作者:@weiliang-ms
CPU Manager 介绍说明
CPU Manager 是 kubelet 的一个组件,能够让用户给容器分配独占 CPU。CPU Manager 从 Kubernetes v1.10 进入 Beta 阶段, 在 Kubernetes v1.26 中,它进阶至正式发布(GA)状态。
注:本文涉及源码基于 kubernetes v1.23
CPU Manager 开发目的
为 pod 固定 CPU(核心),减少 CPU 上下文切换,提高缓存亲和性,从而降低应用程序延迟和提高的 CPU 吞吐量。
CPU Manager 实现原理
大多数 linux 平台基于以下三种方式控制 CPU用量 :
- 前两种为:
cpu.cfs_period_us和cpu.cfs_quota_us。这里的 cfs 是 Completely Fair Scheduler (完全公平调度器)的缩写。
cpu.cfs_period_us: 调度周期,默认为 100000,单位为微秒,即100mscpu.cfs_quota_us:cpu.cfs_period_us调度期间内可使用的 cpu 时间,单位为微秒,默认 -1,即无限制。- CPU Manager 使用的是第三种:CPU 亲和性(cpuset.cpus, 在哪个逻辑CPU执行指令)
当 CPU Manager 启用并设置为 static 策略时,它管理一个 CPU 共享池。最初,这个共享池包含计算节点中的所有 CPU。当 kubelet 在 Guaranteed Pod 中创建一个具有整数 CPU 请求的容器时,该容器的 CPU 将从共享池中移除,并在容器的生命周期内独占分配,并且其他容器将会从这些独占分配的 CPU 中迁移。
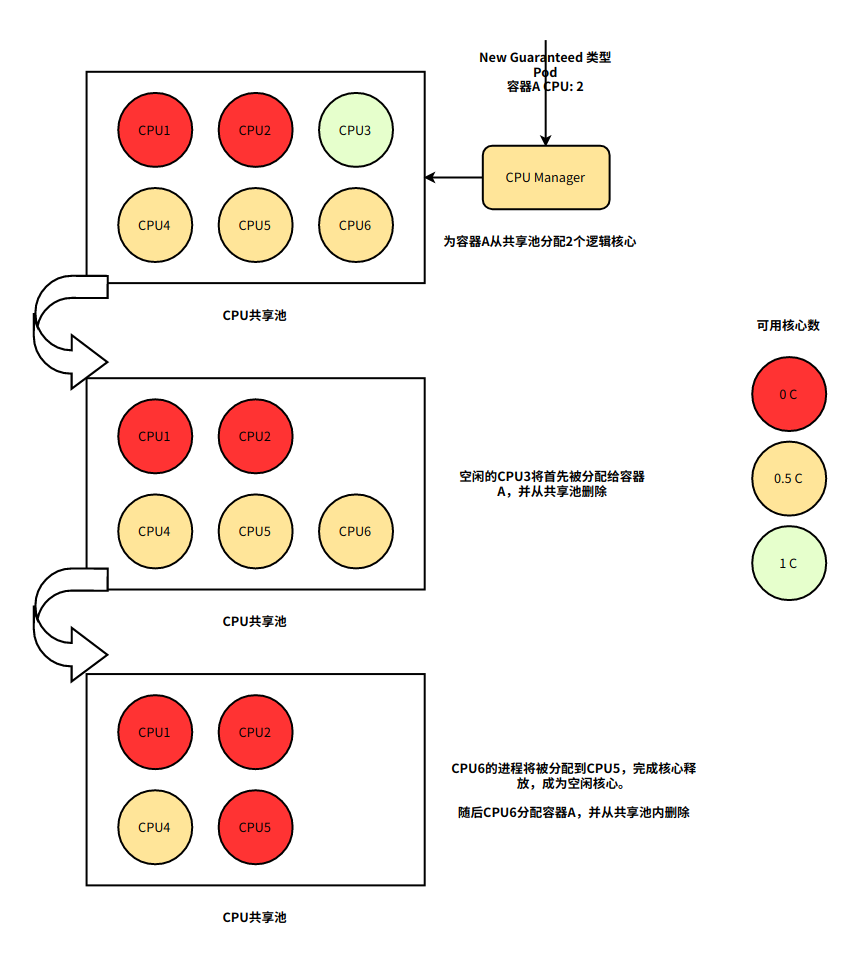
我们可以通过下面例子来验证:
创建
Guaranteed QoS类型 podA,CPU 配额为2(单节点,且开启CPU Manager static 策略)cat <<EOF | kubectl apply -f - kind: Pod apiVersion: v1 metadata: name: pod-with-cpu-manager-6986db896d-j7r6c namespace: default labels: app: pod-with-cpu-manager spec: containers: - name: container-c677ki image: nginx:latest resources: limits: cpu: 2 memory: 1Gi requests: cpu: 2 memory: 1Gi EOF创建辅助脚本,用于获取pod pid
cat > get-pid-with-podName.sh <<EOF #!/usr/bin/env bash Check_jq() { which jq &> /dev/null if [ $? != 0 ];then echo -e "\033[32;32m 系统没有安装 jq 命令,请参考下面命令安装! \033[0m \n" echo -e "\033[32;32m Centos 或者 RedHat 请使用命令 yum install jq -y 安装 \033[0m" echo -e "\033[32;32m Ubuntu 或者 Debian 请使用命令 apt-get install jq -y 安装 \033[0m" exit 1 fi } Pid_info() { docker_storage_location=`docker info | grep 'Docker Root Dir' | awk '{print $NF}'` for docker_short_id in `docker ps | grep ${pod_name} | grep -v pause | awk '{print $1}'` do docker_long_id=`docker inspect ${docker_short_id} | jq ".[0].Id" | tr -d '"'` cat ${docker_storage_location}/containers/${docker_long_id}/config.v2.json | jq ".State.Pid" done } pod_name=$1 Check_jq Pid_info EOF获取
pod-with-cpu-manager-6986db896d-j7r6c进程id# sh get-pid-with-podName.sh pod-with-cpu-manager-6986db896d-j7r6c 26846获取
