https://book.douban.com/subject/35470134/
Introduction
Domain-driven design (DDD) proposes to attack the root cause for failed software projects from a different angle. Effective communication is the central theme of the domain-driven design tools and practices you are about to learn in this book. DDD can be divided into two parts: strategic and tactical.
Part I. Strategic Design
There is no sense in talking about the solution before we agree on the problem, and no sense talking about the implementation steps before we agree on the solution.
– Efrat Goldratt-Ashlag
Chapter 1. Analyzing Business Domains
What Is a Business Domain?
A business domain defines a company’s main area of activity. Generally speaking, it’s the service the company provides to its clients.
What Is a Subdomain?
A subdomain is a fine-grained area of business activity. All of a company’s subdomains form its business domain: the service it provides to its customers.
The subdomains have to interact with each other to achieve the company’s goals in its business domain.
Types of Subdomains
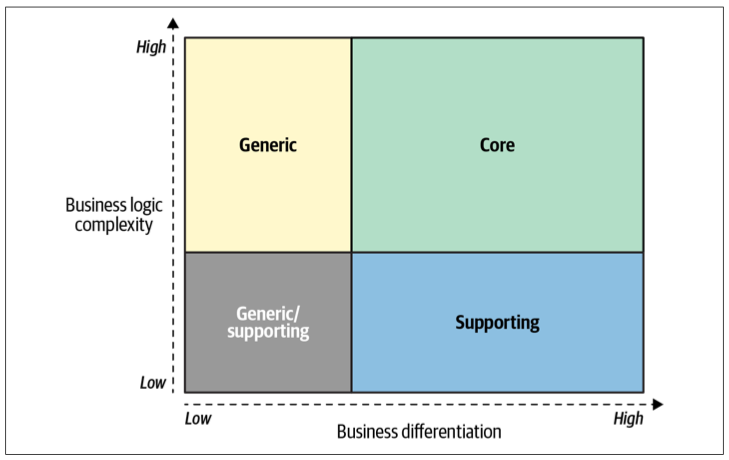
… subdomains bear different strategic/business values. Domain-driven design distinguishes between three types of subdomains: core, generic, and supporting.
Core subdomains
A core subdomain is what a company does differently from its competitors. This may involve inventing new products or services or reducing costs by optimizing existing processes.
Complexity. A core subdomain that is simple to implement can only provide a short-lived competitive advantage. Therefore, core subdomains are naturally complex.
Sources of competitive advantage. It’s important to note that core subdomains are not necessarily technical. Not all business problems are solved through algorithms or other technical solutions. A company’s competitive advantage can come from various sources.
Consider, for example, a jewelry maker selling its products online. The online shop is important, but it’s not a core subdomain. The jewelry design is.
Core Subdomain Versus Core Domain
Core subdomains are also called core domains. For example, in the original domain-driven design book, Eric Evans uses “core subdomain” and “core domain” interchangeably. Although the term “core domain” is used often, I prefer to use “core subdomain” for a number of reasons. First, it is a subdomain, and I prefer to avoid confusion with business domains. Second, as you will learn in Chapter 11, it’s not uncommon for subdomains to evolve over time and change their types. For example, a core subdomain can turn into a generic subdomain. Hence, saying that “a generic subdomain has evolved into a core subdomain” is more straightforward than saying “a generic subdomain has evolved into a core domain.”
Generic subdomains
Generic subdomains are business activities that all companies are performing in the same way. Like core subdomains, generic subdomains are generally complex and hard to implement. However, generic subdomains do not provide any competitive edge for the company. There is no need for innovation or optimization here: battle-tested implementations are widely available, and all companies use them.
For example, most systems need to authenticate and authorize their users. Instead of inventing a proprietary authentication mechanism, it makes more sense to use an existing solution. Such a solution is likely to be more reliable and secure since it has already been tested by many other companies that have the same needs.
Supporting subdomains
As the name suggests, supporting subdomains support the company’s business. However, contrary to core subdomains, supporting subdomains do not provide any competitive advantage.
The distinctive characteristic of supporting subdomains is the complexity of the solution’s business logic. Supporting subdomains are simple.
These activity areas do not provide any competitive advantage for the company, and therefore do not require high entry barriers.
Comparing Subdomains
Competitive advantage
Only core subdomains provide a competitive advantage to a company. Core subdomains are the company’s strategy for differentiating itself from its competitors.
Generic subdomains, by definition, cannot be a source for any competitive advantage. These are generic solutions—the same solutions used by the company and its competitors.
Supporting subdomains have low entry barriers and cannot provide a competitive advantage either. Usually, a company wouldn’t mind its competitors copying its supporting subdomains—this won’t affect its competitiveness in the industry. On the contrary, strategically the company would prefer its supporting subdomains to be generic, ready-made solutions, thus eliminating the need to design and build their implementation.
At times it may be challenging to differentiate between core and supporting subdomains. Complexity is a useful guiding principle. Ask whether the subdomain in question can be turned into a side business. Would someone pay for it on its own? If so, this is a core subdomain. Similar reasoning applies for differentiating supporting and generic subdomains: would it be simpler and cheaper to hack your own implementation, rather than integrating an external one? If so, this is a supporting subdomain.
The chart in Figure 1-1 represents the interplay between the three types of subdomains in terms of business differentiation and business logic complexity. The intersection between the supporting and generic subdomains is a gray area: it can go either way. If a generic solution exists for a supporting subdomain’s functionality, the resultant subdomain type depends on whether it’s simpler and/or cheaper to integrate the generic solution than it is to implement the functionality from scratch.
Volatility
… core subdomains can change often.
Contrary to the core subdomains, supporting subdomains do not change often.
Despite having existing solutions, generic subdomains can change over time.
Since core subdomains’ requirements are expected to change often and continuously, the solution must be maintainable and easy to evolve. Thus, core subdomains require implementation of the most advanced engineering techniques.
Since generic subdomains are hard but already solved problems, it’s more cost-effective to buy an off-the-shelf product or adopt an open source solution than invest time and effort into implementing a generic subdomain in-house.
Lack of competitive advantage makes it reasonable to avoid implementing supporting subdomains in-house. However, unlike generic subdomains, no ready-made solutions are available. So, a company has no choice but to implement supporting subdomains itself. That said, the simplicity of the business logic and infrequency of changes make it easy to cut corners.
Supporting subdomains do not require elaborate design patterns or other advanced engineering techniques. A rapid application development framework will suffice to implement the business logic without introducing accidental complexities.
From a staffing perspective, supporting subdomains do not require highly skilled technical aptitude and provide a great opportunity to train up-and-coming talent. Save the engineers on your team who are experienced in tackling complex challenges for the core subdomains. Finally, the simplicity of the business logic makes supporting subdomains a good candidate for outsourcing.
Table 1-1 summarizes the aspects in which the three types of subdomains differ.

