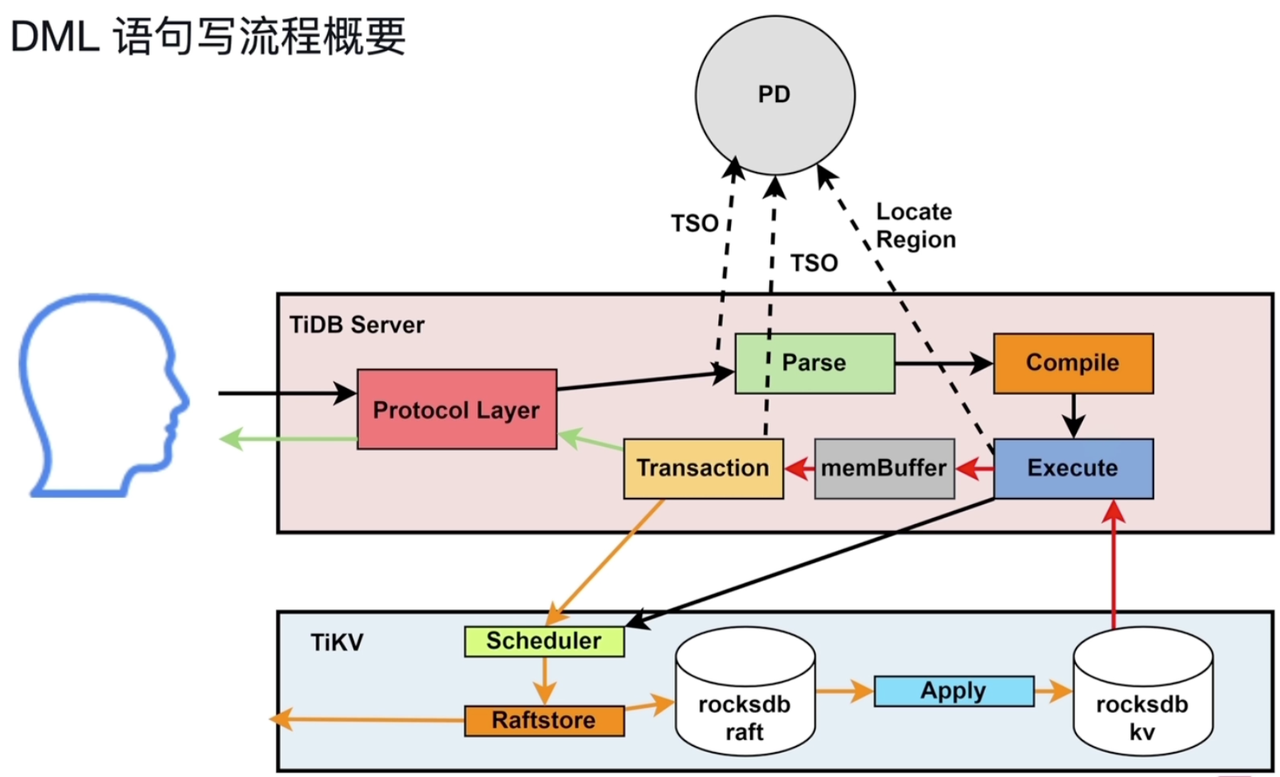
- 将需要修改的数据读入TiDB Server的缓存(memBuffer),同DML读流程
- memBuffer 是每个用户独享的,类似 Oracle 中的 PGA
- TiDB Server涉及写入的三个模块:Transaction、KV、TiKV Client
- Transaction:两阶段提交:第一个阶段是修改数据和加锁,第二步骤是commit和释放锁
- TiKV涉及写入的三个模块:Scheduler、Raftstore、Apply
- Scheduler:接收并发请求;写入同一个key值的数据存在写入冲突时,通过latch保证写完一个再写另一个。
- Raftstore:持久化raft log、向其他节点同步raft log
- Apply:从rocksdb raft读取raft log,并写入rocksdb kv
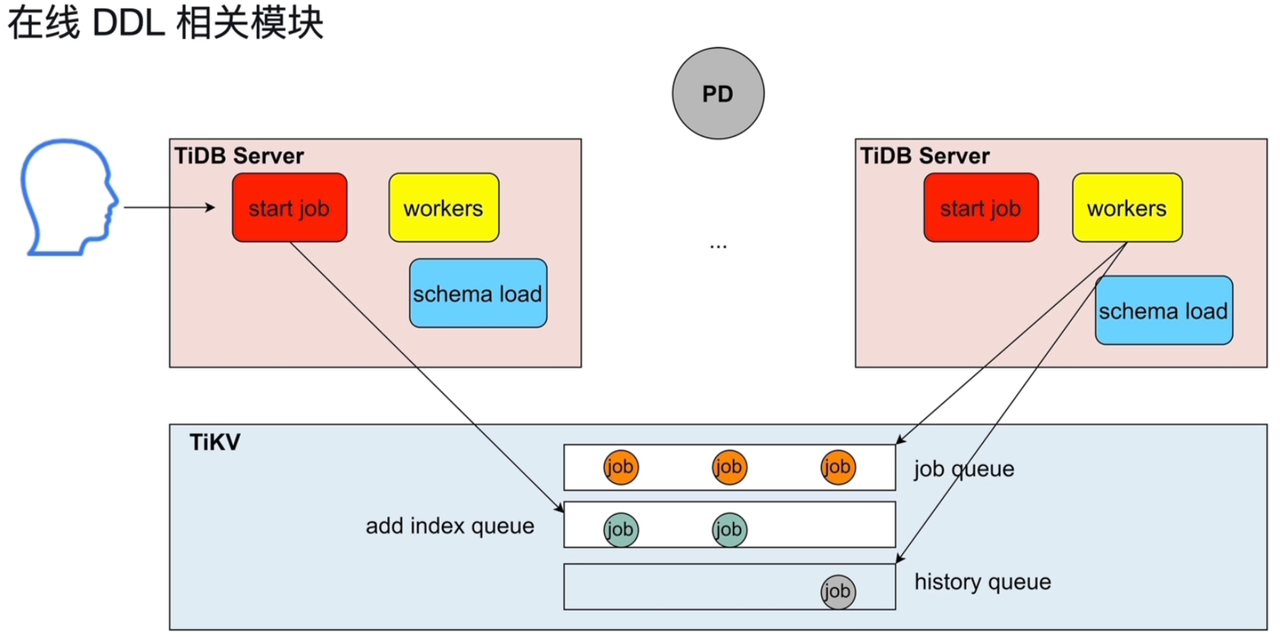
- DDL语句的执行:主要在TiDB Server
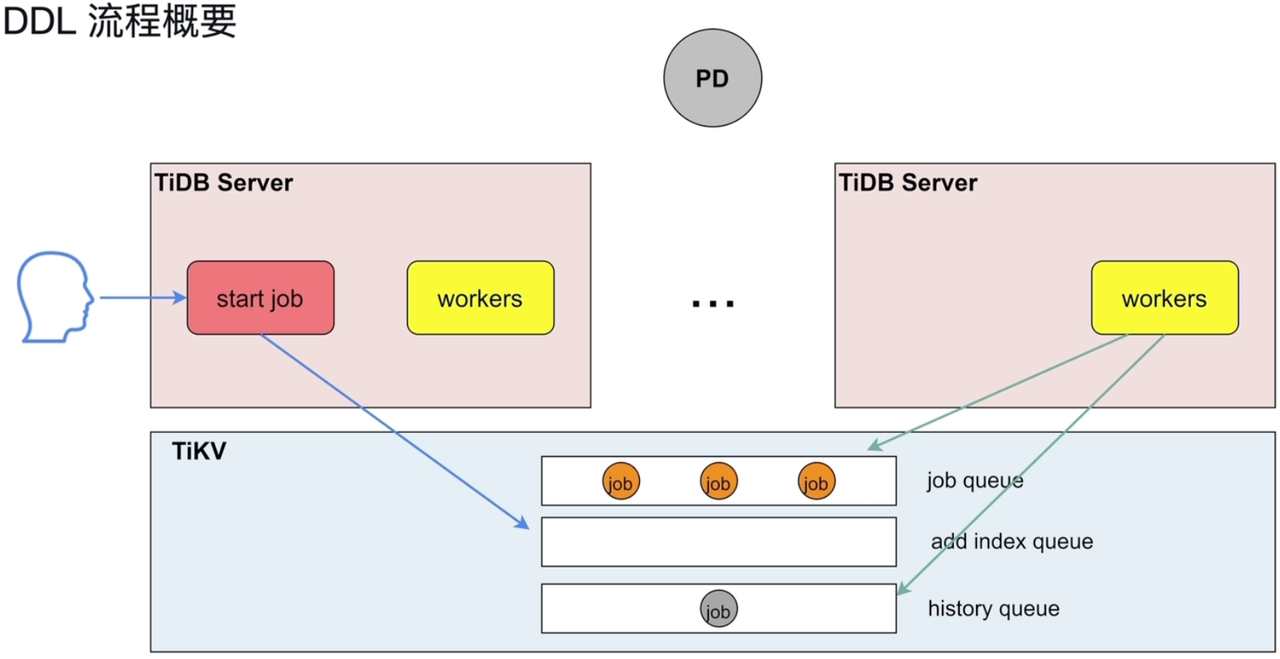
- Portocol Layer:接收DDL语句
- Pares:解析
- Compile:编译DDL语句
- Start job:判断自己所在的server是否owner,如果不是,将DDL持久化到TiKV的job queue中
- workers执行DDL。
- 每一个节点都有workers,但不可以同时执行。
- 同一时刻,只有当TiDB Server 为owner角色时,他的workers才能执行DDL语句。
- 角色为owner的TiDB Server,到job queue中获取DDL后执行。
- owner是由PD节点控制,轮询选出来。
- Schema load:将最新的表的元信息载入到TiDB Server。
- 其他DDL都放在job queue,加索引的DDL有单独的队列,放在add index queue。