pod-with-cpu-manager-6986db896d-j7r6c的 cgroup 信息# cat /proc/26846/cgroup 12:devices:/kubepods/podafde59d3-a1b5-40b5-9558-3a79c9f31213/db802b8521318a3d267b745b28ab2d655e77abea7647e6e8cebf5318d6c8310a 11:hugetlb:/kubepods/podafde59d3-a1b5-40b5-9558-3a79c9f31213/db802b8521318a3d267b745b28ab2d655e77abea7647e6e8cebf5318d6c8310a 10:rdma:/ 9:cpuset:/kubepods/podafde59d3-a1b5-40b5-9558-3a79c9f31213/db802b8521318a3d267b745b28ab2d655e77abea7647e6e8cebf5318d6c8310a 8:blkio:/kubepods/podafde59d3-a1b5-40b5-9558-3a79c9f31213/db802b8521318a3d267b745b28ab2d655e77abea7647e6e8cebf5318d6c8310a 7:perf_event:/kubepods/podafde59d3-a1b5-40b5-9558-3a79c9f31213/db802b8521318a3d267b745b28ab2d655e77abea7647e6e8cebf5318d6c8310a 6:pids:/kubepods/podafde59d3-a1b5-40b5-9558-3a79c9f31213/db802b8521318a3d267b745b28ab2d655e77abea7647e6e8cebf5318d6c8310a 5:memory:/kubepods/podafde59d3-a1b5-40b5-9558-3a79c9f31213/db802b8521318a3d267b745b28ab2d655e77abea7647e6e8cebf5318d6c8310a 4:freezer:/kubepods/podafde59d3-a1b5-40b5-9558-3a79c9f31213/db802b8521318a3d267b745b28ab2d655e77abea7647e6e8cebf5318d6c8310a 3:net_cls,net_prio:/kubepods/podafde59d3-a1b5-40b5-9558-3a79c9f31213/db802b8521318a3d267b745b28ab2d655e77abea7647e6e8cebf5318d6c8310a 2:cpu,cpuacct:/kubepods/podafde59d3-a1b5-40b5-9558-3a79c9f31213/db802b8521318a3d267b745b28ab2d655e77abea7647e6e8cebf5318d6c8310a 1:name=systemd:/kubepods/podafde59d3-a1b5-40b5-9558-3a79c9f31213/db802b8521318a3d267b745b28ab2d655e77abea7647e6e8cebf5318d6c8310a 0::/查看
pod-with-cpu-manager-6986db896d-j7r6c的 cpuset 信息# cat /sys/fs/cgroup/cpuset/kubepods/podafde59d3-a1b5-40b5-9558-3a79c9f31213/db802b8521318a3d267b745b28ab2d655e77abea7647e6e8cebf5318d6c8310a/cpuset.cpus 8,64我们看到,
pod-with-cpu-manager-6986db896d-j7r6c可用 CPU 为8、64。此时我们再创建
Guaranteed QoS类型 podB,CPU 配额为1.5cat <<EOF | kubectl apply -f - kind: Pod apiVersion: v1 metadata: name: pod-without-cpu-manager-5f686bd75b-5q2bh namespace: default labels: app: pod-with-cpu-manager spec: containers: - name: container-c677ki image: nginx:latest resources: limits: cpu: 1.5 memory: 1Gi requests: cpu: 1.5 memory: 1Gi EOF获取
pod-without-cpu-manager-5f686bd75b-5q2bh进程id# sh get-pid-with-podName.sh pod-without-cpu-manager-5f686bd75b-5q2bh 63119获取
