Chapter 1: Introduction to GraphQL
1.1 What is GraphQL?
1.1.2 GraphQL is a specification
GraphQL operations
Queries represent
READoperations. Mutations representWRITE-then-READopera- tions. You can think of mutations as queries that have side effects.In addition to queries and mutations, GraphQL also supports a third request type called a subscription, used for real-time data monitoring requests. Subscriptions represent continuous
READoperations. Mutations usually trigger events for subscriptions.GraphQL subscriptions require the use of a data-transport channel that supports con- tinuous pushing of data. That’s usually done with WebSockets for web applications.
1.2 Why GraphQL?
GraphQL is a translator
Imagine three people who speak three different languages and have different types of knowledge. Then imagine that you have a question that can only be answered by combining the knowledge of all three people. If you have a translator who speaks all three languages, the task of putting together an answer to your question becomes easy. That is what a GraphQL service can do for clients. This point is valid with other data API options, but GraphQL provides standard structures that enable implementing this kind of data need in easier and more maintainable ways.
1.2.1 What about REST APIs?
- It is important to point out here that REST APIs have some advantages over GraphQL APIs. For example, caching a REST API response is easier than caching a GraphQL API response, as you will see in the last section of this chapter. Also, optimizing the code for different REST endpoints is easier than optimizing the code for a single generic endpoint. There is no single magical solution that fixes all issues without introducing new challenges. REST APIs have their place, and when used correctly, both GraphQL and REST have great applications. Also, nothing prohibits using them together in the same system.
1.3 GraphQL problems
1.3.1 Security
- A critical threat for GraphQL APIs is resource-exhaustion attacks (aka denial-of-service attacks).
- Authentication and authorization are other concerns that you need to think about when working with GraphQL.
1.3.2 Caching and optimizing
- One task that GraphQL makes a bit more challenging is clients’ caching of data.
- One of the other most famous problems you may encounter when working with GraphQL is commonly referred to as N+1 SQL queries.
Summary
- A GraphQL system has two primary components: the query language, which can be used by consumers of data APIs to request their exact data needs; and the runtime layer on the backend, which publishes a public schema describing the capabilities and requirements of data models. The runtime layer accepts incoming requests on a single endpoint and resolves incoming data requests with predictable data responses. Incoming requests are strings written with the GraphQL query language.
- A GraphQL service can be written in any programming language, and it can be conceptually split into two major parts: a structure that is defined with a strongly typed schema representing the capabilities of the API, and behavior that is naturally implemented with functions known as resolvers. A GraphQL schema is a graph of fields, which have types. This graph represents all the possible data objects that can be read (or updated) through the GraphQL service. Each field in a GraphQL schema is backed by a resolver function.
- The difference between GraphQL and its previous alternatives is that it provides standards and structures to implement API features in maintainable and scalable ways. The alternatives lack such standards. GraphQL also solves many technical challenges like having to do multiple network round trips and deal with multiple data responses on the client.
- GraphQL has some challenges, especially in the areas of security and optimiza- tion. Because of the flexibility it provides, securing a GraphQL API requires thinking about more vulnerabilities. Caching a flexible GraphQL API is also a lot harder than caching fixed API endpoints (as in REST APIs). The GraphQL learning curve is also steeper than that of many of its alternatives.
Chapter 2: Exploring GraphQL APIs
2.1 The GraphiQL editor
- GraphiQL (with an i before the QL and pronounced “graphical”). GraphiQL is an open source web application (written with React.js and GraphQL) that can be run in a browser.