- Job queue 和 add index queue 中的语句可以并行执行
TiDB HTAP
Lesson 06 TiDB 数据库 HTAP 概述
- HTAP:混合事务 / 分析处理,具体要求:
- 可扩展性:分布式事务、分布式存储
- 同时支持OLTP与OLAP:同时支持行存和列存,实现OLTP与OLAP业务隔离
- 实时性:行存与列存数据实时同步
- 整体特性
- 列存支持基于主键的实时更新
- 具备智能选择:TiDB server根据sql特性自动选择到TiKV还是到TiFlash
- MPP(Massively Parallel Processing)架构
- 大量数据的join聚合查询:根据sql中关联的表先做交换,将相关的表交换到一个TiFlash节点上进行计算
- 所有MPP的计算都在TiFlash节点内存中完成
- 只支持等值连接
- Enforce_mpp,帮助验证是否可以使用MPP
- TiDB MPP 过程:过滤(并行) => 数据交换(目的是只在本节点进行表连接) => 表连接(并行) => 数据交换(只在本节点进行聚合) => 聚合
- 核心技术
- 利用各个TiFlash节点过滤数据
- 利用各个TiFlash节点交换数据:保证表连接发生在各个TiFlash上、聚合发生在各个TiFlash上
- 充分发挥每一个TiFlash并行计算作用,减少TiDB Server的压力
- 典型应用场景
- 混合负载场景:在线业务、报表应用
- 流式计算:在线应用,对在线数据库产生的数据进行实时分析。传统方案的问题:(1)后端需要维护多个不同类型的数据库;(2)实时性难以满足要求。
Lesson 07 TiFlash
- TiFlash保存TiKV上数据的列存版本,region完全对应、分区一致。region也会随着TiKV上的region分裂与合并
- TiFlash兼容TiDB Server和TiSpark
- TiFlash使用Raft Learner与TiKV进行数据复制
- TiFlash承载OLAP业务,承载能力不高,qps <50