pod-without-cpu-manager-5f686bd75b-5q2bh的 cgroup 信息# cat /proc/63119/cgroup 12:devices:/kubepods/pod145a1163-b54c-464d-b14e-07f6fb4c5ab7/1759cc5169f63ce5cef9a244c4b89e2bb4a8a0c1daab0c9bfec0cbe2bee9b3c9 11:hugetlb:/kubepods/pod145a1163-b54c-464d-b14e-07f6fb4c5ab7/1759cc5169f63ce5cef9a244c4b89e2bb4a8a0c1daab0c9bfec0cbe2bee9b3c9 10:rdma:/ 9:cpuset:/kubepods/pod145a1163-b54c-464d-b14e-07f6fb4c5ab7/1759cc5169f63ce5cef9a244c4b89e2bb4a8a0c1daab0c9bfec0cbe2bee9b3c9 8:blkio:/kubepods/pod145a1163-b54c-464d-b14e-07f6fb4c5ab7/1759cc5169f63ce5cef9a244c4b89e2bb4a8a0c1daab0c9bfec0cbe2bee9b3c9 7:perf_event:/kubepods/pod145a1163-b54c-464d-b14e-07f6fb4c5ab7/1759cc5169f63ce5cef9a244c4b89e2bb4a8a0c1daab0c9bfec0cbe2bee9b3c9 6:pids:/kubepods/pod145a1163-b54c-464d-b14e-07f6fb4c5ab7/1759cc5169f63ce5cef9a244c4b89e2bb4a8a0c1daab0c9bfec0cbe2bee9b3c9 5:memory:/kubepods/pod145a1163-b54c-464d-b14e-07f6fb4c5ab7/1759cc5169f63ce5cef9a244c4b89e2bb4a8a0c1daab0c9bfec0cbe2bee9b3c9 4:freezer:/kubepods/pod145a1163-b54c-464d-b14e-07f6fb4c5ab7/1759cc5169f63ce5cef9a244c4b89e2bb4a8a0c1daab0c9bfec0cbe2bee9b3c9 3:net_cls,net_prio:/kubepods/pod145a1163-b54c-464d-b14e-07f6fb4c5ab7/1759cc5169f63ce5cef9a244c4b89e2bb4a8a0c1daab0c9bfec0cbe2bee9b3c9 2:cpu,cpuacct:/kubepods/pod145a1163-b54c-464d-b14e-07f6fb4c5ab7/1759cc5169f63ce5cef9a244c4b89e2bb4a8a0c1daab0c9bfec0cbe2bee9b3c9 1:name=systemd:/kubepods/pod145a1163-b54c-464d-b14e-07f6fb4c5ab7/1759cc5169f63ce5cef9a244c4b89e2bb4a8a0c1daab0c9bfec0cbe2bee9b3c9 0::/查看
pod-without-cpu-manager-5f686bd75b-5q2bh的 cpuset 信息# cat /sys/fs/cgroup/cpuset/kubepods/pod145a1163-b54c-464d-b14e-07f6fb4c5ab7/1759cc5169f63ce5cef9a244c4b89e2bb4a8a0c1daab0c9bfec0cbe2bee9b3c9/cpuset.cpus 0,7,9-55,62-63,65-111我们发现
pod-without-cpu-manager-5f686bd75b-5q2bh可用 CPU 为 0,7,9-55,62-63,65-111(共享),并且pod-with-cpu-manager-6986db896d-j7r6c所用 CPU(8,64)并不在该列表内。值得注意的是: 如 pod 容器配额CPU数与节点单CPU的逻辑核心数一致时,会优先分配同一物理CPU的逻辑核心(比如下面的pod,申请56个cpu)
# cat /sys/fs/cgroup/cpuset/kubepods/pod1b76c2cf-b554-4a74-98b5-0674399c1437/e3c5ee424235ab35e29bb647508b0fc9d8e3d5251a22c06cf180d74963fc2b66/cpuset.cpus 28-55,84-111 # lscpu ... CPU(s): 112 On-line CPU(s) list: 0-111 Thread(s) per core: 2 Core(s) per socket: 28 Socket(s): 2 NUMA node(s): 2 NUMA node0 CPU(s): 0-27,56-83 NUMA node1 CPU(s): 28-55,84-111 ...