Identifying Subdomain Boundaries
We can use the definition of “subdomains as a set of coherent use cases” as a guiding principle for when to stop looking for finer-grained subdomains. These are the most precise boundaries of the subdomains.
Focus on the essentials
When looking for subdomains, it’s important to identify business functions that are not related to software, acknowledge them as such, and focus on aspects of the business that are relevant to the software system you are working on.
Who Are the Domain Experts?
As a rule of thumb, domain experts are either the people coming up with requirements or the software’s end users. The software is supposed to solve their problems.
Chapter 2. Discovering Domain Knowledge
What Is a Ubiquitous Language?
Using a ubiquitous language is the cornerstone practice of domain-driven design. The idea is simple and straightforward: if parties need to communicate efficiently, instead of relying on translations, they have to speak the same language.
Language of the Business
It’s crucial to emphasize that the ubiquitous language is the language of the business. As such, it should consist of business domain–related terms only. No technical jargon!
Model of the Business Domain
What Is a Model?
A model is a simplified representation of a thing or phenomenon that intentionally emphasizes certain aspects while ignoring others. Abstraction with a specific use in mind.
– Rebecca Wirfs-Brock
Effective Modeling
… a useful model is not a copy of the real world. Instead, a model is intended to solve a problem, and it should provide just enough information for that purpose.
Tools
“Individuals and interactions over processes and tools.”
Conclusion
Tools such as wiki-based glossaries and Gherkin tests can greatly alleviate the process of documenting and maintaining a ubiquitous language. However, the main prerequisite for an effective ubiquitous language is usage: the language has to be used consistently in all project-related communications.
Chapter 3. Managing Domain Complexity
What Is a Bounded Context?
The solution in domain-driven design is trivial: divide the ubiquitous language into multiple smaller languages, then assign each one to the explicit context in which it can be applied: its bounded context.
Model Boundaries
A model cannot exist without a boundary; it will expand to become a copy of the real world. That makes defining a model’s boundary—its bounded contexts—an intrinsic part of the modeling process.
A language’s terminology, principles, and business rules are only consistent inside its bounded context.
Bounded Contexts Versus Subdomains
The Interplay Between Subdomains and Bounded Contexts
It’s crucial to remember that subdomains are discovered and bounded contexts are designed. The subdomains are defined by the business strategy. However, we can design the software solution and its bounded contexts to address the specific project’s context and constraints.
Boundaries
As Ruth Malan says, architectural design is inherently about boundaries:
Architectural design is system design. System design is contextual design—it is inherently about boundaries (what’s in, what’s out, what spans, what moves between), and about trade-offs. It reshapes what is outside, just as it shapes what is inside.
Physical Boundaries
As we discussed earlier, a bounded context can contain multiple subdomains. In such a case, the bounded context is a physical boundary, while each of its subdomains is a logical boundary. Logical boundaries bear different names in different programming languages: namespaces, modules, or packages.
Ownership Boundaries
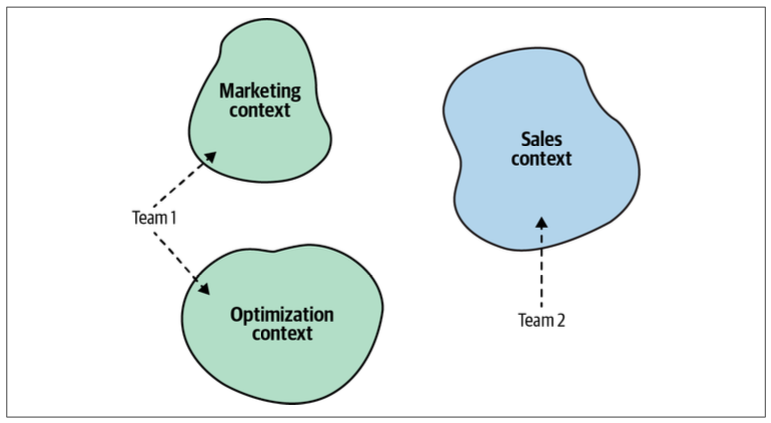
A bounded context should be implemented, evolved, and maintained by one team only. No two teams can work on the same bounded context.
It’s important to note that the relationship between teams and bounded contexts is one-directional: a bounded context should be owned by only one team. However, a single team can own multiple bounded contexts, as Figure 3-8 illustrates.
Chapter 4. Integrating Bounded Contexts
Moreover, models in different bounded contexts can be evolved and implemented independently. That said, bounded contexts themselves are not independent. Just as a system cannot be built out of independent components—the components have to interact with one another to achieve the system’s overarching goals—so, too, do the implementations in bounded contexts. Although they can evolve independently, they have to integrate with one another. As a result, there will always be touchpoints between bounded contexts. These are called contracts.
Cooperation
… two DDD patterns suitable for cooperating teams: the partnership and shared kernel patterns.
Partnership
The coordination of integration here is two-way.
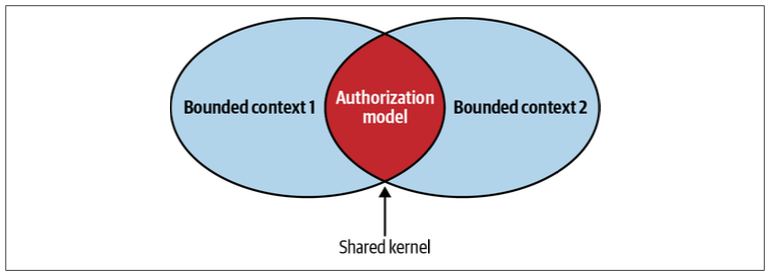
Shared Kernel
Despite bounded contexts being model boundaries, there still can be cases when the same model of a subdomain, or a part of it, will be implemented in multiple bounded contexts.
Customer–Supplier
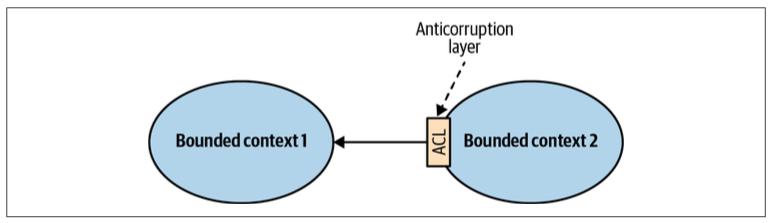
Anticorruption Layer
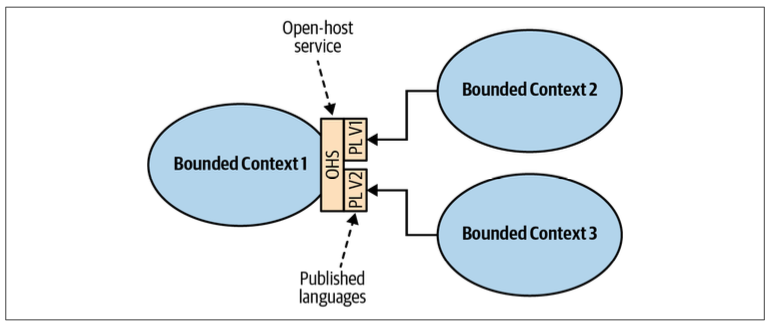
Open-Host Service
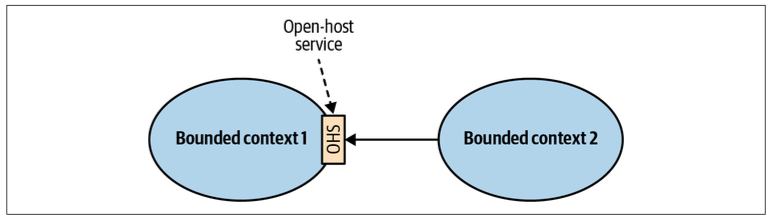
The supplier’s public interface is not intended to conform to its ubiquitous language. Instead, it is intended to expose a protocol convenient for the consumers, expressed in an integration-oriented language. As such, the public protocol is called the published language.