- 主要功能:
- 异步复制:learner不参与Raft投票和选举,只需要获取日志,对线上业务影响小;基于主键快速更新
- 一致性读取:存储多个时间戳的版本,根据读取时间,筛选多个版本中符合的记录
- 引擎智能选择:自动选择使用TiKV或TiFlash,或混合使用。可以是一个 SQL 的不同表,CBO 基于成本选择在 TiFlash 或者 TiKV 上执行 SQL,之后将结果汇总到 TiDB Server 进行连接。
- 计算加速:列存、计算下推
TiDB 6.0 新功能
Lesson 08 TiDB 6.0 新特性
- 1、Placement Rules in SQL:实现分布式数据库中精细化指定数据放置位置
- 使用步骤
- 设计业务拓扑,为不同的TiKV实例设置标签
server.labels:{zone:"BeiJing", rack:"Rack-1", host: "TiKV-1"} - 创建PLACEMENT POLICY:设置leader、follower角色的region位置,以及副本数量。
CREATE PLACEMENT POLICY P1 PRIMARY_REGION="TiKV-5" REGIONS="BeiJing, Tokyo, ShangHai, London" FOLLOWERS=4; - 设定数据对象的PLACEMENT POLICY:创建表、schema、分区等对象并指定遵守的PLACEMENT POLICY。
CREATE TABLE T5 (id INT) PLACEMENT POLICY=P1;
- 设计业务拓扑,为不同的TiKV实例设置标签
- 应用
- 精细化数据放置,控制本地访问与跨区域访问
- 指定副本数,提高重要业务的可用性和数据可靠性(调整单表副本数量)
- 将业务按照等级、资源需求或数据生命周期进行隔离
- 业务数据整合,降低运维成本与复杂度:将业务隔离开
- 使用步骤
- 2、小表缓存:解决分布式数据库的热点问题
- 数据量不大,只读或修改不频繁,但访问很频繁的表
- 缓存在TiDB Server 的内存(cache table)中