CPU Manager 架构设计
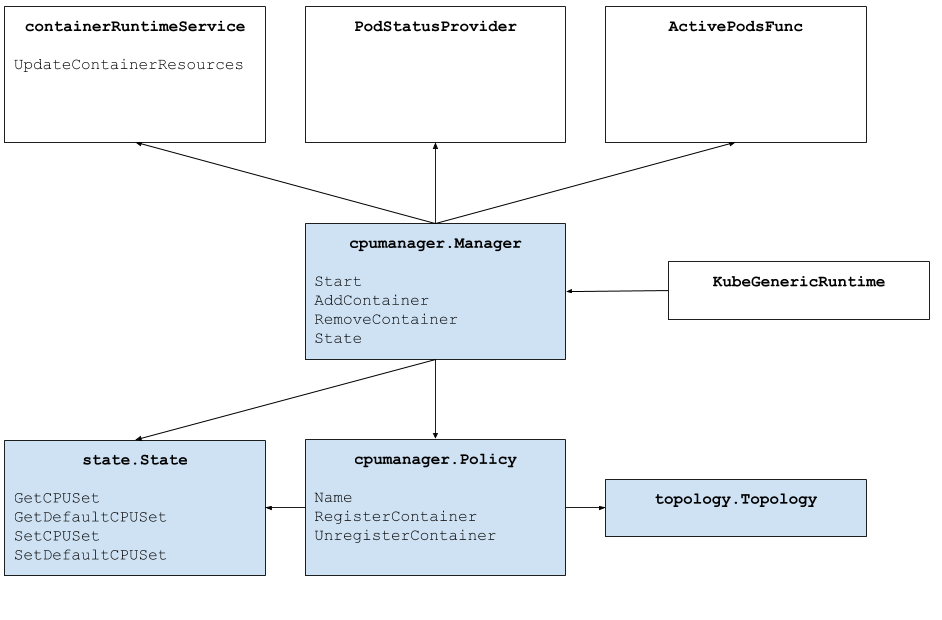
上图展示了 CPU Manager 的结构。 CPU Manager 使用容器运行时接口的 UpdateContainerResources 方法来修改容器可以在其上运行的 CPU。
func (c *runtimeServiceClient) UpdateContainerResources(ctx context.Context, in *UpdateContainerResourcesRequest, opts ...grpc.CallOption) (*UpdateContainerResourcesResponse, error) {
out := new(UpdateContainerResourcesResponse)
err := c.cc.Invoke(ctx, "/runtime.v1.RuntimeService/UpdateContainerResources", in, out, opts...)
if err != nil {
return nil, err
}
return out, nil
}
// 更新内容
type LinuxContainerResources struct {
// CPU CFS (Completely Fair Scheduler) period. Default: 0 (not specified).
CpuPeriod int64 `protobuf:"varint,1,opt,name=cpu_period,json=cpuPeriod,proto3" json:"cpu_period,omitempty"`
// CPU CFS (Completely Fair Scheduler) quota. Default: 0 (not specified).
CpuQuota int64 `protobuf:"varint,2,opt,name=cpu_quota,json=cpuQuota,proto3" json:"cpu_quota,omitempty"`
// CPU shares (relative weight vs. other containers). Default: 0 (not specified).
CpuShares int64 `protobuf:"varint,3,opt,name=cpu_shares,json=cpuShares,proto3" json:"cpu_shares,omitempty"`
// Memory limit in bytes. Default: 0 (not specified).
MemoryLimitInBytes int64 `protobuf:"varint,4,opt,name=memory_limit_in_bytes,json=memoryLimitInBytes,proto3" json:"memory_limit_in_bytes,omitempty"`
// OOMScoreAdj adjusts the oom-killer score. Default: 0 (not specified).
OomScoreAdj int64 `protobuf:"varint,5,opt,name=oom_score_adj,json=oomScoreAdj,proto3" json:"oom_score_adj,omitempty"`
// CpusetCpus constrains the allowed set of logical CPUs. Default: "" (not specified).
CpusetCpus string `protobuf:"bytes,6,opt,name=cpuset_cpus,json=cpusetCpus,proto3" json:"cpuset_cpus,omitempty"`
// CpusetMems constrains the allowed set of memory nodes. Default: "" (not specified).
CpusetMems string `protobuf:"bytes,7,opt,name=cpuset_mems,json=cpusetMems,proto3" json:"cpuset_mems,omitempty"`
// List of HugepageLimits to limit the HugeTLB usage of container per page size. Default: nil (not specified).
HugepageLimits []*HugepageLimit `protobuf:"bytes,8,rep,name=hugepage_limits,json=hugepageLimits,proto3" json:"hugepage_limits,omitempty"`
// Unified resources for cgroup v2. Default: nil (not specified).
// Each key/value in the map refers to the cgroup v2.
// e.g. "memory.max": "6937202688" or "io.weight": "default 100".
Unified map[string]string `protobuf:"bytes,9,rep,name=unified,proto3" json:"unified,omitempty" protobuf_key:"bytes,1,opt,name=key,proto3" protobuf_val:"bytes,2,opt,name=value,proto3"`
// Memory swap limit in bytes. Default 0 (not specified).
MemorySwapLimitInBytes int64 `protobuf:"varint,10,opt,name=memory_swap_limit_in_bytes,json=memorySwapLimitInBytes,proto3" json:"memory_swap_limit_in_bytes,omitempty"`
XXX_NoUnkeyedLiteral struct{} `json:"-"`
XXX_sizecache int32 `json:"-"`
}如何获取 CPU 拓扑信息?