In a sense, the open-host service pattern is a reversal of the anticorruption layer pattern: instead of the consumer, the supplier implements the translation of its internal model.
Separate Ways
Model Differences
The separate ways pattern should be avoided when integrating core subdomains. Duplicating the implementation of such subdomains would defy the company’s strategy to implement them in the most effective and optimized way.
Context Map
Maintenance
A context map can be managed and maintained as code, using a tool like Context Mapper.
Conclusion
Bounded contexts are not independent. They have to interact with one another. The following patterns define different ways bounded contexts can be integrated:
Partnership
Bounded contexts are integrated in an ad hoc manner.
Shared kernel
Two or more bounded contexts are integrated by sharing a limited overlapping model that belongs to all participating bounded contexts.
Conformist
The consumer conforms to the service provider’s model.
Anticorruption layer
The consumer translates the service provider’s model into a model that fits the consumer’s needs.
Open-host service
The service provider implements a published language—a model optimized for its consumers’ needs.
Separate ways
It’s less expensive to duplicate particular functionality than to collaborate and integrate it.
Part II. Tactical Design
Chapter 5. Implementing Simple Business Logic
Active Record
An object that wraps a row in a database table or view, encapsulates the database access, and adds domain logic on that data.
– Martin Fowler
When to Use Active Record
The active record pattern is also known as an anemic domain model antipattern; in other words, an improperly designed domain model. I prefer to restrain from the negative connotation of the words anemic and antipattern. This pattern is a tool. Like any tool, it can solve problems, but it can potentially introduce more harm than good when applied in the wrong context. There is nothing wrong with using active records when the business logic is simple. Furthermore, using a more elaborate pattern when implementing simple business logic will also result in harm by introducing accidental complexity. In the next chapter, you will learn what a domain model is and how it differs from an active record pattern.
Conclusion
Transaction script
This pattern organizes the system’s operations as simple, straightforward procedural scripts. The procedures ensure that each operation is transactional—either it succeeds or it fails. The transaction script pattern lends itself to supporting subdomains, with business logic resembling simple, ETL-like operations.
Active record
When the business logic is simple but operates on complicated data structures, you can implement those data structures as active records. An active record object is a data structure that provides simple CRUD data access methods.
Chapter 6. Tackling Complex Business Logic
Domain Model
Building Blocks
Value object
A value object is an object that can be identified by the composition of its values.
… value objects eliminate the need for conventions —- for example, the need to keep in mind that this string is an email and the other string is a phone number —- and instead makes using the object model less error prone and more intuitive.
Since a change to any of the fields of a value object results in a different value, value objects are implemented as immutable objects.
When to use value objects. The simple answer is, whenever you can. Not only do value objects make the code more expressive and encapsulate business logic that tends to spread apart, but the pattern makes the code safer. Since value objects are immutable, the value objects’ behavior is free of side effects and is thread safe.
From a business domain perspective, a useful rule of thumb is to use value objects for the domain’s elements that describe properties of other objects.
The examples you saw earlier used value objects to describe a person, including their ID, name, phone numbers, email, and so on.
An especially important opportunity to introduce a value object is when modeling money and other monetary values. Relying on primitive types to represent money not only limits your ability to encapsulate all money-related business logic in one place, but also often leads to dangerous bugs, such as rounding errors and other precision-related issues.
Entities
An entity is the opposite of a value object. It requires an explicit identification field to distinguish between the different instances of the entity.
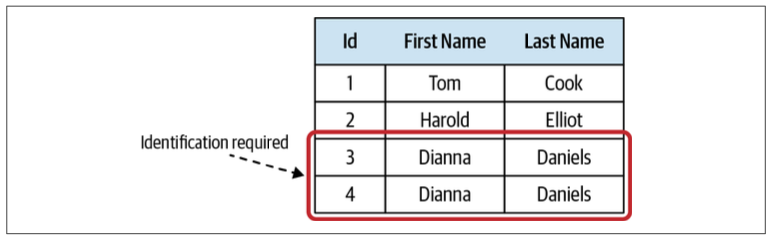
Contrary to value objects, entities are not immutable and are expected to change. Another difference between entities and value objects is that value objects describe an entity’s properties.
Entities are an essential building block of any business domain.
… we don’t implement entities independently, but only in the context of the aggregate pattern.
Aggregates
An aggregate is an entity: it requires an explicit identification field and its state is expected to change during an instance’s lifecycle. However, it is much more than just an entity. The goal of the pattern is to protect the consistency of its data. Since an aggregate’s data is mutable, there are implications and challenges that the pattern has to address to keep its state consistent at all times.
An aggregate’s public interface is responsible for validating the input and enforcing all of the relevant business rules and invariants. This strict boundary also ensures that all business logic related to the aggregate is implemented in one place: the aggregate itself.
A change to an aggregate’s state can only be committed individually, one aggregate per database transaction.
To support changes to multiple objects that have to be applied in one atomic transaction, the aggregate pattern resembles a hierarchy of entities, all sharing transactional consistency
That’s why the pattern is named “aggregate”: it aggregates business entities and value objects that belong to the same transaction boundary.
Only the information that is required by the aggregate’s business logic to be strongly consistent should be a part of the aggregate. All information that can be eventually consistent should reside outside of the aggregate’s boundary;
The rule of thumb is to keep the aggregates as small as possible and include only objects that are required to be in a strongly consistent state by the aggregate’s business logic
To decide whether an entity belongs to an aggregate or not, examine whether the aggregate contains business logic that can lead to an invalid system state if it will work on eventually consistent data.
In addition to the aggregate root’s public interface, there is another mechanism through which the outer world can communicate with aggregates: domain events.
Domain events are part of an aggregate’s public interface. An aggregate publishes its domain events. Other processes, aggregates, or even external systems can subscribe to and execute their own logic in response to the domain events
Domain services
Sooner or later, you may encounter business logic that either doesn’t belong to any aggregate or value object, or that seems to be relevant to multiple aggregates. In such cases, domain-driven design proposes to implement the logic as a domain service.