2.2 The basics of the GraphQL language
2.2.1 Requests
- The structure of a GraphQL request
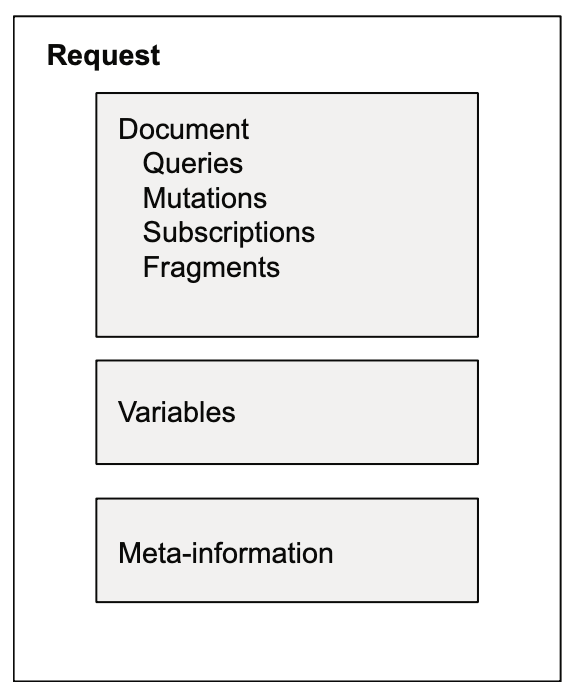
- Three types of operations can be used in GraphQL:
- Query operations that represent a read-only fetch
- Mutation operations that represent a write followed by a fetch
- Subscription operations that represent a request for real-time data updates
2.2.2 Fields
- GraphQL schemas often support four major scalar types:
Int,String,Float, andBoolean. The built-in custom scalar valueIDcan also be used to represent identity values.
2.3 Examples from the GitHub API
2.3.3 Introspective queries
- Fields with names that begin with double underscore characters are reserved for introspection support.
Chapter 3: Customizing and organizing GraphQL operations
3.2 Renaming fields with aliases
- Luckily, in GraphQL, the awesome alias feature lets us declaratively instruct the API server to return fields using different names. All you need to do is specify an alias for that field, which you can do using this syntax:
aliasName: fieldName - Listing 3.14 Profile information query with an alias (az.dev/gia)
query ProfileInfoWithAlias { user(login: "samerbuna") { name companyName: company bio } }
3.3 Customizing responses with directives
- A directive is any string in a GraphQL document that begins with the
@character. Every GraphQL schema has three built-in directives:@include,@skip, and@deprecated. Some schemas have more directives. You can use this introspective query to see the list of directives supported by a schema. - Listing 3.15 All the supported directives in a schema (az.dev/gia)
query AllDirectives { __schema { directives { name description locations args { name description defaultValue } } } }
3.3.1 Variables and input values
- A
variableis simply any name in the GraphQL document that begins with a$sign: for example,$loginor$showRepositories.
3.4 GraphQL fragments
3.4.2 Defining and using fragments
- To define a GraphQL fragment, you can use the
fragmenttop-level keyword in any GraphQL document. You give the fragment a name and specify the type on which that fragment can be used. Then, you write a partial query to represent the fragment. - Listing 3.22 Defining a fragment in GraphQL
fragment orgFields on Organization { name description websiteUrl } - Listing 3.23 Using a fragment in GraphQL
query OrgInfoWithFragment { organization(login: "jscomplete") { ...orgFields } } - The three dots before
orgFieldsare what you use to spread that fragment. The concept of spreading a fragment is similar to the concept of spreading an object in JavaScript. The same three-dots operator can be used in JavaScript to spread an object inside another object, effectively cloning that object. - The three-dotted fragment name (
...orgFields) is called afragment spread. You can use a fragment spread anywhere you use a regular field in any GraphQL operation. - There are no generic fragments in GraphQL. Also, when a fragment is defined in a GraphQL document, that fragment must be used somewhere. You cannot send a GraphQL
server a document that defines fragments but does not use them.
3.4.5 Inline fragments for interfaces and unions
- Listing 3.36 Using inline fragments with union types (az.dev/gia)
query RepoUnionExampleFull { repository(owner: "facebook", name: "graphql") { issueOrPullRequest(number: 5) { ... on PullRequest { merged mergedAt } ... on Issue { closed closedAt } } } }
Chapter 4: Designing a GraphQL schema
4.2 The API requirements for AZdev
4.2.1 The core types
- GraphQL does not have a built-in format for date-time fields. The easiest way to work with these fields is to serialize them as strings in a standard format (like ISO/UTC).
- Remember that the exclamation mark after the ID and String types indicates that these fields cannot have null values.
- Another type modifier is a pair of square brackets around the type (for example, [String]) to indicate that a type is a list of items of another type.
4.3 Queries
4.3.1 Listing the latest Task records
- A general good practice in GraphQL schemas is to make the types of fields non-null, unless you have a reason to distinguish between null and empty.
- However, root fields are special because making them nullable has an important consequence.
- One bad root field should not block the data response of other root fields.