CPU Manager 通过 cAdvisor 获取 CPU 拓扑信息:
// CPUTopology contains details of node cpu, where :
// CPU - logical CPU, cadvisor - thread
// Core - physical CPU, cadvisor - Core
// Socket - socket, cadvisor - Socket
// NUMA Node - NUMA cell, cadvisor - Node
type CPUTopology struct {
NumCPUs int
NumCores int
NumSockets int
NumNUMANodes int
CPUDetails CPUDetails
}
// Discover returns CPUTopology based on cadvisor node info
func Discover(machineInfo *cadvisorapi.MachineInfo) (*CPUTopology, error) {
if machineInfo.NumCores == 0 {
return nil, fmt.Errorf("could not detect number of cpus")
}
CPUDetails := CPUDetails{}
numPhysicalCores := 0
for _, node := range machineInfo.Topology {
numPhysicalCores += len(node.Cores)
for _, core := range node.Cores {
if coreID, err := getUniqueCoreID(core.Threads); err == nil {
for _, cpu := range core.Threads {
CPUDetails[cpu] = CPUInfo{
CoreID: coreID,
SocketID: core.SocketID,
NUMANodeID: node.Id,
}
}
} else {
klog.ErrorS(nil, "Could not get unique coreID for socket", "socket", core.SocketID, "core", core.Id, "threads", core.Threads)
return nil, err
}
}
}
return &CPUTopology{