A domain service is a stateless object that implements the business logic.
Managing Complexity
… when discussing the complexity of a system we are interested in evaluating the difficulty of controlling and predicting the system’s behavior. These two aspects are reflected by the system’s degrees of freedom.
That’s what both aggregate and value object patterns do: encapsulate invariants and thus reduce complexity.
All the business logic related to the state of a value object is located in its boundaries. The same is true for aggregates. An aggregate can only be modified by its own methods. Its business logic encapsulates and protects business invariants, thus reducing the degrees of freedom.
Since the domain model pattern is applied only for subdomains with complex business logic, it’s safe to assume that these are core subdomains—the heart of the software.
Conclusion
The domain model pattern is aimed at cases of complex business logic. It consists of three main building blocks:
Value objects
Concepts of the business domain that can be identified exclusively by their values and thus do not require an explicit ID field. Since a change in one of the fields semantically creates a new value, value objects are immutable.
Value objects model not only data, but behavior as well: methods manipulating the values and thus initializing new value objects.
Aggregates
A hierarchy of entities sharing a transactional boundary. All of the data included in an aggregate’s boundary has to be strongly consistent to implement its business logic.
The state of the aggregate, and its internal objects, can only be modified through its public interface, by executing the aggregate’s commands. The data fields are read-only for external components for the sake of ensuring that all the business logic related to the aggregate resides in its boundaries.
The aggregate acts as a transactional boundary. All of its data, including all of its internal objects, has to be committed to the database as one atomic transaction.
An aggregate can communicate with external entities by publishing domain events—messages describing important business events in the aggregate’s lifecycle. Other components can subscribe to the events and use them to trigger the execution of business logic.
Domain services
A stateless object that hosts business logic that naturally doesn’t belong to any of the domain model’s aggregates or value objects.
Chapter 7. Modeling the Dimension of Time
Event Sourcing
The event sourcing pattern introduces the dimension of time into the data model. Instead of the schema reflecting the aggregates’ current state, an event sourcing– based system persists events documenting every change in an aggregate’s lifecycle.
Event Store
The event store should not allow modifying or deleting the events2 since it’s append-only storage.
Chapter 8. Architectural Patterns
Layered Architecture
Layered architecture is one of the most common architectural patterns. It organizes the codebase into horizontal layers, with each layer addressing one of the following technical concerns: interaction with the consumers, implementing business logic, and persisting the data.
Business Logic Layer
This layer is where the business logic patterns described in Chapters 5–7 are implemented—for example, active records or a domain model
Variation
… the service layer is required if the business logic pattern requires external orchestration, as in the case of the active record pattern. In this case, the service layer implements the transaction script pattern, while the active records it oper‐ ates on are located in the business logic layer.
When to Use Layered Architecture
However, the pattern makes it challenging to implement a domain model. In a domain model, the business entities (aggregates and value objects) should have no dependency and no knowledge of the underlying infrastructure. The layered architec‐ ture’s top-down dependency requires jumping through some hoops to fulfill this requirement. It is still possible to implement a domain model in a layered architec‐ ture, but the pattern we will discuss next fits much better.
… a layer is a logical boundary, whereas a tier is a physical boundary. All layers in the layered architecture are bound by the same lifecycle
On the other hand, a tier is an independ‐ ently deployable service, server, or system. For example, consider the N-Tier system in Figure 8-7.

However, since each component can be deployed and managed independent of the rest, these are tiers and not layers.
Layers, on the other hand, are logical boundaries inside the web application.
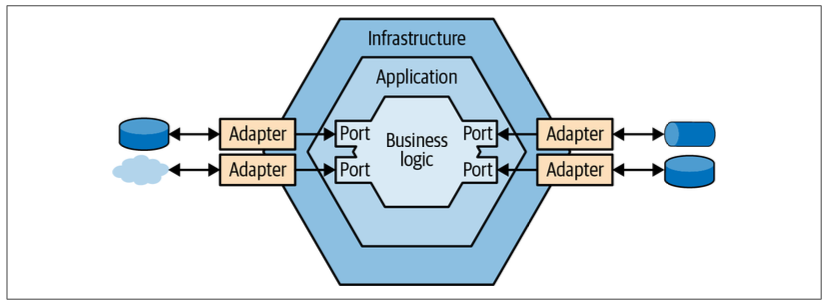
Ports & Adapters
Integration of Infrastructural Components
The core goal of the ports & adapters architecture is to decouple the system’s business logic from its infrastructural components.
Instead of referencing and calling the infrastructural components directly, the business logic layer defines “ports” that have to be implemented by the infrastructure layer. The infrastructure layer implements “adapters”: concrete implementations of the ports’ interfaces for working with different technologies (see Figure 8-11).
Variants
The ports & adapters architecture is also known as hexagonal architecture, onion architecture, and clean architecture.
Command-Query Responsibility Segregation
Implementation
CQRS devotes a single model to executing operations that modify the system’s state (system commands).
The system can define as many models as needed to present data to users or supply information to other systems.
Projecting Read Models
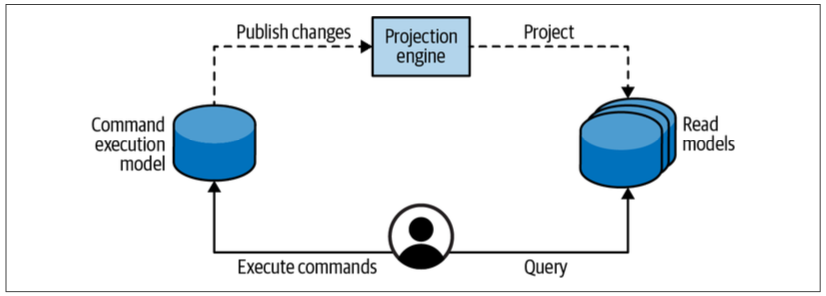
Model Segregation
A common misconception about CQRS-based systems is that a command can only modify data, and data can be fetched for display only through a read model. In other words, the command executing the methods should never return any data. This is wrong. This approach produces accidental complexities and leads to a bad user experience.
Therefore, a command can—and in many cases should—return data;
The only limitation here is that the returned data should originate from the strongly consistent model—the command execution model—as we cannot expect the projections, which will eventually be consistent, to be refreshed immediately.
When to Use CQRS
The CQRS pattern can be useful for applications that need to work with the same data in multiple models, potentially stored in different kinds of databases.
Scope
Conclusion
The layered architecture decomposes the codebase based on its technological concerns. Since this pattern couples business logic with data access implementation, it’s a good fit for active record–based systems.
The ports & adapters architecture inverts the relationships: it puts the business logic at the center and decouples it from all infrastructural dependencies. This pattern is a good fit for business logic implemented with the domain model pattern.
The CQRS pattern represents the same data in multiple models. Although this pattern is obligatory for systems based on the event-sourced domain model, it can also be used in any systems that need a way of working with multiple persistent models.