- 命令:
ALTER TABLE users CACHE; tidb_table_cache_lease,用于设置缓存租约,默认为5s,租约内只能读不能写。租约到期,内存中的版本过期,此时可以在TiKV中直接写。- 不管租约内还是租约外,都不会阻塞读
- 应用
- 缓存表的大小限制64M
- 适用于查询频繁、数据量不大、极少修改的场景
- 租约时间内,写操作会被阻塞
- 租约到期时,读性能会下降
- 缓存表不支持DDL,需要先关闭缓存表
- 对于表加载较慢或极少修改的表,可以适当延长租约设置,保持读性能稳定
- 3、内存悲观锁:在悲观锁的基础上,提升了事务的执行效率
- 概念
- 在commit的时候,才做prewrite,加锁,在此之前其他事务不知道这个数据上有锁,这是乐观锁。
- 悲观锁在事务 commit 之前就可以让其他事务感知到对这条数据的修改(先将所信息写入 TiKV 的存储)。
- 将悲观锁只写到TiKV的缓存(内存)中,就叫内存悲观锁。写入Leader 角色region所在的节点的缓存,不进行 Follower 的同步。写入内存不写入磁盘,数据只写入 Leader 节点,不进行 Follower 的同步,所以能够提升事务的执行效率。
- 内存悲观锁存在的问题:如果节点宕机,锁丢失,会造成事务失败
- 可以用命令在线开启内存悲观锁,也可以通过配置设置后重新启动
> set config tikv pessimistic-txn.pipelined='true'; > set config tikv pessimistic-txn.in-memory='true'; - 优点:减少事务的延时;降低磁盘和网络带宽;降低TiKV的CPU消耗。
- 概念
- 4、Top SQL:针对性能可观测性的亮眼功能
- 6.0之前只能通过slow query和SQL Statements,但这两个命令针对的是整个集群,不能通过指定单个TiKV。
- 解决的问题:
- 个别TiKV实例的CPU非常高
- CPU占用率突然发生了显著变化