NumCPUs: machineInfo.NumCores,
NumSockets: machineInfo.NumSockets,
NumCores: numPhysicalCores,
NumNUMANodes: CPUDetails.NUMANodes().Size(),
CPUDetails: CPUDetails,
}, nil
}架构设计之初也曾考虑从以下几种方式获取,但最终都没有采纳:
- 通过读取并解析虚拟文件 /proc/cpuinfo 获取 CPU 信息
- 通过在子进程中执行一个简单的程序,如 lscpu -p 获取 CPU 信息
- 执行成熟的外部拓扑程序,如 mpi-hwloc(需打包内嵌至kubelet)
如何配置 CPU Manager?
CPU Manager 策略通过 kubelet 参数 --cpu-manager-policy 或 KubeletConfiguration 中的 cpuManagerPolicy 字段来指定:
- static:该策略下,对于
Guaranteed QoS类型 pod 内的容器, 并且容器对CPU资源的资源限制是大于等于1的整数时,则会为容器分配独占 CPU。 - none:默认策略,该策略保留了现有的 kubelet 行为,即对 cgroup cpuset 不做任何处理。
当为一个容器分配独占 CPU 时,这些 CPU 将从该节点上运行的所有其他容器的允许 CPU 中移除,并且在 pod 的生命周期内,该独占 CPU 不会被分配给其他容器(直到该 pod 终止)。
| Pod配置方式 | CPU分配方式 |
|---|---|
| Pod [Guaranteed]: 容器A: cpu: 0.5 |
共享 |
| Pod [Guaranteed]: 容器A: cpu: 2.0 |
独享 |
| Pod [Guaranteed]: 容器A: cpu: 1.0 容器B: cpu: 0.5 |
容器A独享 容器B共享 |
| Pod [Guaranteed]: A: cpu: 1.5 B: cpu: 0.5 |
容器A共享 容器B共享 |
| Pod [Burstable] | 共享 |
| Pod [BestEffort] | 共享 |
CPU Manager 性能提升
来自 Intel 的两位工程师:Balaji Subramaniam, Connor Doyle 针对启用 CPU Manager 静态策略后,对于工作负载的性能变化做了三个场景的测试
- 测试平台:双插槽Intel Xeon CPU E5-2680 v3,共计48个逻辑 CPU (24个物理内核,支持超线程)