Chapter 9. Communication Patterns
Model Translation
Stateful Model Translation
In some use cases, you can avoid implementing a custom solution for a stateful translation by using off-the-shelf products; for example, a stream-process platform (Kafka, AWS Kinesis, etc.), or a batching solution (Apache NiFi, AWS Glue, Spark, etc.).
Integrating Aggregates
Outbox
The outbox pattern (Figure 9-11) ensures reliable publishing of domain events using the following algorithm:
- Both the updated aggregate’s state and the new domain events are committed in the same atomic transaction.
- A message relay fetches newly committed domain events from the database.
- The relay publishes the domain events to the message bus.
- Upon successful publishing, the relay either marks the events as published in the database or deletes them completely.
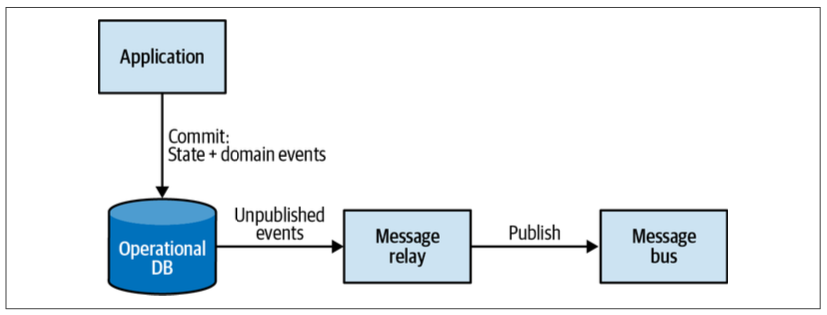
When using a relational database, it’s convenient to leverage the database’s ability to commit to two tables atomically and use a dedicated table for storing the messages
When using a NoSQL database that doesn’t support multidocument transactions, the outgoing domain events have to be embedded in the aggregate’s record.
Saga
A saga is a long-running business process. It’s long running not necessarily in terms of time, as sagas can run from seconds to years, but rather in terms of transactions: a business process that spans multiple transactions. The transactions can be handled not only by aggregates but by any component emitting domain events and responding to commands. The saga listens to the events emitted by the relevant components and issues subsequent commands to the other components. If one of the execution steps fails, the saga is in charge of issuing relevant compensating actions to ensure the system state remains consistent.
Process Manager
The saga pattern manages simple, linear flow. Strictly speaking, a saga matches events to the corresponding commands.
The process manager pattern, shown in Figure 9-14, is intended to implement a business-logic-based process. It is defined as a central processing unit that maintains the state of the sequence and determines the next processing steps.
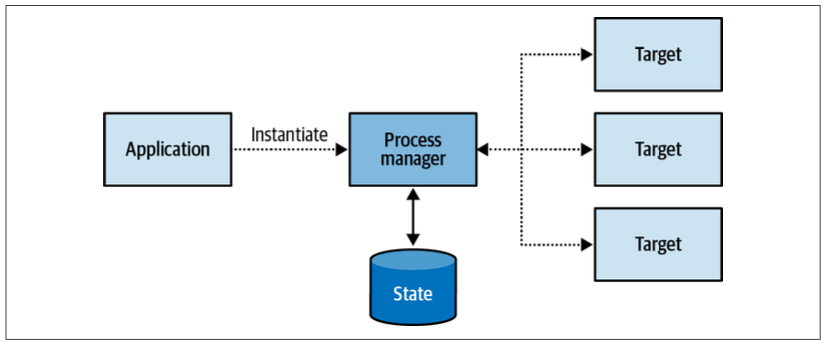
As a simple rule of thumb, if a saga contains if-else statements to choose the correct course of action, it is probably a process manager.
Another difference between a process manager and a saga is that a saga is instantiated implicitly when a particular event is observed
A process manager, on the other hand, cannot be bound to a single source event. Instead, it’s a coherent business process consisting of multiple steps. Hence, a process manager has to be instantiated explicitly.
Part III. Applying Domain-Driven Design in Practice
Chapter 10. Design Heuristics
Bounded Contexts
Broad bounded context boundaries, or those that encompass multiple subdomains, make it safer to be wrong about the boundaries or the models of the included subdomains. Refactoring logical boundaries is considerably less expensive than refactoring physical boundaries. Hence, when designing bounded contexts, start with wider boundaries. If required, decompose the wide boundaries into smaller ones as you gain domain knowledge.
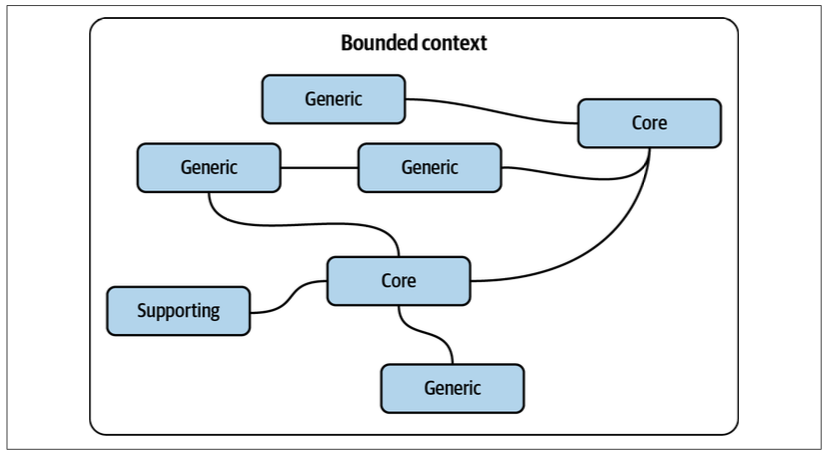
When creating a bounded context that contains a core subdomain, you can protect yourself against unforeseen changes by including other subdomains that the core subdomain interacts with most often. This can be other core subdomains, or even supporting and generic subdomains, as shown in Figure 10-2.