- TOP SQL可以
- 指定TiDB及TiKV实例
- 正在执行的SQL语句
- CPU开销最多的Top 5类SQL
- 每秒请求数、平均延迟等信息
- TOP SQL的使用
- TiDB Dashboard集成了Top SQL
- 步骤1:选择需要观察负载的具体TiDB Server或TiKV实例,可以指定刷新时间
- 步骤2:观察Top 5类SQL,目前根据CPU的使用率统计,不支持内存和IO
- 步骤3:查看某语句的执行情况:Call/sec、Scan Indexes/sec
- 作用
- 可视化地展示CPU开销最多的5类SQL语句
- 支持指定TiDB及TiKV实例进行查询
- 支持统计所有正在执行的SQL语句
- 支持每秒请求数、平均延迟、查询计划等详细执行信息
- 5、TiDB Enterprise Manager(TiEM):集成、规范化、流程化大部分运维操作
- 解决企业中TiDB集群管理的问题
- 数量增长:集群数量、节点数量、组件数量、工具数量
- 复杂度增长:配置参数复杂度、命令行复杂度、管理接口复杂
- 简化、流程化集群管理中的任务,降低出错的几率
- 部署集群、升级集群、参数管理、组件管理、备份恢复与高可用管理、集群监控与告警、集群日志收集、审计与安全
- TiEM功能
- 一键部署集群&多套集群一站式管理
- 集群原地升级
- 参数管理
- 克隆集群&主备集群切换
- 解决企业中TiDB集群管理的问题
TiDB Cloud
Lesson 09 TiDB Cloud 简介
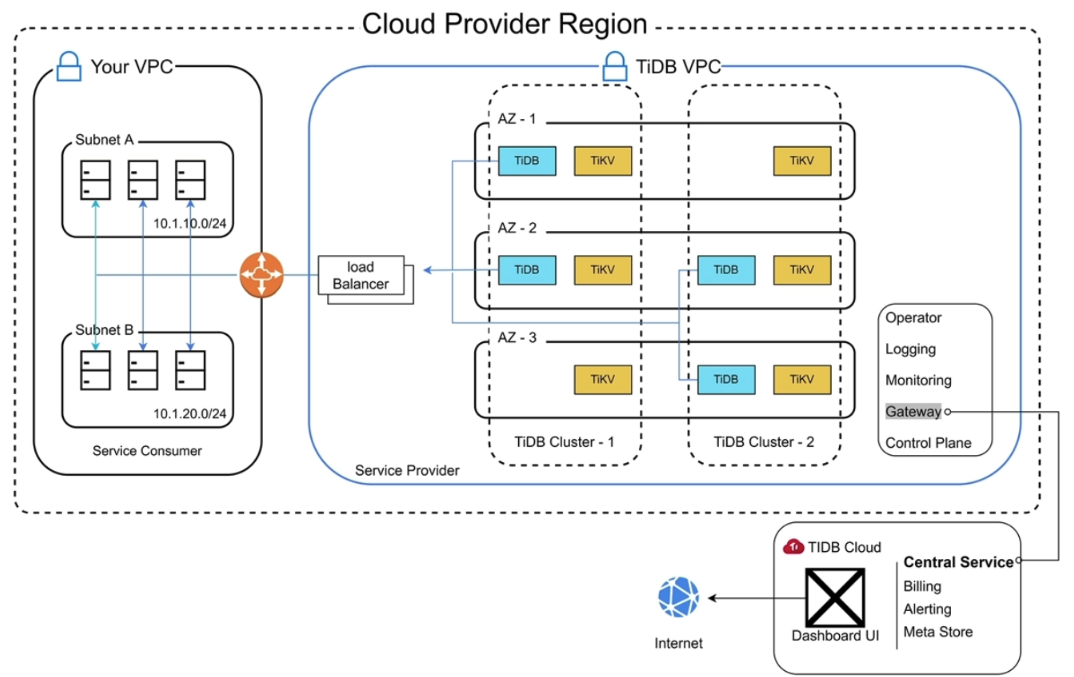
- TiDB Cloud 是一个功能齐全的数据库即服务或 DBaaS
- https://en.pingcap.com/tidb-cloud
- https://tidbcloud.com
- 分成 Developer Tier 和 Dedicated Tier 两种方案,Developer Tier 一年免费,不支持 VPC Peer,不支持横向扩缩容,不具备高可用性
留言