CPU 相关知识补充
Linux 下 可以通过 lscpu 获取 CPU 信息,如:逻辑CPU数(112)、每个物理插槽核心数(28)、插槽数(2)、主频(2.7GHz)等
# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 112
On-line CPU(s) list: 0-111
Thread(s) per core: 2
Core(s) per socket: 28
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Gold 6258R CPU @ 2.70GHz
Stepping: 7
CPU MHz: 1200.003
CPU max MHz: 4000.0000
CPU min MHz: 1000.0000
BogoMIPS: 5400.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 39424K
NUMA node0 CPU(s): 0-27,56-83
NUMA node1 CPU(s): 28-55,84-111- 物理CPU:物理CPU就是插在主机上的真实的CPU硬件(Socket(s): 2)
- 核心数:多核处理器中的核指的就是核心数,在Linux下可以通过cores来确认主机的物理CPU的核心数。(Core(s) per socket: 28)
- 逻辑CPU:逻辑CPU跟超线程技术有联系,假如物理CPU不支持超线程的,那么逻辑CPU的数量等于核心数的数量;如果物理CPU支持超线程,那么逻辑CPU的数目是核心数数目的两倍。(Thread(s) per core * Core(s) per socket)
- 超线程:超线程是英特尔开发出来的一项技术,使得单个处理器可以象两个逻辑处理器那样运行,这样单个处理器以并行执行线程。
场景一:吵闹的邻居
该场景下,运行 PARSEC benchmark suite 基准测试套件中6项基准测试,这些基准测试与CPU压力容器(stress)共存,并启用了CPU Manager特性。
普林斯顿共享内存计算机应用程序存储库(PARSEC)是一个由多线程程序组成的基准套件,旨在成为多核处理器的下一代共享内存程序的代表。
CPU压力容器(stress pod) 以 --cpus=48参数启动,并设置容器配额 requests.cpu = 23 ,不设置limits.cpu(Burstable QoS)。
stress是一个linux下的压力测试工具
基准测试 pod 容器(PARSEC)设置配额设置如下:(Guaranteed QoS)