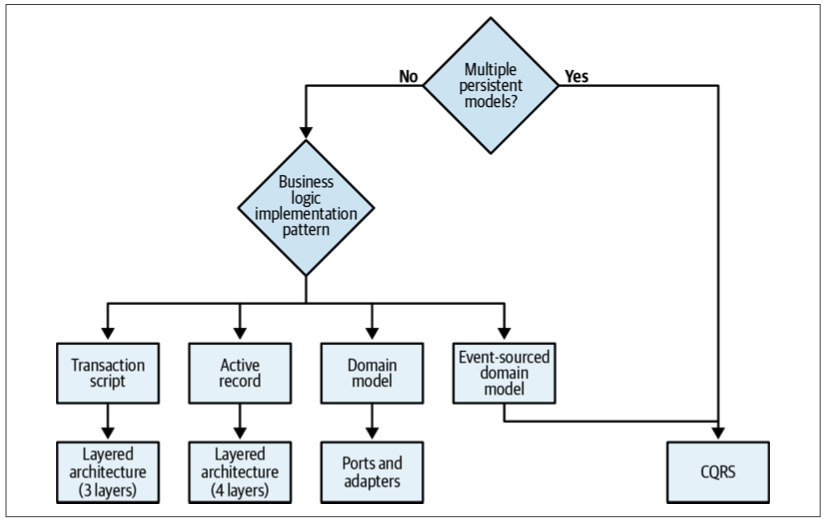
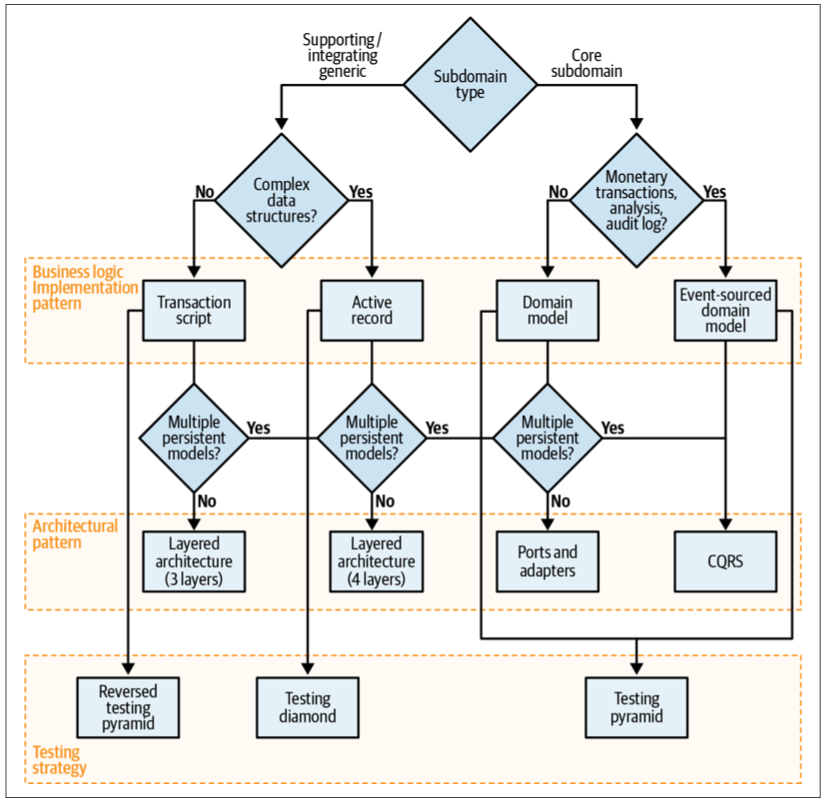
Business Logic Implementation Patterns
With all of this in mind, an effective heuristic for choosing the appropriate business logic implementation pattern is to ask the following questions:
- Does the subdomain track money or other monetary transactions or have to provide a consistent audit log, or is deep analysis of its behavior required by the business? If so, use the event-sourced domain model. Otherwise…
- Is the subdomain’s business logic complex? If so, implement a domain model. Otherwise…
- Does the subdomain include complex data structures? If so, use the active record pattern. Otherwise…
- Implement a transaction script.

Deciding on the business logic implementation pattern according to the complexity of the business logic and its data structures is a way to validate your assumptions about the subdomain type. Suppose you consider it to be a core subdomain, but the best pattern is active record or transaction script. Or suppose what you believe is a supporting subdomain requires a domain model or an event-sourced domain model; in this case, it’s an excellent opportunity to revisit your assumptions about the subdomain and business domain in general. Remember, a core subdomain’s competitive advantage is not necessarily technical.
Architectural Patterns
Knowing the intended business logic implementation pattern makes choosing an architectural pattern straightforward:
- The event-sourced domain model requires CQRS. Otherwise, the system will be extremely limited in its data querying options, fetching a single instance by its ID only.
- The domain model requires the ports & adapters architecture. Otherwise, the layered architecture makes it hard to make aggregates and value objects ignorant of persistence.
- The Active record pattern is best accompanied by a layered architecture with the additional application (service) layer. This is for the logic controlling the active records.
- The transaction script pattern can be implemented with a minimal layered architecture, consisting of only three layers.
The only exception to the preceding heuristics is the CQRS pattern. CQRS can be beneficial not only for the event-sourced domain model, but also for any other pattern if the subdomain requires representing its data in multiple persistent models.
Testing Strategy
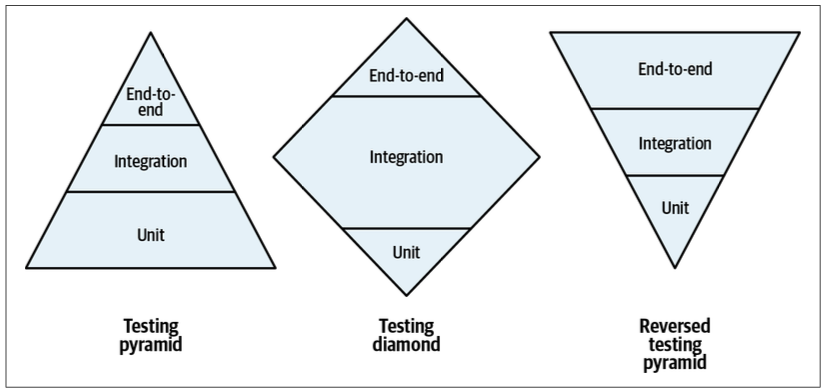
Reversed Testing Pyramid
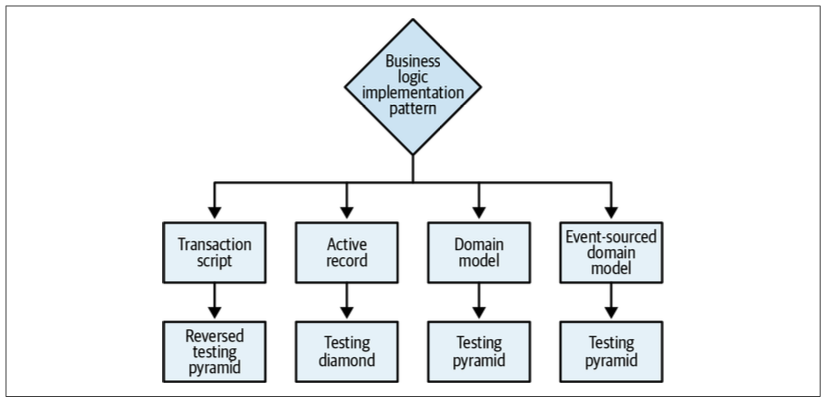
Tactical Design Decision Tree
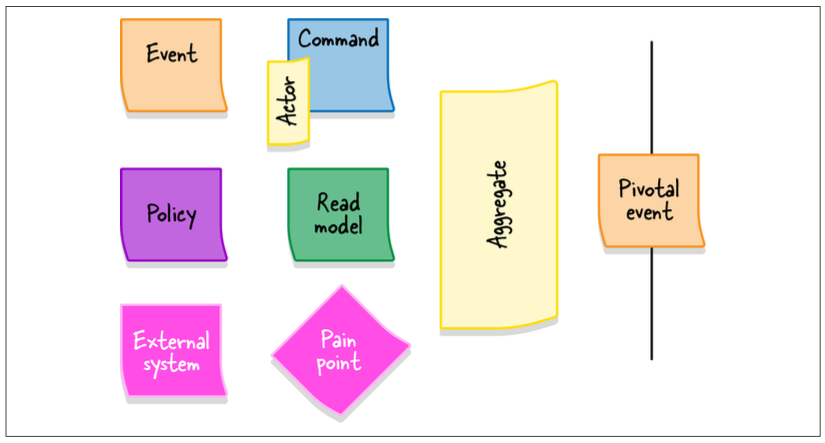
Chapter 12. EventStorming
What Is EventStorming?