- The semantic meaning of this nullability is, in this case, “Something went wrong in the resolver of this root field, and we’re allowing it so that a response can still have partial data for other root fields.”
4.3.2 Search and the union/interface types
- A GraphQL type can also implement multiple interface types. In SDL, you can just use a comma-separated list of interface types to implement.
4.3.6 The ENUM type
- Listing 4.16 The ApproachDetailCategory ENUM type
enum ApproachDetailCategory { NOTE EXPLANATION WARNING }
4.4 Mutations
4.4.1 Mutation input
- Instead of defining four scalar arguments for the
userCreatemutation, we can group these input values as one input object argument. We use theinputkeyword to do that. - Listing 4.24 Incremental UI-driven schema design
input UserInput { username: String! password: String! firstName: String lastName: String }
4.4.4 Creating and voting on Approach entries
- We just put the comment text on the line before the field that needs it and surround that text with triple quotes (“””).
- Listing 4.32 Adding description text
input ApproachVoteInput { """true for up-vote and false for down-vote""" up: Boolean! } - The clarifying text is known as a
descriptionin a GraphQL schema, and it is part of the structure of that schema. It’s not really a comment but rather a property of this type. Tools like GraphiQL expect it and display it in autocomplete lists and documentation explorers. You should consider adding a description property to any field that could use an explanation.
4.7 Designing database models
4.7.2 The Task/Approach models
- PostgreSQL has an advanced feature to manage a list of items for a single row. A PostgreSQL column can have an array data type!
Chapter 5: Implementing schema resolvers
5.2 Setting up the GraphQL runtime
5.2.2 Creating resolver functions
- Each field defined in the schema needs to be associated with a resolver function. When it is time for the server to reply with data for that field, it will just execute that field’s resolver function and use the function’s return value as the data response for the field.
5.3 Communicating over HTTP
nodemonruns a node process while monitoring files for changes and automatically restarts that node process when it detects changes to the files. That makes the API server auto-restart whenever you save any file in the api directory.
5.4 Building a schema using constructor objects
5.4.3 Custom object types
- GraphiQL supports rendering Markdown in descriptions out of the box!
Chapter 7: Optimizing data fetching
7.1 Caching and batching
- DataLoader is a generic JavaScript utility library that can be injected into your application’s data-fetching layer to manage caching and batching operations on your behalf.
- Note that
DataLoaderuses simple single-resource batching and short-term caching. There are other GraphQL-to-database execution layers that use multiresource batching (without caching and its many problems) to achieve similar (and often better) performance improvements. However, I think theDataLoaderapproach is simpler, more flexible, and easier to maintain.
7.3 Circular dependencies in GraphQL types
- Instead of using types directly under the
fieldsproperty, that property can be a function whose return value is the object representing the fields. GraphQL.js supports this out of the box, and it’s handy for situations like these. - Listing 7.25 Changes in api/src/schema/types/approach.js
const Approach = new GraphQLObjectType({ name: 'Approach', fields: () => ({ // ·-·-· task: { type: new GraphQLNonNull(Task), resolve: (source, args, { pgApi }) => pgApi.tasks.load(source.taskId), }, }), }); - It is a good practice to
alwaysuse the function signature for thefieldsconfiguration property instead of the object form.
Summary
- To optimize data-fetching operations in a generic, scalable way, you can use the concepts of caching and batching. You can cache SQL responses based on unique values like IDs or any other custom unique values you design in your API service. You can also delay asking the database about a specific resource until you figure out all the unique IDs of all the records needed from that resource and then send a single request to the database to include all the records based on all the IDs.
DataLoaderis a generic JavaScript library that can be used as part of your application’s data-fetching layer to provide a simplified, consistent API over various data sources and abstract the use of batching and caching.
Chapter 8: Implementing mutations
Summary
- To host mutations, a GraphQL schema must define a root mutation type.

目录
- 1. Chapter 1: Introduction to GraphQL
- 2. Chapter 2: Exploring GraphQL APIs
- 3. Chapter 3: Customizing and organizing GraphQL operations
- 4. Chapter 4: Designing a GraphQL schema
- 5. Chapter 5: Implementing schema resolvers
- 6. Chapter 7: Optimizing data fetching
- 7. Chapter 8: Implementing mutations