resources:
requests:
cpu: 24
memory: 4Gi
limits:
cpu: 24
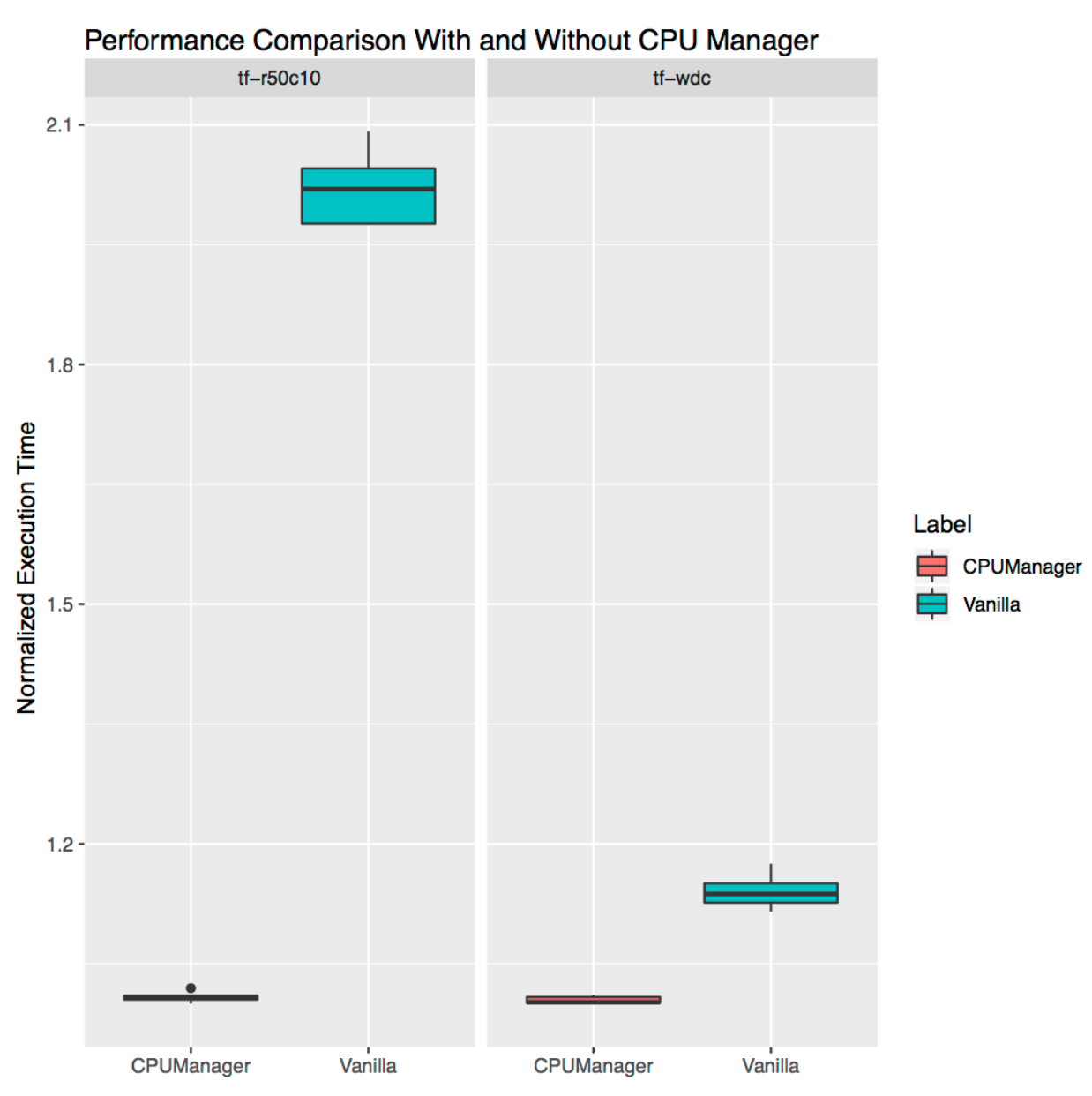
memory: 4Gi下图显示了在启用和不启用CPU Manager静态策略的情况下,运行与stress pod共存的基准测试 pod 的规范化执行时间。当为所有测试用例启用静态策略时,性能得到一定提升。
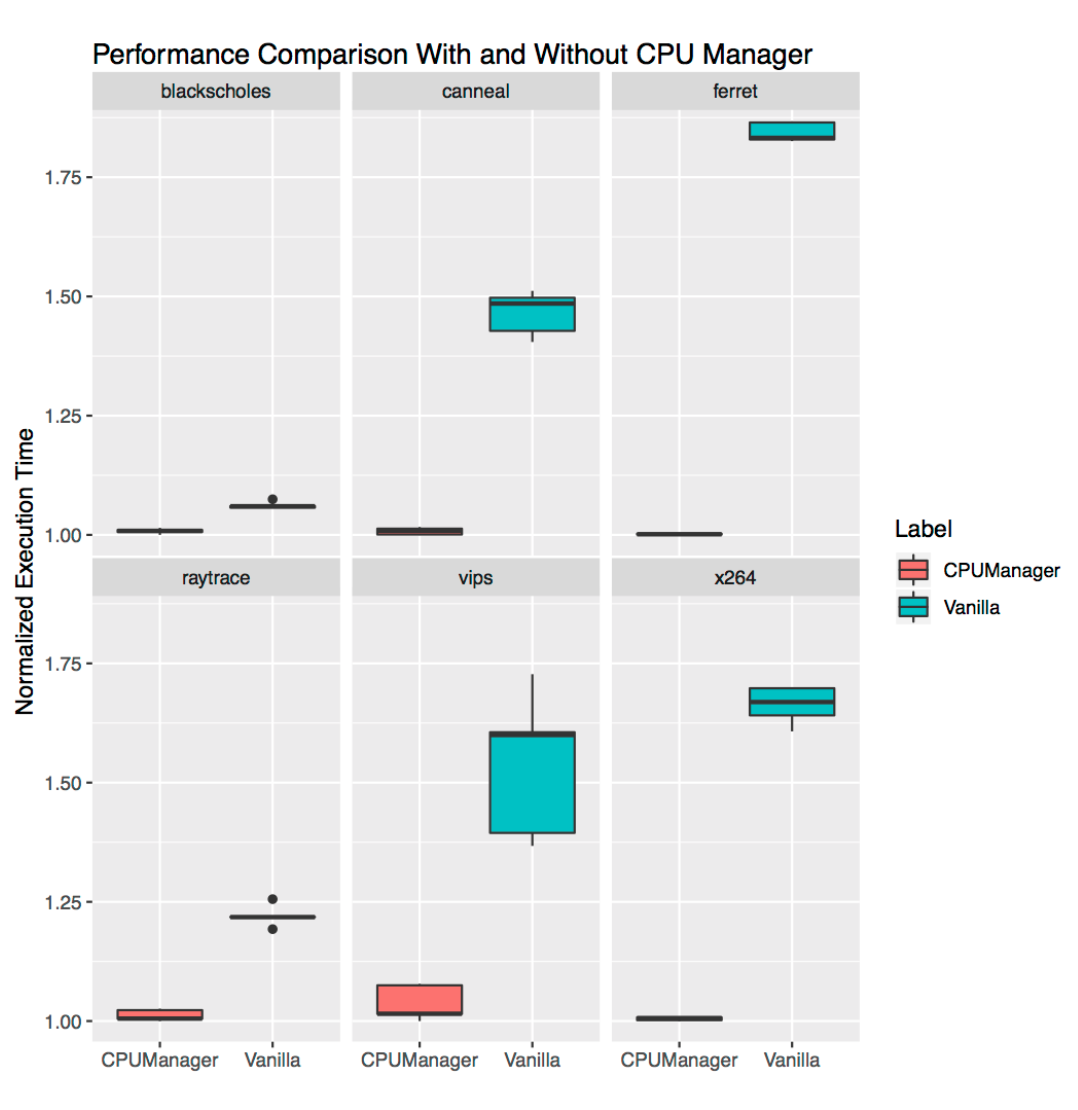
运行的执行时间被归一化为性能最佳的运行(y轴上的1.00表示性能最佳的运行,越低越好)。箱形图的高度显示了性能的变化。例如,如果框图是一条线,那么在不同的运行中,性能就没有变化。
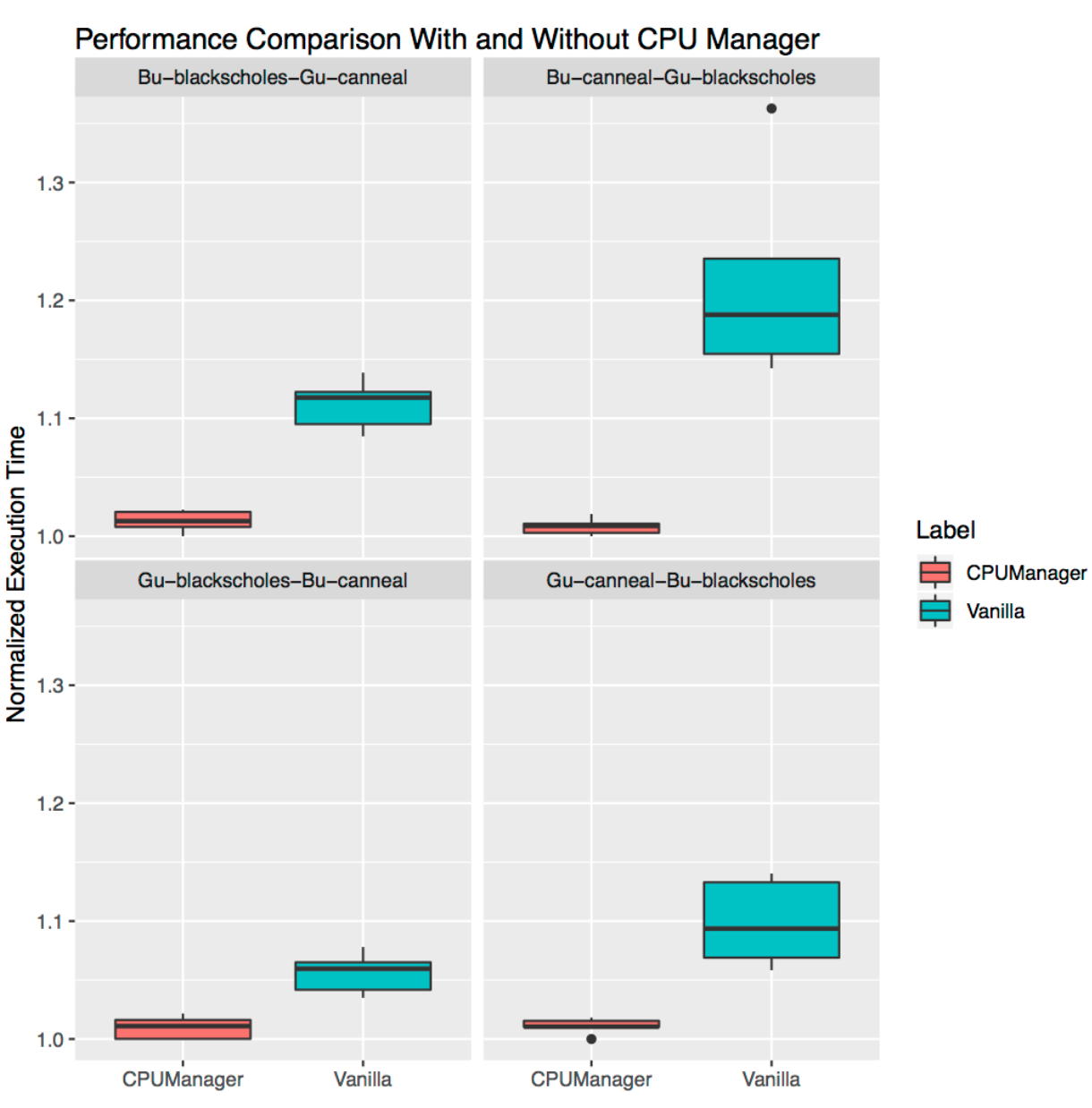
场景二:共存工作负载
共存工作负载为PARSEC基准测试套件中的基准测试 Blackscholes 和 Canneal,它们运行在相互共存的 Guaranteed (Gu) 和 Burstable (Bu) QoS 类型 pod 中。其中,Gu(Guaranteed) QoS 类中的 pod 请求的总核心数相当于一个物理 CPU 逻辑核心之和(即24个cpu), Bu(Burstable) QoS类中的 pod 请求23个cpu。
在四个排列组合测试中,在开启 CPU Manager 静态策略后,共存的工作负载都有性能提升。例如:
Bu-blackscholes-Gu-canneal(左上)和Gu-cannel-Bu-blackscholes(右下)情况下,Canneal由于是Guaranteed QoS 类型 pod , 并且 CPU 配额核心数为整数(24),因此获得独占 CPU。而Blackscholes也获得了独占的 CPU,因为它是 CPU 共享池中唯一的工作负载。因此,由于 CPU Manager的静态策略,Blackscholes和Canneal都获得了一定性能隔离的性能提升。
场景三:独占物理CPU
该场景下工作负载选用 TensorFlow官方模型: wide and deep 与 ResNet。分别使用 census 和 CIFAR10 数据集用于wide and deep 与 ResNet 模型。在每种情况下,pod1(wide and deep) 与 pod2 (ResNet) 各请求24个cpu(与单一物理CPU 逻辑核心数一致,将独占物理CPU)。如图所示, CPU Manager 在这两种情况下都支持更好的性能隔离。