In a sense, EventStorming is a tactical tool for sharing business domain knowledge.
The EventStorming Process
An EventStorming workshop is usually conducted in 10 steps. During each step, the model is enriched with additional information and concepts.
Step 1: Unstructured Exploration
Step 2: Timelines
Step 3: Pain Points
Step 4: Pivotal Events
Pivotal events are an indicator of potential bounded context boundaries.
Step 5: Commands
Step 6: Policies
Step 7: Read Models
Step 8: External Systems
Step 9: Aggregates
Step 10: Bounded Contexts
Variants
At the end of a full EventStorming session, you will have a model describing the business domain’s events, commands, aggregates, and even possible bounded contexts. However, all of these are just nice bonuses. The real value of an EventStorming session is the process itself—the sharing of knowledge among different stakeholders, alignment of their mental models of the business, discovery of conflicting models, and, last but not least, formulation of the ubiquitous language.
Facilitation Tips
Chapter 13. Domain-Driven Design in the Real World
Pragmatic Domain-Driven Design
It’s worth reiterating that domain-driven design is not about aggregates or value objects. Domain-driven design is about letting your business domain drive software design decisions.
Part IV. Relationships to Other Methodologies and Patterns
Chapter 14. Microservices
What Is a Microservice?
System Complexity
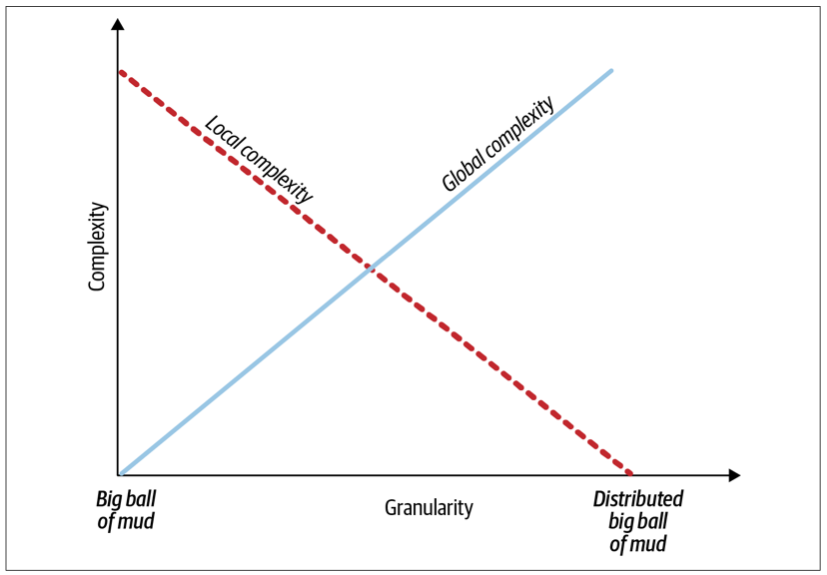
To design a proper microservices-based system, we have to optimize both global and local complexities.
Conclusion
All microservices are bounded contexts, but not all bounded contexts are necessarily microservices. In its essence, a microservice defines the smallest valid boundary of a service, while a bounded context protects the consistency of the encompassed model and represents the widest valid boundaries. Defining boundaries to be wider than their bounded contexts will result in a big ball of mud, while boundaries that are smaller than microservices will lead to a distributed big ball of mud.
Chapter 15. Event-Driven Architecture
Event-Driven Architecture
Although both event-driven architecture and event sourcing are based on events, the two patterns are conceptually different. EDA refers to the communication between services, while event sourcing happens inside a service.
Events
Events, Commands, and Messages
There are two types of messages:
Event
A message describing a change that has already happened
Command
A message describing an operation that has to be carried out
An event is something that has already happened, whereas a command is an instruction to do something. Both events and commands can be communicated asynchronously as messages. However, a command can be rejected: the command’s target can refuse to execute the command, for example, if the command is invalid or if it contradicts the system’s business rules. A recipient of an event, on the other hand, cannot cancel the event. The event describes something that has already happened. The only thing that can be done to overturn an event is to issue a compensating action—a command, as it’s carried out in the saga pattern.
Types of Events
Events can be categorized into one of three types:2 event notification, event-carried state transfer, or domain events.
Event-carried state transfer (ECST) messages notify subscribers about changes in the producer’s internal state. Contrary to event notification messages, ECST messages include all the data reflecting the change in the state.
Conceptually, using event-carried state transfer messages is an asynchronous data replication mechanism.
Designing Event-Driven Integration
… software design is predominantly about boundaries. Boundaries define what belongs inside, what remains outside, and most importantly, what goes across the boundaries—essentially, how the components are integrated with one another.
Event-Driven Design Heuristics
Use this as a guiding principle when designing event-driven systems:
- The network is going to be slow.
- Servers will fail at the most inconvenient moment.
- Events will arrive out of order.
- Events will be duplicated.
Ensure that the events are always delivered consistently, no matter what:
- Use the outbox pattern to publish messages reliably.
- When publishing messages, ensure that the subscribers will be able to deduplicate the messages and identify and reorder out-of-order messages.
- Leverage the saga and process manager patterns when orchestrating cross- bounded context processes that require issuing compensating actions.
Chapter 16. Data Mesh
Analytical Data Model Versus Transactional Data Model
Dimension Table
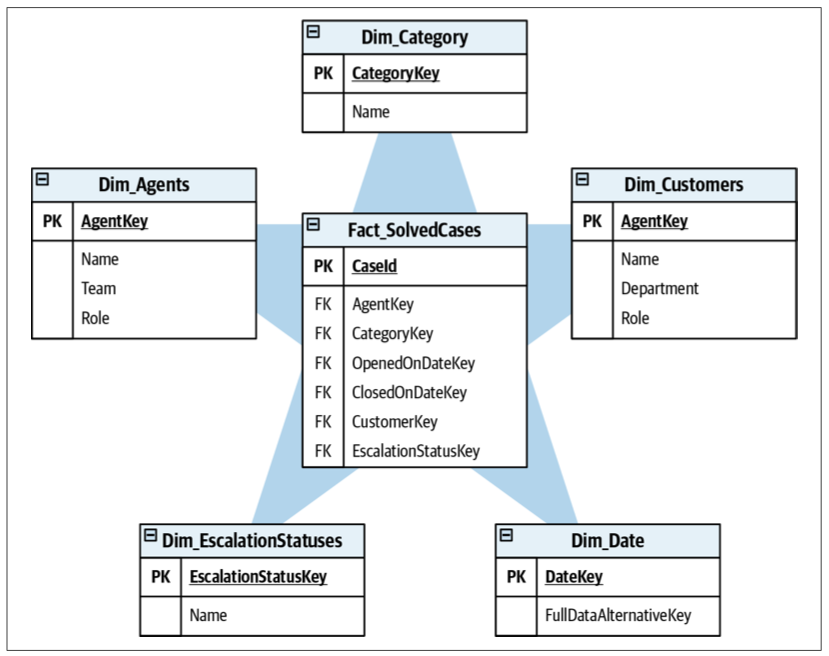
Analytical Models
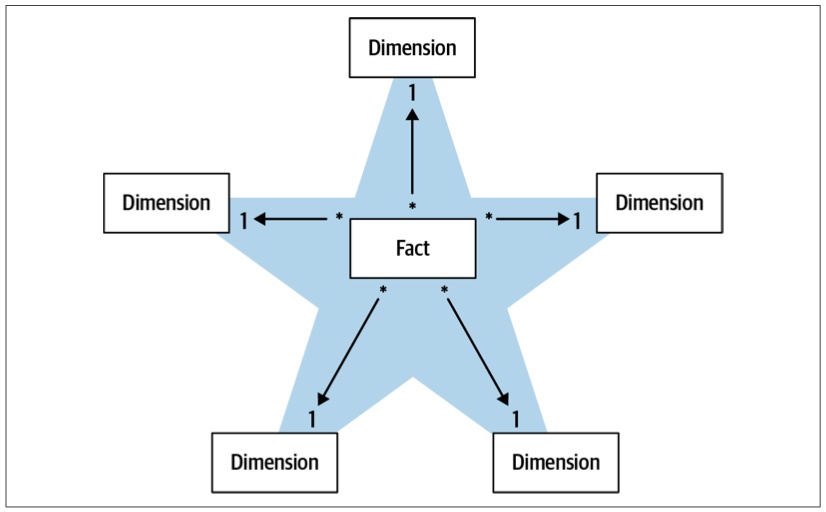
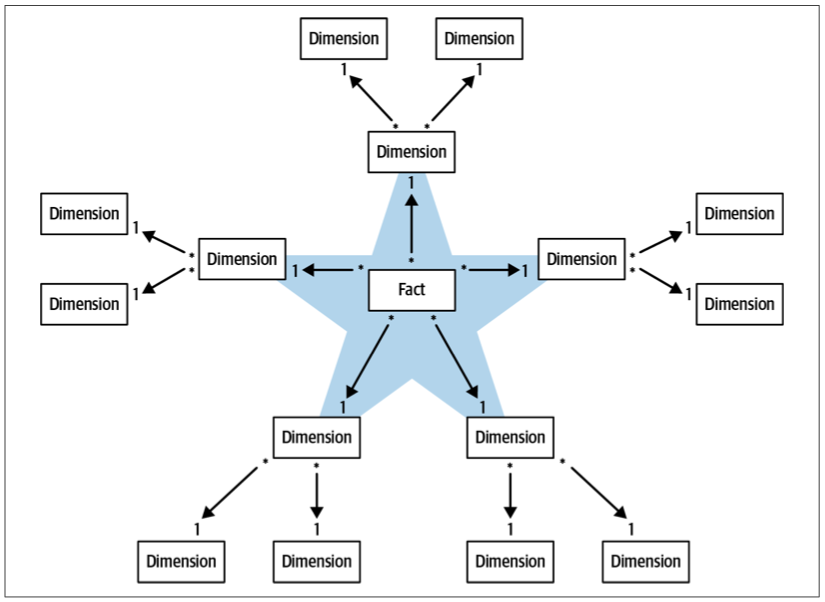
Analytical Data Management Platforms
Data Warehouse
A data mart is a database that holds data relevant for well-defined analytical needs, such as analysis of a single business department.
Data Lake
A data lake–based system ingests the operational systems’ data. However, instead of being transformed right away into an analytical model, the data is persisted in its raw form, that is, in the original operational model.
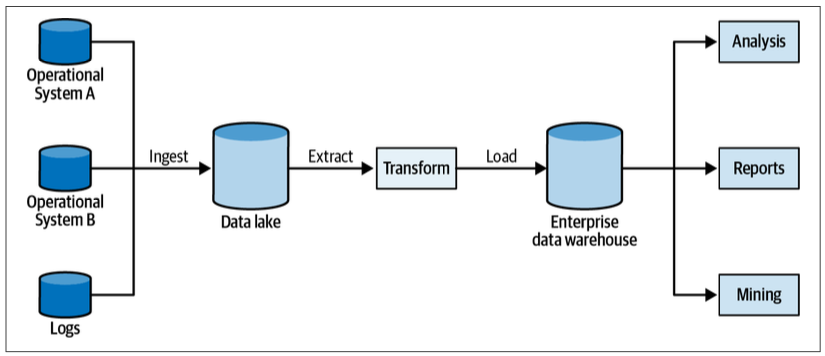
Data lakes make it easy to ingest data but much more challenging to make use of it. Or, as is often said, a data lake becomes a data swamp.
Data Mesh
The data mesh architecture is based on four core principles: decompose data around domains, data as a product, enable autonomy, and build an ecosystem. Let’s discuss each principle in detail.
Decompose Data Around Domains
Instead of building a monolithic analytical model, the data mesh architecture … use multiple analytical models and align them with the origin of the data.
… the same team owns the operational model, now in charge of transforming it into the analytical model.
Data as a Product
Contrary to the data warehouse and data lake architectures, with data mesh, accountability for data quality is a top- level concern.
Combining Data Mesh and Domain-Driven Design
These are the four principles that the data mesh architecture is based on. The emphasis on defining boundaries, and encapsulating the implementation details behind well-defined output ports, makes it evident that the data mesh architecture is based on the same reasoning as domain-driven design.
Appendix A. Applying DDD: A Case Study
Discussion
Ubiquitous Language
In my experience, ubiquitous language is the “core subdomain” of domain-driven design.
… ubiquitous language is not optional, regardless of whether you’re working on a core, supporting, or generic subdomain.

目录
- 1. Introduction
- 2. Part I. Strategic Design
- 3. Part II. Tactical Design
- 4. Part III. Applying Domain-Driven Design in Practice
- 5. Part IV. Relationships to Other Methodologies and Patterns
- 6. Appendix A. Applying DDD: A Case Study